Hash索引和B+树所有有什么区别或者说优劣呢?
首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树。对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
那么可以看出他们有以下的不同:
- hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
- hash索引不支持使用索引进行排序,原理同上。
- hash索引不支持模糊查询以及多列索引的最左前缀匹配。原理也是因为hash函数的不可预测。AAAA和AAAAB的索引没有相关性。
- hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
- hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
B树和B+树的区别


在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
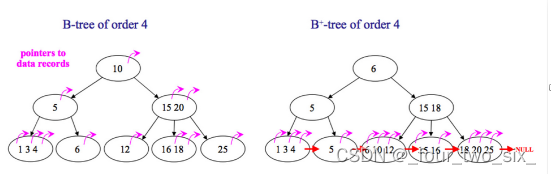
使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间。