PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud
代码
论文
一、论文思路
本文提出了一个两阶段的3D detection模型PointRCNN。论文的模型分为两个阶段,第一阶段先使用PointNet++作为一个前景分割模型,分割出前景作为3D的proposal;第二阶段再将得到的proposal和上一阶段的特征一起作为模型的输入,得到精准的bounding box回归。

二、模型实现
2.1 阶段一
第一阶段如上图所示,基本上就是通过了一个PointNet++去提取全局点云的特征,紧接着实现一个前景的分割和粗粒度的bounding box。
- 需要注意的是在前景分割中使用的是Focus Loss:

- 在Bounding box的生成中有两个关键步骤,一个是中心点的确立,另一个是尺寸和方向的确立。对于后者,这篇文章使用的方法基本和Frustum PointNets相同,这里主要说前者。对于前者,这篇文章提出了一个bin-based方法去定位bounding box的中心点,如图所示:

对于每一个分割出的前景点,都对x-z坐标系构建一个网格,每一格的举例是认为给定的,因此就可以初步预测中心点在哪一格里,再对其进行精确地残差回归(y轴由于比较扁平,因此可以直接回归)。最终的目标如下:

其中σ和S是搜索的范围, 和 是X轴和Z轴上的ground truth。 - 在实验过程中,这篇文章先选择置信度最高的bin-based中心点,再去回归bounding box的参数(长宽高和朝向角),最后对于每一个前景的点,都计算这样的输出。在训练的时候,其采用0.85 IoU的MNS(最大值抑制)去去除鸟瞰图上的bounding box,其后只选择前300去训练阶段二的模型(测试的时候只保留前100)。
2.2 阶段二
作者利用得到的proposal,稍微扩大一定的大小,获得更大的context信息,然后将相应的点的原始特征还有segmentation提取的特征进行融合。
接着作者利用Canonical Transformation (正交变换),转换到每个proposal的local坐标系,其中坐标系的中心点是proposal的center,X,Z轴平行于地面,X轴指向proposal的heading方向,这样的方式更有利于local特征的学习,同时学习的方式跟stage one一样,也是利用PointNet++的结构结合bin-based的方式,把回归问题转化成分类的问题。

最后,再通过MNS>0.01去掉所有重合的bounding box。
2.3 实现细节
- 输入:第一阶段的输入是16384个点,第二阶段的输入是512个点;
- 网络结构:第一阶段是四层三尺度的PointNet++,采样个数为【4096,1024,256,64】,第二阶段为三层单尺度,采样个数为【128,32,1】;
- 第一阶段(车):
选择ROI的时候在原前景分割的基础上往外取0.2m;
bin-based的中心点预测时S=3m,σ=0.5m;
旋转角预测时n=12(一共12个bin);
200 epoch,16 bs,0.002 lr。 - 第二阶段(车):
对于box置信度的输出:IOU>0.6为正例,<0.45为负例;
对于角回归的输出:IOU大于0.55;
对于bounding box的参数学习:S=1.5m,σ=0.5m,旋转角是10°;
随机翻转、尺度缩放[0.95,1.05],在y轴旋转[-10,10]°;
将不同场景的相同物体,放在该场景的相同位置,来模拟不同场景的相同物体;
50 epoch, 256 bs, 0.002 lr。
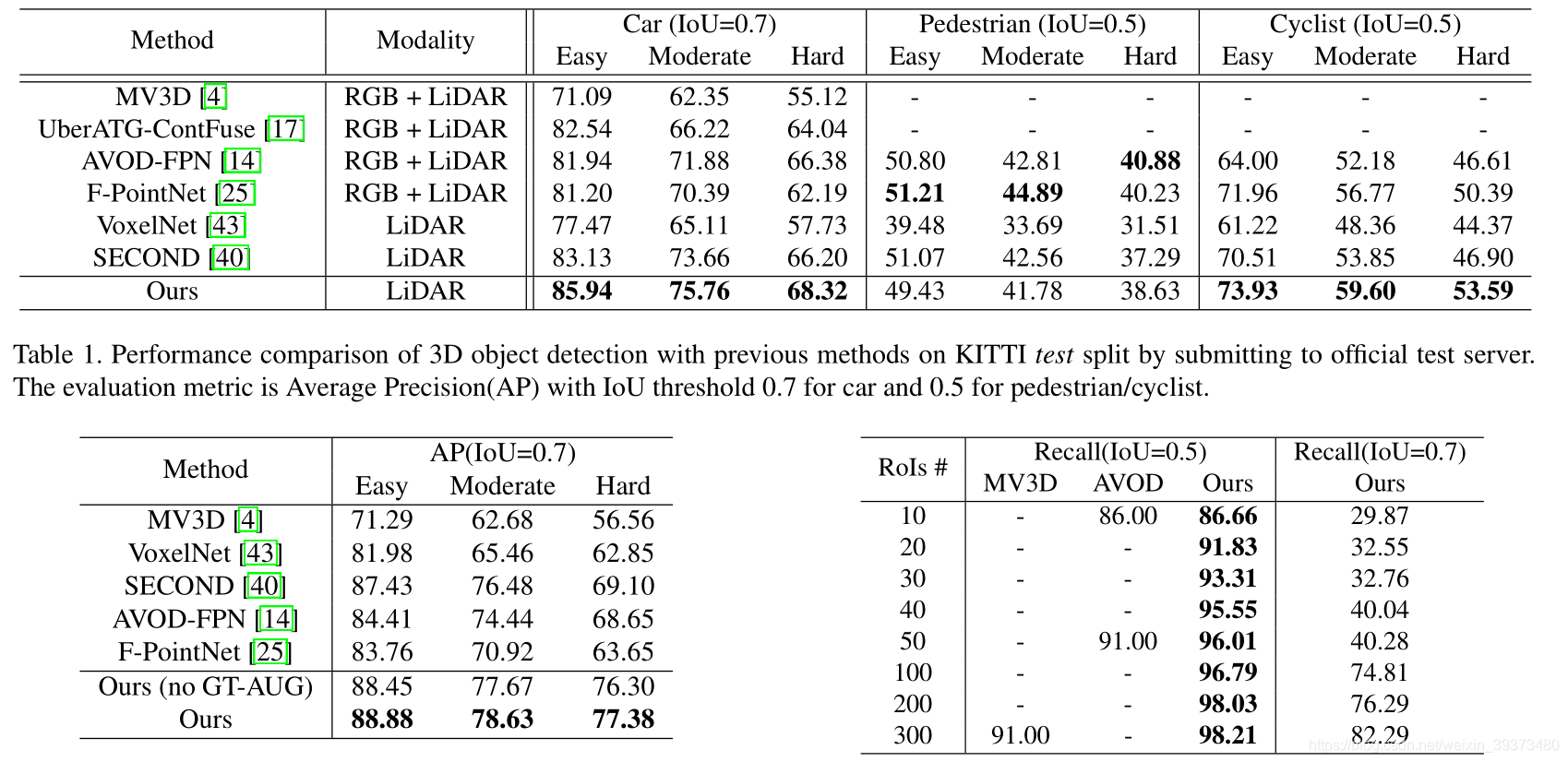
三、实验结果