文章目录
前言
我们都知道在MySQL中索引的数据结构有两种,一种是Hash,另一种是BTree。在数据表中建立什么样的索引需要我们根据实际情况进行选择。
B+树
B+树结构示意图:
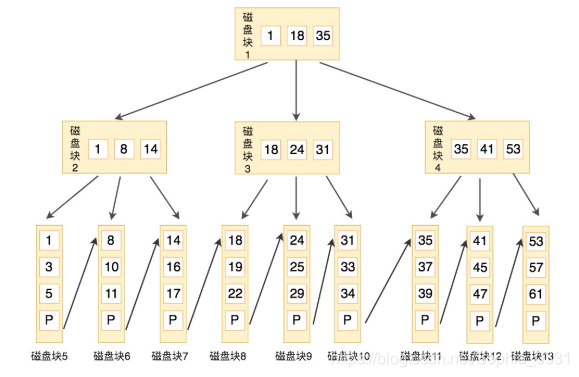
B+树的特征:
1、有K个孩子的节点就有K个关键字。也就是孩子数量=关键字数。
2、非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大或最小。
3、非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。
4、所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
Hash
Hash索引示意图:

键值Key通过Hash映射找到桶bucket。桶指的是一个能存储一条或多条记录的存储单位。一个桶的结构包含了一个内存指针数组,桶中的每行数据都会指向下一行,形成链表结构,当遇到Hash冲突时,会在桶中进行键值的查找。
Hash冲突:
如果桶的空间小于输入的空间,不同的输入可能会映射到同一个桶中,这时就会产生Hash冲突,如果Hash冲突的量很大,就会影响读取性能。
Hash索引与B+树索引的区别
由于Hash索引结构和B+ 树不同,因此在索引使用上也会有差别:
(1)Hash索引不能进行范围查询,而B+树可以。
这是因为Hash索引指向的数据是无序的,而B+ 树的叶子节点是个有序的链表。
(2)Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。
对于联合索引来说,Hash索引在计算Hash值的时候是将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值。因此如果用到联合索引的一个或多个索引时,联合索引无法被利用。
(3)Hash索引不支持Order BY排序,而B+树支持。
因为Hash索引指向的数据是无序的,因此无法起到排序优化的作用,而B+树索引数据是有序的,可以起到对该字段Order By 排序优化的作用。
(4)Hash索引无法进行模糊查询。而B+ 树使用 LIKE 进行模糊查询的时候,LIKE后面前模糊查询(比如%开头)的话可以起到优化的作用。
(5)Hash索引在等值查询上比B+树效率更高。
不过也存在一种情况,就是索引列的重复值如果很多,效率就会降低。这是因为遇到Hash冲突时,需要遍历桶中的行指针来进行比较,找到查询的关键字非常耗时。所以Hash索引通常不会用到重复值多的列上,比如列为性别,年龄等。
总结
从上述描述中我们能看出Hash索引存在着很多限制,相比之下在数据库中B+树索引的使用面会更广。
MySQL在5.5版本以后默认的存储引擎是InnoDB,在InnoDB存储引擎中还有个“自适应Hash索引”的功能,就是当某个索引值使用非常频繁的时候,它会在B+ 树索引的基础上再创建一个Hash索引,就是让B+树也具备了Hash索引的优点。当遇到字段重复度低,而且经常需要进行等值查询的时候,采用Hash索引是个不错的选择。所以选择Hash还是B+树还应该视项目具体情况而定。
本文内容参考极客上的内容,欢迎大家在评论区交流学习~
