引言:
TensorBoard是由Google开发的一个可视化工具,旨在帮助用户理解和调试深度学习模型的训练过程。PyTorch提供了一个名为SummaryWriter的接口,用于将各种类型的数据写入TensorBoard中。在TensorBoard中,用户可以通过直观的图表和可视化界面来浏览、比较和分析训练过程中的指标、学习曲线和特征图等信息。
在TensorBoard中,常见的可视化内容包括训练/验证损失曲线、学习率曲线、精度曲线、直方图和散点图等。通过这些可视化工具,用户可以更好地理解模型训练过程中的变化和趋势,进而采取合适的策略来优化模型性能和训练速度。
本文用pycharm编译器
绘制趋势图
先上代码
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')#实例化一个writer对象,指定存储路径为‘logs’
# writer.add_image()
for i in range(100):
writer.add_scalar("y = 2*x", 2*i ,i)
writer.close()这段代码使用了PyTorch中的可视化工具TensorBoard来记录模型训练过程中的信息。
首先,代码导入了PyTorch库中的SummaryWriter类。这个类提供了一个接口,用于将不同类型的数据写入TensorBoard中进行展示。
接下来,我们实例化了一个SummaryWriter对象,并将其储存在名为'logs'的文件夹中。此处的文件夹路径可以根据个人需求进行更改。
在for循环中,我们调用了writer对象的add_scalar函数来向TensorBoard中添加信息。其中,第一个参数代表添加信息的名称,第二个参数代表添加的数值,第三个参数代表该信息在训练中所处的步骤。
最后,我们调用了writer对象的close函数来关闭SummaryWriter对象。不要忘了close
其中
.add_scalar() 是 PyTorch 中 SummaryWriter 类提供的一个方法,用于将一个 scalar 值写入到 TensorBoard 中。其语法格式为:
writer.add_scalar(tag, scalar_value, global_step=None, walltime=None)
writer是我实例化的对象
参数含义如下:
tag(string):要写入的值在图表上展示的名字;scalar_value(float):要写入的值,可以是损失、精度等指标;global_step(int,可选):表示当前参数值的全局步骤数,用于指定此时参数对应的模型训练的步骤;walltime(float,可选):表示当前参数记录时的时间戳。
通过 add_scalar() 方法,我们可以将训练过程中一些关键指标(如损失、精度、学习率等)的变化情况记录到 TensorBoard 中,从而实现更清晰、直观的训练过程监控和调试。在每个 epoch 结束时,我们可以使用该方法将当前训练的相关指标写入 TensorBoard,方便随时查看模型在训练过程中的表现。
结果展示
在代码运行结束后,你会发现在项目文件夹下多了一个文件
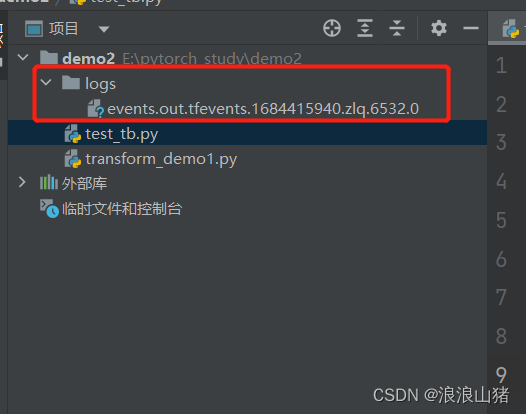
这就是你刚刚在实例化SummaryWriter时设置的文件路径
然后你可以在终端中输入tensorboard --logdir=文件名 的方式进行读取文件

点击生成的链接就可以在浏览器中查看训练结果


可以切换服务器地址.默认是6006。如果要切换地址,需要多输入一个--port=命令。比如6007的话可以输入
tensorboard --logdir=logs --port=6007
其中logs要改成你自己的文件路径
补充说明:
可以write多个数据,用于进行对比分析,
举个例子,还是刚刚的代码,多添一行
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('logs')#实例化一个writer对象,指定存储路径为‘logs’
# writer.add_image()
for i in range(100):
writer.add_scalar("y = 2*x", 2*i ,i)
writer.add_scalar("y = x",i,i)
writer.close()writer.add_scalar("y = x",i,i)
结果:

实际操作中,我们不会绘制y = 2x这种图片,可能会用来比较算法损失值什么的,举个例子
# 记录 SGD 优化算法下的损失值
for i, loss in enumerate(train_losses_sgd):
writer.add_scalar("train_loss/SGD", loss, global_step=i)
大家理解性使用。
绘制Image
此次用的数据可以从此下载
链接:https://pan.baidu.com/s/1hbwoweg4pt5xPyhQDBXOgw
提取码:w08t
--来自百度网盘超级会员V5的分享
代码实操与讲解
绘制步骤和之前绘制趋势图类似
首先实例化一个writer对象
writer = SummaryWriter('logs')#实例化一个writer对象,指定存储路径为‘logs’接着读取你需要的图片,可以用PIL读取,也可以用opencv读取,这里说一下opencv读取
import cv2
img_path = 'data/train/ants_image/0013035.jpg'
img = cv2.imread(img_path)0013035.jpg是我在数据文件中随便选取的一个图片
我们在python控制台中可以看到读取的图片类型是ndarray类型,而PIL读取的话不是这个类型的,我们需要用np.array()把他转换成ndarray类型才可以,而用opencv读取直接就是ndarray。为什么需要是这个类型呢,下面会说

绘制图片的方法是
writer.add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW') 方法用于将图像写入 TensorBoard。我们在pycharm中按住ctrl 点击一下他就能看源码

可以看到有这么多参数
简单解释一下,
tag 和之前绘制趋势图一样,就是定义一下你输出图片的名字,根据你的需要随便取一个名字就行
img_tensor就是你想要输出的图片,这里只接受ndarray类型的 和张量类型的(就是numpy类型或pytorch类型),所以我前文用opencv读取就直接就是ndarray
global_step:记录的步数(整数类型)
walltime:记录的时间戳(浮点数类型),用于可视化时按时间排序。如果未指定,则使用当前时间;
dataformats:图像数据的格式(字符串类型),默认为 'CHW'。可以取值为 'CHW' 或 'HWC'
根据他的参数要求,我们需要对opencv打开的文件稍加处理
opencv打开的图片是以三通道BGR形式,而这边转换成RGB形式才行,不然颜色会反过来,B,G,R就是蓝绿红三个波段。这个我不多解释
我们用以下代码转换图片格式(写给不会opencv的人,会的自行跳过,opencv不会的可以看我以前的文章,都讲得很详细)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)于此同时,我们还要传入dataforms参数,这个参数代表和你传入图片的格式对应
他默认为"CHW",C 表示通道数,H 表示高度,W 表示宽度;
但是opencv数据格式我们通过之前控制台可以发现是'HWC',所以我们这里要传入'HWC'

完整代码:
from torch.utils.tensorboard import SummaryWriter
import os
import cv2
img_path = 'data/train/ants_image/0013035.jpg'
img = cv2.imread(img_path)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# print(img.shape)
writer.add_image('ants1',img,1,dataformats='HWC')
writer.close()完事之后和之前绘制趋势图一样,会在logs(你实例化writer的时候指定的路径)里出现一个文件
在终端输入tensorboard --logdir=logs,然后点击生成的链接就行。
每次绘制都要重新输入这个命令,不然会有问题。

批量绘制
先看代码
from torch.utils.tensorboard import SummaryWriter
import os
import cv2
writer = SummaryWriter('logs')#实例化一个writer对象,指定存储路径为‘logs’
root_path = 'data/train/ants_image'
img_path = os.listdir(root_path) #列出文件夹下所有图片的名字
for i,img in enumerate(img_path):#i为枚举的索引,img为图片名
path = os.path.join(root_path,img) #把文件夹路径和图片名拼起来就变成图片的完整路径
print(path)
if path[-4:] != '.jpg':#如果文件夹中有文件不是jpg形式的就跳过
continue
image = cv2.imread(path)
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
writer.add_image(f"ants{i}",image,i,dataformats='HWC')
writer.close()逐行翻译
其中os.listdir()可以列出文件夹下的所有文件,以list格式存储

而
for i,img in enumerate(img_path)
这个是枚举遍历,这样的话可以同时遍历索引和内容。i就是遍历索引,img遍历之前list中所有图片的名字
path = os.path.join(root_path,img)
这个代码是把文件夹路径和img名拼起来,就是
'data/train/ants_image' 和'*******.jpg'拼起来变成完整图片路径
if path[-4:] != '.jpg':#如果文件夹中有文件不是jpg形式的就跳过
continue
我们可以发现测试文件夹中有错误数据,通过if判断跳过

剩下的和之前一样
完事之后在终端中输入命令点击链接就可以看

大多数图片默认是隐藏状态,点击他们就能看
