目录
下面我们统一把:「固定风格任意内容的快速风格迁移算法」称为v2算法,「固定风格固定内容的快速迁移算法」称为v1算法。具体可以看看 参考资料 里面的 风格迁移三部曲。
一、目标:求出一个某种固定风格图像转换网络
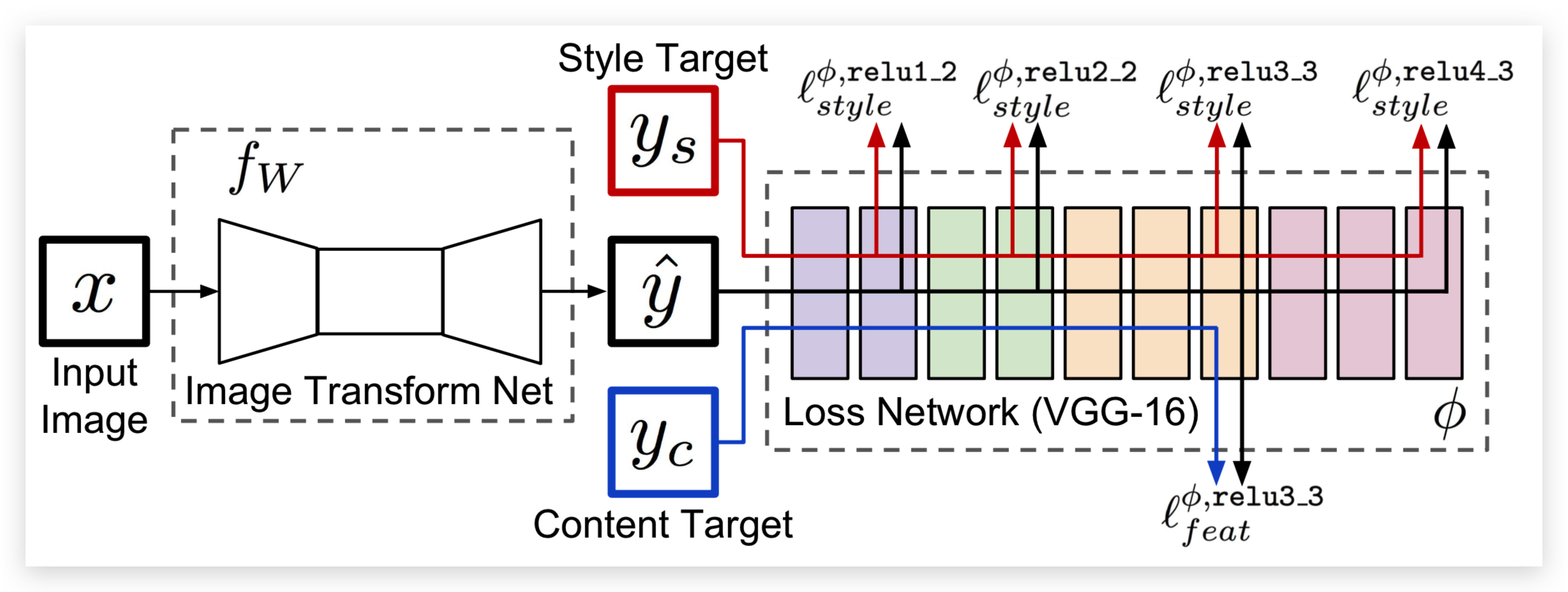
- fw是 v2 算法的结果,通过这个v2算法,可以求解出一个图像转换的网络,这个网络可以让我们在预测的时候,输入任何一个图像,然后经过Image Transform Net的正向传播,就可以得到图像转换后的结果,y-hat,这个是v2算法得到的结果。
- 那么这个网络是如何去train的呢?
- 首先,依然是利用预训练好的VGG16的预训练卷积网络,x是输入的原图像(内容图像),内容图像经过Image Transform Net之后,会得到一个输出,跟内容图像是一个同等大小的输出y-hat
- y-hat对应的就是在v1算法中的结果图像,结果图像输入到VGG16中去,同时将内容图像yc 和风格图像 ys,输入到网络中去,然后去计算损失函数,在v1算法中,是没有x输入到Image Transform Net这部分,只是随机初始化一个y,然后进行训练,在v2算法中,y并不是随机初始化的,而是由我把内容图像输入到Image Transform Net中去,然后去得到的这个y,所以对这个y进行训练,就相当于是训练 Image Transorm Net这个网络,而不是去train这个y了。
这就是图像风格转换的v2算法。
二、对比一下:v1算法和v2算法的区别在哪里?
- 核心区别就是这个y-hat的来源,在v1算法中,这个y-hat是随机初始化的,而在v2算法中,这个y-hat是经过转换网络经过转换得到的,所以在v2算法中,这个y-hat相当于转换网络的一个函数。然后对y进行求导,也就是去调整一下这个网络,从而学到一种,专门针对某种图像的风格转换网络。
- 在v2这个训练过程中呢?我们只能是一次给一个风格去train一个网络,也就是这个Image Transform Net对应的是一种风格,在训练当中,保持风格图像不变,可以去切换内容图像,也可以不切换,然后去train这个网络,然后就得到了针对这个风格的transform Net。
- 计算损失函数的时候,都是通过训练好的VGG16去提取它的内容特征和风格特征,然后去做其它的损失函数,内容损失和风格损失都是加权平均得到的。
- 在固定风格固定内容的图像风格迁移里面的话,输入VGG网络的这个y-hat直接随机初始化得到的,是没有 Image Transform Net这个网络的,那么在这里加入了这个 Image Transform Net网络,那么后面在预测的时候,就直接输入内容图像x,经过 Image Transform Net这个网络就会被转换得到风格迁移后的图像,预测的时候,就不用再经过VGG16,像固定风格固定内容的图像风格迁移,没有这个 Image Transform Net网络,就还得去初始化、经过VGG网络,多次运行梯度下降的方法,这样就会使得整体的效率非常低,相比之下这里进行预测只需要计算一次就可以了,所以会更加节省资源。
三、参数
训练:
- x是要转换的图像
- ys是风格图像
- yc是内容图像
- x=yc
预测:
- 输入新图像
- 经过transformer
- 得到转换结果
将x输入到中间 Image Transform Net这个网络中,得到y-hat,y-hat再输入到训练好的VGG网络中去,去提取它的内容特征和风格特征,然后去做其它的损失函数,内容损失和风格损失都是加权平均得到的。
四、v2算法的优点
- 因为你转来转去,都是只要转固定一张图片的风格,那就直接把这张图片的风格给保存下来就行(用Image Transform Net去保存风格),下次直接扔进去转换就行,这样多方便。
五、图像风格转换算法的扩展性
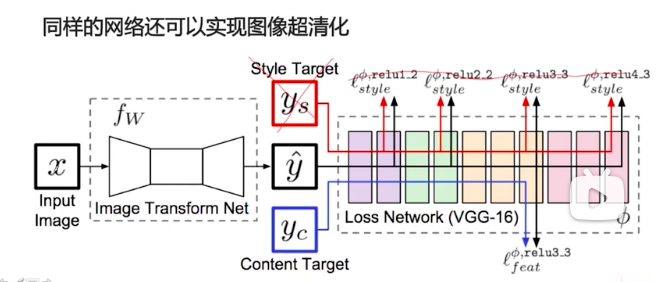
同样的网络,稍微变动一下,还可以做图像超清化,因为是图像超清化,所以把ys给去掉,也没有风格损失,x可以是低分辨率的图像,yc是高分辨率的图像,x输入到Image Transform Net中去,假设它能够学习到从低分辨率图像到高分辨率图像的映射,这个映射就是y-hat,同样把y-hat和yc输入到VGG16中去,去计算损失函数,这样经过很多组,这里y和yc是一对图像,低分辨率图像和高分辨率图像,可以输入很多不同的低分辨率图像,和对应的高分辨率图像,训练之后,就可以train出来一个Image Transform Net转换器,这样,同样的一个网络,稍微地做了一下改动,就可以用在其它的任务上。
六、网络细节(该算法的特点)
- 不使用pooling层,使用strided 和 fractionally strided卷积来做downsampling 和 upsampling。
- strided就是说卷积的步长为1的时候,图像输入和输出的sized是不会发生成倍的变化的
- 当strided=2的时候,那么也会发生那种图像sized长宽各占一半的效果,而这种在卷积层上的效果,比pooling层能够保存更多的信息,所以对于这样一个图像生成网络来说,一般会使用strided=2的卷积层来代替pooling层,从而可以保存更多的信息,然后因为图像变小了之后,还是要把它放大回来,fractionally strided就相当于是strided的逆操作。
- strided = 2的时候,是下采样,图像会变小,strided = 1/2的时候,是上采样,图像会变大,然后使用卷积会比pooling层保存更多的信息
- 在Image Transform Net中使用了五个residual blocks,也就是残差连接,残差连接在网络结构的那一章已经讲过了,它是一个什么样的结构,在生成问题上使用残差连接,可以有一个好处:残差连接至少是一个恒等连接,比如说:回忆一下残差连接的结构,y = x + f(x),所以说y至少可以等于x,当f(x)=0的时候,所以这样的结构,能够保持输入图像中更多的信息,本来卷积神经网络的卷积,每一层都要保存图像的所有信息,这样才能够使得图像一层一层往下传,传到卷积的后面,不会和图像信息有所消失,那么使用残差连接的时候,天然地就有y = x + f(x),y = x就使得我能够有能力保存所有的图像信息,f(x)就可以从图像中学习更多的信息。
- 那在生成问题中呢,比如说是图像超清化问题,图像的低分辨率图像和高分辨率图像它们相差的信息其实并没有那么多,它们共享的信息有很多,所以高分辨率图像中有许多需要用低分辨率图像中的信息去填充,使用residual blocks能够保存更多的信息,