一、梯度下降法的调试
1)疑问 / 难点
- 如何确定梯度下降法的准确性?
- 损失函数的变量 theta 在某一点上对应的梯度是什么?
- 在更负责的模型中,求解梯度更加不易;
- 有时候,推导出公式后,并将其运用到程序中,但当程序运行时,有时对梯度的计算可能会出现错误,怎么才能发现这种错误?
2)梯度下降法的调试思路
- 关于导数的理解,参考:高数:关于导数;
- 调试思路:
- 如果机器学习的算法涉及到求解梯度,先使调试方式求出梯度,提前得到此机器学习算法的正确结果;
- 用数学推导方式(根据算法模型推导出的求解梯度的公式)求出梯度的数学解,将数学解带入机器学习算法中,得出结果;
- 对比两种最终得到的结果是否一致,如果一样,则此数学推导公式可用,如果不一样,则此数学推导公式待改进;
3)公式的确定
- 导数的推导过程
- 公式:
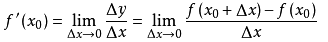

- 梯度的求解的思路,与导数类似
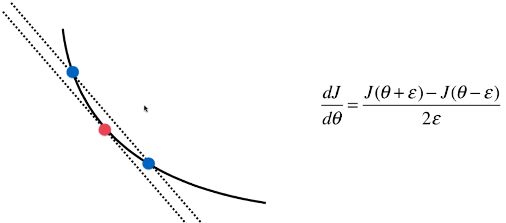
- 最终推导出的调试的公式
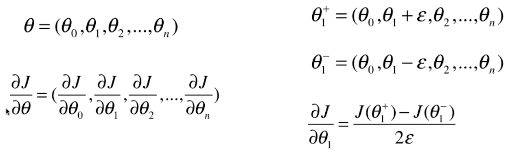
- θ:损失函数的变量(theta)
- θ1+ = θ + ε:表示 θ 右侧的点的变量;
- θ1- = θ - ε:表示 θ 左侧的点的变量;
- θ1+ - θ == θ - θ1- == ε
- 调试公式的特点:时间复杂度高,每求一次梯度都要花相当多的时间,因此一般此种求解梯度的方式只用于调试;
4)代码实现
- 数学模型推导方式求梯度
import numpy as np import matplotlib.pyplot as plt np.random.seed(666) X = np.random.random(size=(1000, 10)) true_theta = np.arange(1, 12, dtype=float) X_b = np.hstack([np.ones((len(X), 1)), X]) y = X_b.dot(true_theta) + np.random.normal(size=1000) def J(theta, X_b, y): """求当前 theta 的损失函数""" try: return np.sum((y - X_b.dot(theta)) ** 2) / len(X_b) except: return float('inf') def dJ_math(theta, X_b, y): """使用模型推导公式求当前 theta 对应的梯度""" return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)true_theta
- true_theta:有 11 个元素,因为包含截距;
- true_theta = np.arange(1, 12, dtype=float):是一个一位数组,并没有转置为向量;
- X_b.dot(true_theta) + np.random.normal(size = 1000):此时用 矩阵 . dot(一维数组) + 一维数组;
- 调试方式求梯度:
def dJ_debug(theta, X_b, y, epsilon=0.01): """使用调试方式求当前 theta 对应的梯度""" res = np.empty(len(theta)) for i in range(len(theta)): theta_1 = theta.copy() theta_1[i] += epsilon theta_2 = theta.copy() theta_2[i] -= epsilon res[i] = (J(theta_1, X_b, y) - J(theta_2, X_b, y)) / (2*epsilon) return res
- res:当前 theta 对应的梯度;
- theta_1 = theta.copy():将 theta 向量复制给 theta_1;# 此处的 copy() 是序列的方法;
- 特点:由于该求解过程与函数 J() 的内部实现无关,该过程适用于所有函数的梯度求解;
- 批量梯度下降法优化
def gradient_descent(dJ, X_b, y, initial_theta, eta, n_iters=10**4, epsilon=10**-8): theta = initial_theta cur_iter = 0 while cur_iter < n_iters: gradient = dJ(theta,X_b, y) last_theta = theta theta = theta - eta * gradient if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon): break cur_iter += 1 return theta
- dJ:代表求梯度的函数,这里作为参数,可以传入不同方法求解梯度;
- 初始化后得到结果(一):使用调试方式求解梯度
initial_theta = np.zeros(X_b.shape[1]) eta = 0.01 %time theta = gradient_descent(dJ_debug, X_b, y, initial_theta, eta) theta # 输出:Wall time: 4.89 s array([ 1.1251597 , 2.05312521, 2.91522497, 4.11895968, 5.05002117, 5.90494046, 6.97383745, 8.00088367, 8.86213468, 9.98608331, 10.90529198])
- initial_theta:theta 的初始化值,为一个向量,一般设置为全 0 向量;
- 初始化后得到结果(二):使用模型推导的公式求解梯度
%time theta = gradient_descent(dJ_math, X_b, y, initial_theta, eta) theta # 输出:Wall time: 652 ms array([ 1.1251597 , 2.05312521, 2.91522497, 4.11895968, 5.05002117, 5.90494046, 6.97383745, 8.00088367, 8.86213468, 9.98608331, 10.90529198])
- 两种结果对比:
- 调试公式求梯度,最终可以得到结果,但运行速度较慢;
- 通过(dJ_debug 函数)计算过程可以看出,这种调试方法对梯度的计算,适用于一切目标函数;
二、梯度下降法的其它思考
- 注:计算中有看不懂的地方,要对照着公式的推导过程理解;
1)梯度下降法类型类
- 批量梯度下降法(Batch Gradient Descent)
- 每一次都对所有样本进行计算,求出梯度
- 缺点:运算速度较慢;
- 优点:稳定,按此梯度方向,损失函数一定减小最快;
- 随机梯度下降法(Stochastic Gradient Descent)
- 每一次只对随机抽取的一个样本,求出其梯度,作为 theta 的优化方向;
- 优点:运算速度较快;
- 缺点:不稳定,每一次的优化方向是不确定的,甚至有可能像反方向优化;
- 小批量梯度下降法(Mini-Batch Gradient Descent)
- 综合了批量梯度下降法和随机梯度下降法的优点,避免了它们的确定;
- 思路:每次计算优化的方向(梯度),即不是查看所有样本也不只看一个样本,而是每次抽取 k 个样本,把这 k 个样本的梯度作为优化方向;
- 优点(一):比批量梯度下降法运算量小,速度快;
- 优点(二):比随机梯度下降法更稳定,获取的优化方向更能偏向批量梯度下降法中的梯度方向;
- 缺点:增加了一个新的超参数 k ,每一批该去多少个样本?
- k 个样本的梯度求解:和批量梯度下降法的求解过程一样;
2)随机的优点
- 跳出局部最优解:更能找到损失函数的整体最优解,而不像批量梯度下降法那样,每次选取初始值后,可能只优化得到一个局部最小值,而不是损失函数整体的最小值;
- 更快的运行速度
- 机器学习领域很多算法都要使用随机的特点:随机森林、随机搜索
- 机器学习领域解决的本身就是在不确定的世界中的不确定的问题,它本身可能就没有一个固定的最优解,因此随机扮演了一个重要的角色;
3)梯度下降法理解回顾
- 不是一个机器学习算法
- 是一种基于搜索的最优化方法
- 作用:最小化一个损失函数
- 梯度上升法
- 作用:最大化一个效用函数;
- 每次参数 theta 加上变化量;