EMNIST 数据集是一个包含手写字母,数字的数据集,它具有和MNIST相同的数据格式。The EMNIST Dataset | NIST
- 引用模块介绍:
import tensorflow as tf
import mnist
from tensorflow.keras import datasets, layers, models
import numpy as np
import matplotlib.pyplot as plt
import gzip,os其中要注意的是,tensorflow和keras和numpy的版本一定要对应,如果不对应就无法正常引用,python版本也不能太新,3.6到3.7最佳,如果python版本不满足,可以安装anaconda,在anconda prompt中创建虚拟环境,让其中的python=3.6.5即可
Tensorflow=2.3.1 numpy=1.19.5 keras=2.4.3 这是一种可行的库的版本
2.1首先导入数据集和可视化
路径最好继续用相对路径,这里的路径需要根据自己的文件路径进行修改
emnist数据集可以到官网上下载
def load_mnist(path):
# 放置mnist.py的目录。注意斜杠
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
def mnist_parse_file(fname):
fopen = gzip.open if os.path.splitext(fname)[1] == '.gz' else open
with fopen(fname, 'rb') as fd:
return mnist.parse_idx(fd)
train_images = mnist_parse_file(".\\Dataset\\emnist-letters-train-images-idx3-ubyte.gz")
train_labels = mnist_parse_file(".\\Dataset\\emnist-letters-train-labels-idx1-ubyte.gz")
test_images = mnist_parse_file(".\\Dataset\\emnist-letters-test-images-idx3-ubyte.gz")
test_labels = mnist_parse_file(".\\Dataset\\emnist-letters-test-labels-idx1-ubyte.gz")显示训练集的第6张图片
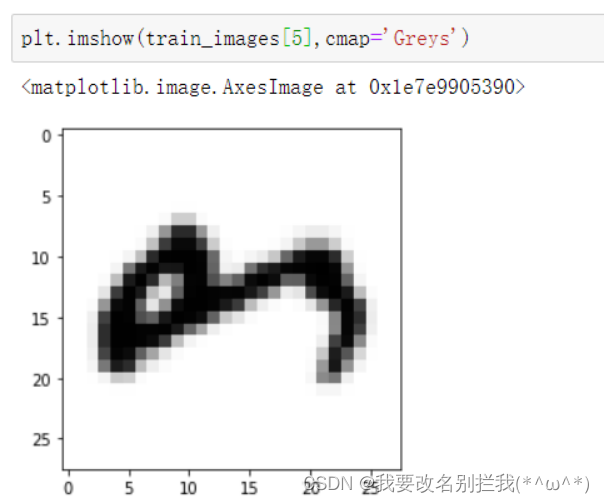
2.2 神经网络模型
首先查看训练集和测试集的大小,为后面的步骤做准备
#查看各集合大小
print(len(train_images),len(train_labels),len(test_images),len(test_labels))
print(test_images[0].shape)
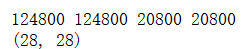
训练集的大小是124800,测试集的大小是20800
接下来进行神经网络模型的构建
# 初始化序列模型 神经网络
model = models.Sequential()
# 一层隐含层,92个神经元
model.add(layers.Dense(92,input_shape=[784]))
#第二层隐含层,92个神经元,激活函数为relu
model.add(layers.Dense(92, activation='relu'))
#第三层隐含层,92个神经元
model.add(layers.Dense(92, activation='relu'))
# 输出层,对应a-z
model.add(layers.Dense(27, activation='softmax'))
#另一种创建model的方法
#model = tf.keras.models.Sequential([
# tf.keras.layers.Dense(128, input_shape=[784]),
# tf.keras.layers.Dense(40, activation='relu'),
# tf.keras.layers.Dense(10, activation='softmax')
#])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary() 
这里需要注意的是一个问题,如何确定神经网络的隐含层数以及每层的神经元数目?
这里附上一个在stackoverflow上看到的经验公式:

经过计算,神经元的数目最好不要超过157,大致在75左右为佳,但是经过多次实验,发现在92个神经元的时候效果比较好
激活函数使用relu,效果比较好
输出层要设置27个输出节点,原因是标签到达26,而如果设置26个节点,接受的标签范围是[0,26),不包括26。
迭代次数设置20次即可,过多的次数并不会提高准确性
x_train = train_images.reshape(-1, 784)
x_test = test_images.reshape(-1, 784)
x_train, x_test = x_train / 255.0, x_test / 255.0
history = model.fit(x_train,train_labels,epochs=20,validation_data=(x_test,test_labels))
model.save("emnist_ann.model")其中,x_train和x_test除以255是为了将变量归一化,从而降低计算量
执行结果如下:

最终测试的预测准确率在89.09%
2.3 卷积神经网络
建立卷积神经网络模型
# 初始化序列模型 卷积神经网络
model = models.Sequential()
# 添加第一层卷积层,用128个3*3的卷积核,激活函数选择‘relu’,输入层(input_shape)# 是28*28(MNIST每一张图片的尺寸)后面的‘1’是图片的颜色数,MNIST是灰度图因# 此选1
model.add(layers.Conv2D(128, (3, 3), activation='relu', input_shape=(28, 28,1)))
# 加一层卷积层,64个3*3的卷积核,之后的input_shape都是自动的。
model.add(layers.Conv2D(64,(3,3), activation='relu'))
# 加一层最大池化,池化窗口2*2
model.add(layers.MaxPooling2D((2,2)))
# 加一层卷积层,32个3*3的卷积核
model.add(layers.Conv2D(32,(3,3), activation='relu'))
model.add(layers.Conv2D(16,(3,3), activation='relu'))
# 加一层最大池化,池化窗口2*2
model.add(layers.MaxPooling2D((2,2)))
#加一层卷积层,8个3*3的卷积核
model.add(layers.Conv2D(8,(3,3), activation='relu'))
# 将卷积后的矩阵展开,这就是全连接层的第一层
model.add(layers.Flatten())
# 再加一层全连接,80个神经元,激活函数为relu
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.3)) #增加dropout防止过拟合
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.3))#增加dropout防止过拟合
# 输出层,对应a-z
model.add(layers.Dense(27))
model.summary()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# fit,里面要解释的参数只有epochs和batch_size,epochs是用全部训练集的用例训练几次
# 模型的意思,为什么要用同样的数据集重复训练多次模型呢(这里举个恰当的例子),
# batch_size是每次迭代用到几个用例。
history = model.fit(train_images.reshape(124800, 28, 28, 1), train_labels, epochs=20, batch_size=32
, validation_data=(test_images.reshape(20800, 28, 28, 1), test_labels))
print(history)
model.save("emnist_cnn.model")其中,可以将全连接的神经元适当增加,提高准确率

在测试集中,预测的准确率在91.65%,相比于普通的神经网络,卷积神经网络的准确率更高一些,但是在算法上也更加复杂