问题分析
给定PL/0语言算数表达式的BNF:
<表达式> ::= [+|-]<项>{<加法运算符> <项>}
<项> ::= <因子>{<乘法运算符> <因子>}
<因子> ::= <标识符>|<无符号整数>| '('<表达式>')'
<加法运算符> ::= +|-
<乘法运算符> ::= *|/要写出一个能判定给定的输入串是否是合法表达式的程序。先将这个BNF变成文法,为上面的不确定的符号起个符号名:
| 非终结符 | 符号名 |
|---|---|
| 表达式 | E |
| 项 | I |
| 加法运算符 | A |
| 因子 | F |
| 乘除 | M |
| 标识符 | i |
| 无符号整数 | u |
变成文法G(E):
E->AI(AI)*|I(AI)*
I->F(MF)*
F->i|u|(E)
A->+|-
M->*|/为了编程方便,引入K1和K2两个非终结符以消除闭包:
E->AIK1|IK1
K1->AIK1|ε
I->FK2
K2->MFK2|ε
F->i|u|(E)
A->+|-
M->*|/确保它是一个LL(1)文法
现在文法中没有左递归,也没有左公共因子,但有空产生式,不见得就是LL(1)文法求出SELECT集验证一下,而且SELECT集在后面做递归下降时也要用到。
①求能推出ε的非终结符
| 次数\非终结符 | E | K1 | I | K2 | F | A | M |
|---|---|---|---|---|---|---|---|
| 初值 | ? | ? | ? | ? | ? | ? | ? |
| 第一遍 | v | v | x | x | x | ||
| 第二遍 | x | v | x | v | x | x | x |
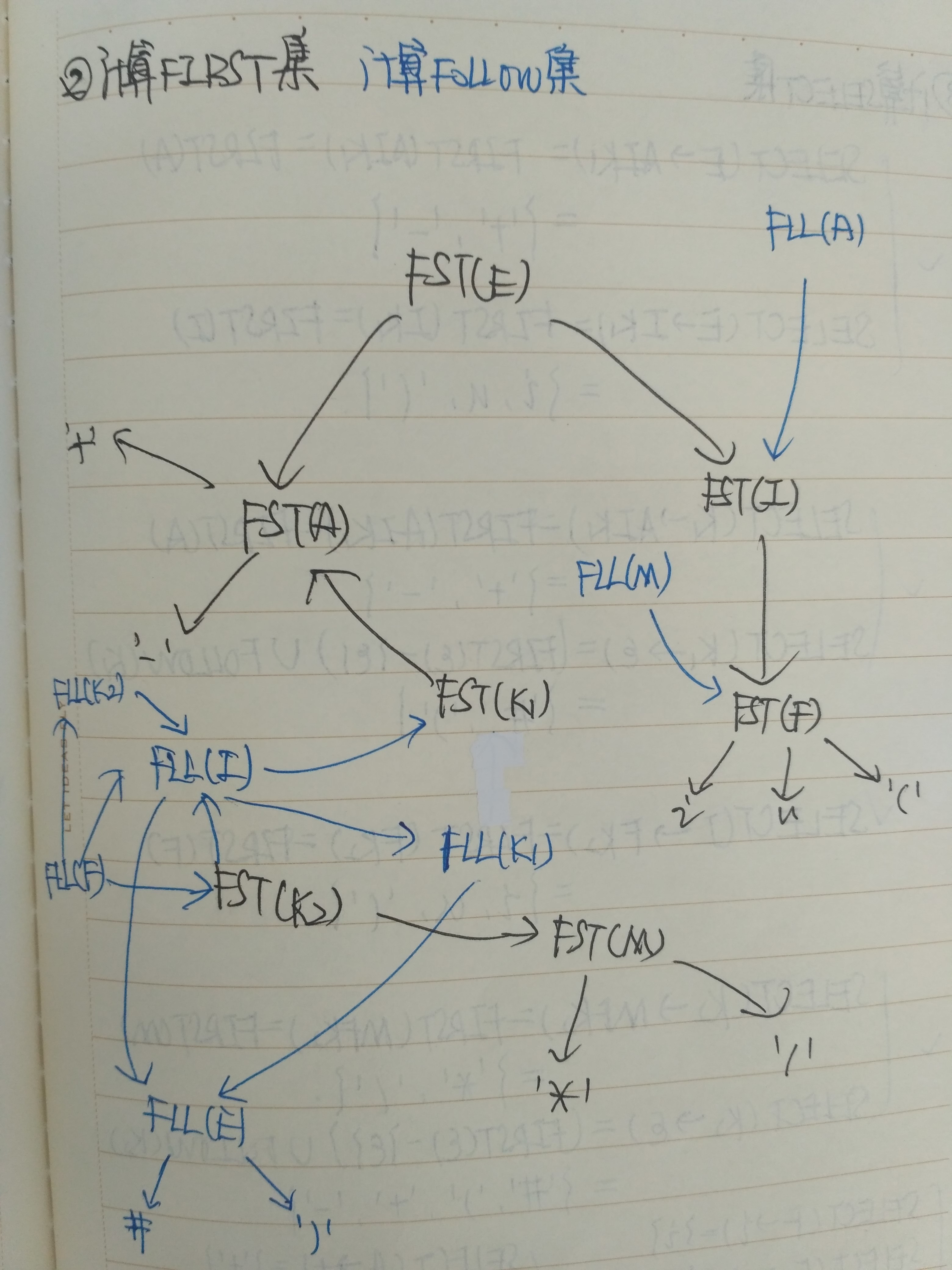
②计算FIRST集,FOLLOW集
③计算SELECT集
相同左部的SELECT集不相交,说明这个文法是LL(1)文法。

程序
Main.cpp
#include"Rely.h"
#define MAXLEN 100
using namespace std;
//****************************************************
char c;//通用
bool psr=true;//记录语法分析阶段是否出错
int s_len=0;//读入的字符串长度
char* s_pre=new char[MAXLEN];//原始串
list<int> ls_term;//顺序地存终结符种别的list
list<int>::iterator it;//list的游动迭代器
list<int>::iterator it_fst;//list的头部迭代器,用来计算下标
//****************************************************
void ParseE();
void ParseK1();
void ParseI();
void ParseK2();
void ParseF();
void ParseA();
void ParseM();
//****************************************************
//表达式(Expression)解析
void ParseE(){
if(add_sub==*it){
ParseA();
ParseI();
ParseK1();
}
else if(identifier==*it || unsignint==*it || lparen==*it){
ParseI();
ParseK1();
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处表达式需以{'+','-',标识符,无符号整数,'('}开头\n"<<endl;
psr=false;
}
}
//中间件K1解析
void ParseK1(){
if(add_sub==*it){
ParseA();
ParseI();
ParseK1();
}
else if(rparen==*it){
//这是[K1=>空]的情况,什么都不做
//因为这个rparen并非自己产生出来的
}
//当遇到终结符且自己非空时需要做++
//当终结符是[结尾标识]时成功接受
else if(end==*it & ls_term.end()==++it && true==psr){
cout<<"[语法正确]语法分析结束\n";
it--;
}
else{
it--;
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处K1类型错误\n"<<endl;
psr=false;
}
}
//项(Item)解析
void ParseI(){
if(identifier==*it || unsignint==*it || lparen==*it){
ParseF();
ParseK2();
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处项需要以{标识符,无符号整数,'('}开头\n"<<endl;
psr=false;
}
}
//中间件K2解析
void ParseK2(){
if(mul_div==*it){
ParseM();
ParseF();
ParseK2();
}
else if(rparen==*it || add_sub==*it){
}
else if(end==*it & ls_term.end()==++it && true==psr){
cout<<"[语法正确]语法分析结束\n";
it--;
}
else{
it--;
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处K2类型错误\n"<<endl;
psr=false;
}
}
//因子(Factor)解析
void ParseF(){
if(identifier==*it || unsignint==*it){
it++;
}
else if(lparen==*it){
it++;
ParseE();
if(rparen==*it){
it++;
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处缺少')'\n"<<endl;
it++;
psr=false;
}
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处因子需要以{标识符,无符号整数,'('}开头\n"<<endl;
//不能局限于一处报错,出错也要继续向下判断其它错误
//通过bool值记录已经处于出错状态,最终不会出现语法正确信息
it++;
psr=false;
}
}
//加减(Add_sub)解析
void ParseA(){
//这里已经将'+'和'-'聚合成了枚举的add_sub
//实际上前面已经判定过,这里再确认一次
if(add_sub==*it){
it++;
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处加号和减号应是{'+','-'}\n"<<endl;
it++;
psr=false;
}
}
//乘除(Mul_div)解析
void ParseM(){
//这里已经将'*'和'/'聚合成了枚举的mul_div
//实际上前面已经判定过,这里再确认一次
if(mul_div==*it){
it++;
}
else{
cout<<"[语法错误]"<<distance(it_fst,it);
cout<<"处乘号和除号应是{'*','/'}\n"<<endl;
it++;
psr=false;
}
}
//****************************************************
int main(int argc,char** argv)
{
//读入输入串并记录长度
while('\n'!=(c=getchar()))
s_pre[s_len++]=c;
s_pre[s_len]='\0';
//解析输入串并存入list
cutWord(ls_term,s_pre,s_len);
//在解析后的list尾部添加一个#[结尾标识]
ls_term.push_back(end);
//cout<<s_pre<<endl;
//游动的迭代器建立,固定的头部迭代器建立
it=it_fst=ls_term.begin();
//递归下降做LL(1)语法分析
ParseE();
//堆空间释放
delete[] s_pre;
return 0;
}Rely.h
#ifndef __RELY_H__
#define __RELY_H__
#include<bits/stdc++.h>
using namespace std;
//待分析对象类型
enum Status{
end=-2,//结尾标识,即#符号
none=0,//啥也不是|空格|制表符,不会被添加到list中
expression=1,//表达式
item=2,//项
add_sub=3,//加减
mul_div=4,//乘除
factor=5,//因子
identifier=6,//标识符
unsignint=7,//无符号整数
lparen=8,//左括号
rparen=9//右括号
};
//当前字符类型
enum Sign{
nop=0,//没有符号|空格|制表符
num=7,//数字0-9
word=6,//字母[a-z]|[A-Z]
error=-1,//非法字符
//下面的符号可以直接被解析为待分析对象类型
//所以使用和其对应的相同数值,而且名字不能相同
addSub=3,//加减号
mulDiv=4,//乘除号
lParen=8,//左括号
rParen=9//右括号
};
//****************************************************
//对传入的串分词,获取模式并存入list
void cutWord(list<int>& ls,char* cArry,const int& len);
//传入一字符,获取字符类型
Sign getSign(char c);
//****************************************************
//对传入的串分词,获取模式并存入list
void cutWord(list<int>& ls,char* cArry,const int& len)
{
bool isHead=true;//指示是否在扫描非终结符的头
//不直接使用枚举类型,因为枚举类型不能转型为另一枚举类型或者int类型
int nowPat=none;//正在处理的模式,取决于模式中头一字符
int nowSign=nop;//正在处理的符号类型
for(int i=0;i<len;i++)//对于数组中的每个字符
{
nowSign=getSign(cArry[i]);//获取当前符号的类型
if(error==nowSign)//处理非法字符
{
cout<<"[命名错误]存在非法字符\n"<<endl;
exit(0);
}
//cout<<now<<endl;
/*连续向下走的情况*/
//当前在继续正常处理标识符
if(identifier==nowPat && (num==nowSign || word==nowSign))
continue;
//当前在继续正常处理无符号整数
if(unsignint==nowPat && num==nowSign)
continue;
/*命名异常立即报错*/
//常数模式下的数字后跟字母不允许
if(unsignint==nowPat && word==nowSign){
cout<<"[命名错误]纯常数数字后跟字母非法\n"<<endl;
exit(0);
}
/*改变类型向下走,不作检查,词法分析阶段再处理*/
nowPat=nowSign;//在设计枚举时设计成数字相同的
if(none!=nowPat)//空白符不被存入list中
{
//cout<<nowPat<<" ";
ls.push_back(nowPat);//其它字符上转int被存入list中
}
}
cout<<endl;
}
//传入一字符,获取字符类型
Sign getSign(char c)
{
if(' '==c || '\t'==c)
return nop;//0
else if('0'<=c && c<='9')
return num;//1
else if(('a'<=c && 'z'<=c)||('A'<=c && 'Z'<=c))
return word;//2
else if('+'==c || '-'==c)
return addSub;//3
else if('*'==c || '/'==c)
return mulDiv;//4
else if('('==c)
return lParen;//8
else if(')'==c)
return rParen;//9
return error;//5
}
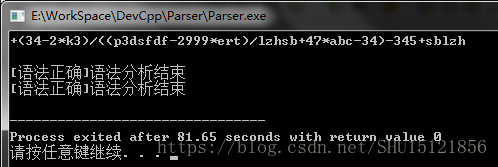
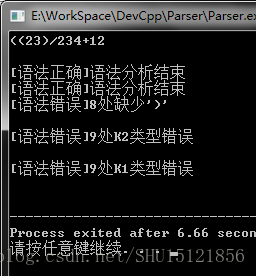
#endif运行结果
报错还是逻辑有些混乱,不过还是能分出来对错了。