从明天起,做一个幸福的人
喂马、劈柴,周游世界
从明天起,关心粮食和蔬菜
我有一所房子,面朝大海,春暖花开
--------致 海子
没有海子的浪漫,但有同样的情怀,祝福每一个人,愿意分享自己的学习成果。海子的明天,彼岸,我的今天,当下。今天分享对scalar的学习成果。
scalar是用来显示accuracy,cross entropy,dropout等标量变化趋势的函数。 通过scalar可以看到这些量随着训练加深的一个逐步变化的过程,进而可以看出我们模型的优劣。
注意:
1)scalar只能用于单个标量的显示,不能显示张量;
2)scalar可以显示多次训练的结果
- 一、常规用法
1)在要显示的标量下添加代码:
# 观察值
correct_prediction = tf.equal(self.labels, tf.argmax(logits, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
print(correct_prediction)
tf.summary.scalar('optimizer', self.accuracy) # 记录优化器的变化
2)按照之前的介绍进行操作,打开IE中的tensorboard,就可以看到scalar:
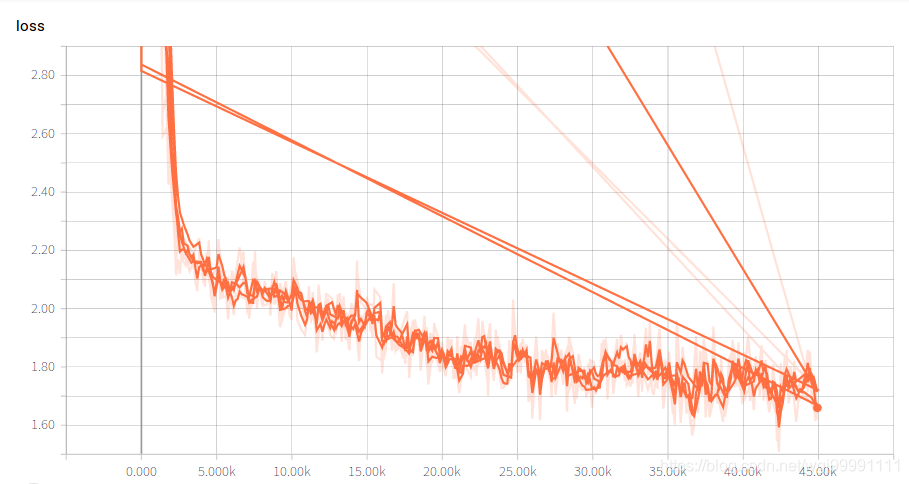
图中横坐标表示训练次数,纵坐标表示该标量的具体值,从这张图上可以看出,随着训练次数的增加,损失函数的值是在逐步减小的。
可以看到图上有直线,有曲线,这时使用相同的配置多次训练,然后相同的数据在同一个图上显示的结果,进入该log所在的文件夹,删除历史记录,仅仅保留最新的结果,就会如下图一样,出现一个比较干净的图。
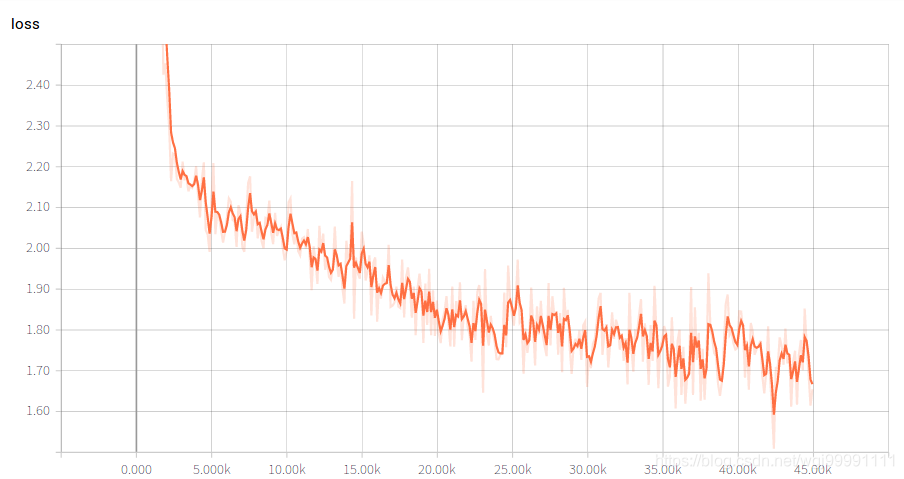
3)tensorboard左侧的工具栏上的smoothing,表示在做图的时候对图像进行平滑处理,这样做是为了更好的展示参数的整体变化趋势。如果不平滑处理的话,有些曲线波动很大,难以看出趋势。0 就是不平滑处理,1 就是最平滑,默认是 0.6。
4)工具栏中的Horizontal Axis指的是横轴的设置:
STEP:默认选项,指的是横轴显示的是训练迭代次数
RELATIVE:指相对时间,相对于训练开始的时间,也就是说是训练用时 ,单位是小时
WALL:指训练的绝对时间
- 二、显示多次训练的结果
要显示多次训练的结果,就要在每次训练的过程中给FileWriter设置不同的目录。比如第一次训练设置如下:
train_writer = tf.summary.FileWriter(log_dir + '/train', self.sess.graph)
那么第二次训练就可以设置为:
train_writer = tf.summary.FileWriter(log_dir + '/train_1', self.sess.graph)
这样当按照常规步骤打开tensorboard时,在面板的左侧就会显示不同的训练结果文件,如果要打开,则勾选相应的文件即可。
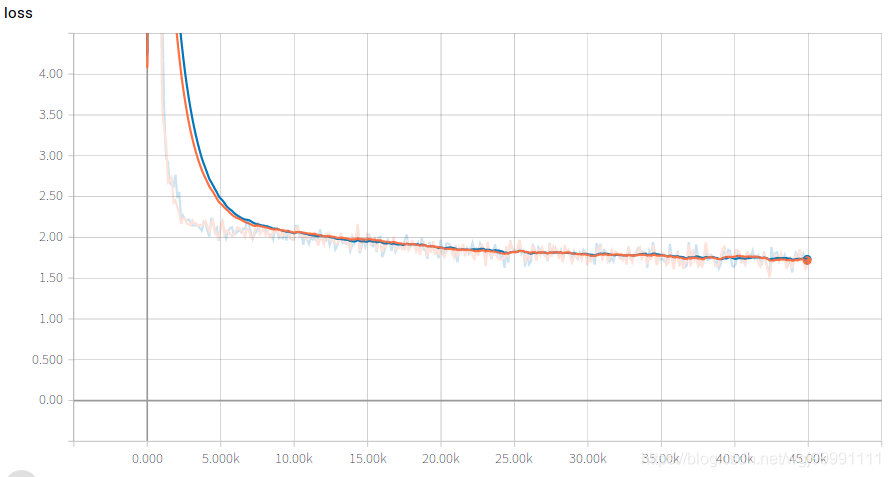
如上图所示,当勾选多个时,在图中就会以不同的颜色显示不同的图像。
- 三、如何在scalar中查看张量的信息
我们指导scalar只能显示标量信息,他不能直接显示张量的信息,但是我们可以换一种方式,比如显示张量的最大值、最小值、平均值等信息。
首先写一个函数:
def variable_summaries(self,var):
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
要显示那个张量,就可以直接用这个函数来完成。
self.conv = tf.layers.Conv2D(
filters=self.n_filter,
kernel_size=[self.y_size, self.x_size],
strides=[self.y_stride, self.x_stride],
padding='SAME',
data_format=self.data_format,
activation=None,
use_bias=not self.batch_normal,#在使用批标准化技术时,一般只要权重,不要偏移
kernel_initializer=tf.constant_initializer(weight_init_value),
trainable=True,
name='%s_conv' % (self.name))
self.variable_summaries(weight_init_value)
这段代码就可以显示卷积层的卷积核的权重值。
注意这里将函数 tf.layers.Conv2D的输入参数kernel_initializer,的初始化值weight_init_value作为要显示的参数,就可以实现对卷积核权重值的显示。在namescope的作用下,使用上述方法可以显示各个层中的这个参数。如下图所示:
2018年12月2日,发现上面写的对张量的显示方法是有问题的,当时写的是可以用kernel_initializer参数来初始化要显示的变量,这样虽然能显示出结果,但是这个结果就是图在初始化时候的值,在整个运算过程中是不变的,因此没有意义。
有效的方法如下:
def get_output(self, inputs, is_training=True):
with tf.name_scope('%s_cal' % (self.name)) as scope:
# hidden states
self.hidden = self.conv(inputs=inputs)
self.variable_summaries(self.conv.weights)
# batch normalization 技术
if self.batch_normal:
self.hidden = self.bn(self.hidden, training=is_training)
# activation
if self.activation == 'relu':
self.output = tf.nn.relu(self.hidden)
elif self.activation == 'tanh':
self.output = tf.nn.tanh(self.hidden)
elif self.activation == 'leaky_relu':
self.output = self.leaky_relu(self.hidden)
elif self.activation == 'sigmoid':
self.output = tf.nn.sigmoid(self.hidden)
elif self.activation == 'none':
self.output = self.hidden
return self.output
之前,是在层定义过程中加入数据采集的语句,这样是有问题的,应该在层运算get_output的过程中加入数据采集语句。self.variable_summaries(self.conv.weights)
而且,数据采集的对象不能是kernel_initializer,而应该是层权重这个变量:self.conv.weights,注意是weights,而不是get_weights(),试了好多次才成功。
正确的结果如下:
- 四、如何分析scalar图
1)可以看到标量的变化趋势。如果我们看到损失函数的值随着训练迭代次数的增加,逐渐减小,则说明我们的模型是有效的,可以通过训练得到一个好的结果;反之,如果发现损失函数没有变小,或者震荡很大,那么则说明我们的模型不是很好,需要调整。
2)可以多图对比。我们调整模型的参数,进行多次训练,进行多图对比,就可以发现哪次的图形好看,就说明这次的模型参数设置更为科学。