引言
好久没总结过新东西了,这次就把最近自己通过拼凑代码实现的一个点云目标检测网络现在这做个总结吧。
不过我的网络还没来得及改进,大思想就和别人的撞车了,人家已经发了CVPR,对于自己这个半成品网络也没什么兴趣继续改进了。
CVPR2021的论文是:
Center-based 3D Object Detection and Tracking
代码:https://github.com/tianweiy/CenterPoint
我搭的网络目前叫CenterPillar,当然也就图一乐。。。我是在KITTI数据集上跑的,先把结果放出来吧:
在笔记本的RTX2060mq上可以跑18fps左右。

代码链接放这:https://github.com/wangx1996/CenterPillarNet
基本思路
其实思路很简单,pointpillar加centernet构成,pointpillar用来作为点云的编码网络,centernet用来做特征提取的backbone和neck以及head部分。整体思路基本与去年地平线的AFdet方法一致,不过我没有将centernet网络的输出再上采样回原有尺寸,而是1/2大小,并且backbone用的也不同,目标角度编码方式也不同。
一一说明
网络头采用pointpillar没啥好说的,编码为pesudo image
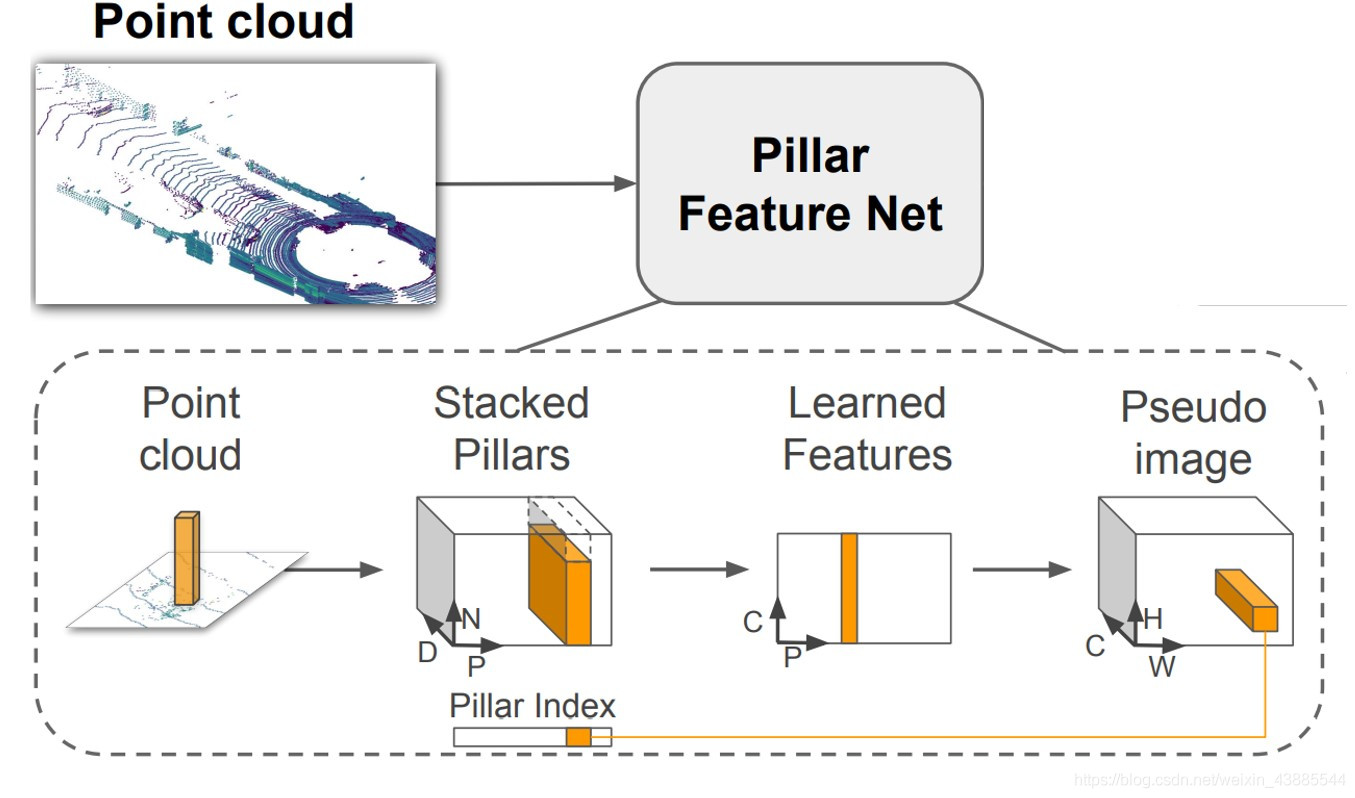
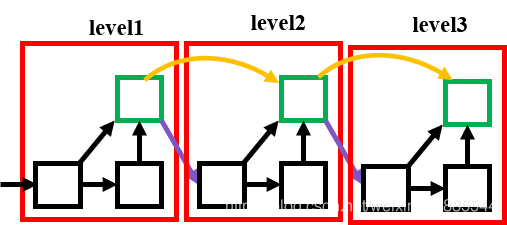
之后将pesudo image输入backbone中,这里不同原有的centernet 的DLA34seg,原有的网络的层数很多,执行效率不是很高,试验了多种组合后最终才确定了一个效率和准确度在这之中算是好的。
具体DLA的结构以及上采样部分可查看Centernet:
最后的neck和head与AFdet中的基本一致:
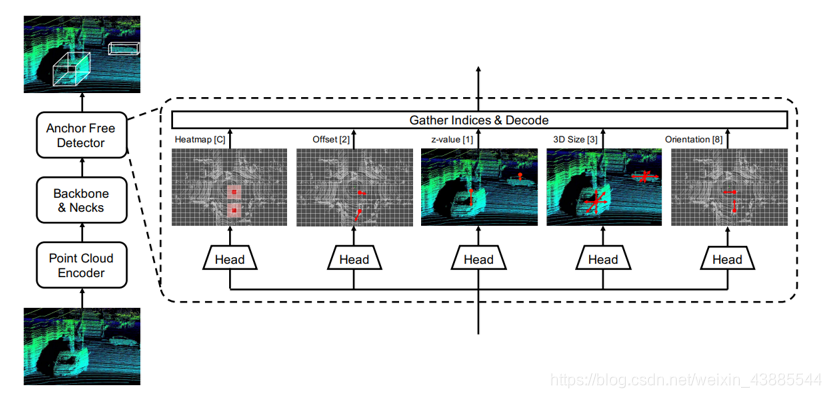
不过角度的编码用的是cos与sin来表示目标的角度值,没有用论文中的方法,因为试了这种方式,发现loss很难下降,仔细查明后这种方法一般多用在二维图像转三维目标的角度编码中,应该不太适用于点云的编码。
未完成的东西
代码的大框架用的是:
second-pytorch
SFA3D
没有像pointpillar一样加入随机真值增减的数据增强部分,这部分也不想再加了,如果谁有兴趣可以试试效果。
后期也想过先找heatmap目标再对目标box尺寸用pointnet进一步做调整,不过CVPR21中的论文以及做了,我就没必要再做下去了。
放一下在测试集上的结果:
Car AP(Average Precision)@0.70, 0.70, 0.70:
bbox AP:78.04, 73.71, 66.88
bev AP:79.25, 73.67, 66.84
3d AP:60.75, 55.75, 51.03
Car AP(Average Precision)@0.70, 0.50, 0.50:
bbox AP:78.04, 73.71, 66.88
bev AP:82.64, 77.12, 69.38
3d AP:82.31, 76.68, 69.07
可以看到在BEV上效果还行,3Dbox不太行,所以我后期想加入pointnet再做一次回归,不过现在不用了。。。
不过如果你有兴趣可以在我的基础上继续改进,说不定能改出什么比较好的检测方法。