前言
在进入正题之前,首先我们来讲点概念性的东西,在传统的软件开发流程中,我们一般采用devops的流程,其中的核心阶段包含产品立项–需求分析–原型设计–前后端开发–测试–持续发布–生产运维等等,可以看出整个周期是非常长,这其实不满足当下机器学习不断产出新模型不断落地的要求,特别是在没有做过机器学习业务的传统软件开发公司里。于是引出了mlops的概念,即更快的开发模型,更快的部署模型,和确保模型的质量,而为了达成这点就需要一个统一管理部署模型的工具。这个工具应该让数据科学家能够直接使用,尽量减少语言障碍,以及尽量减少部署要求。
什么意思呢?下面我将给大家一个实例理解:笔者身为公司唯一一个数据科学家,每次训练完模型之后需要把它投入生产,此时我需要先找产品说明情况,再找平台端(java)商量怎么部署,按之前的做法需要笔者本人自己把模型用m2cgen库直接转换为java代码(只有简单的十几种模型可以且不支持预处理),或者用pmml标准格式把模型导出为pmml文件,再通过jpmml库调用(比m2cgen全多了支持pipeline直接转换但是bug奇多且一个bug找一天)。以上两种方式,需要你有一定的java知识,同时也浪费了你大量时间在找不属于自身的bug上,导致新模型开发进度严重缓慢,虽然好处是你不用管后面的事情,但这种方式也对java开发的程序员不友好,增加了任务,延长了周期,甚至部署的时候还容易出毛病(需要大量的沟通毕竟他们不懂)。
那么正确的做法我想也有些老手猜到了,没错,就是把模型放在云上,用API服务去调用。但问题也随之而来:
一.放在交钱的大型云上,如paddlepaddle,华为云。这方面外国更成熟,但是我想因为隐私和机密还有网络问题大家很少会去选择。且国内的大厂都给你开发好了一套白痴型的部署工具,管理起来不是很方便吗?没问题,有钱任性,但我没钱,我也不可能向公司申请一个流程来照顾我这还没盈利的业务,我觉得这种方法更适合那些有钱的中大型公司。
二.那就本地在服务器上起个服务部署,使用100%你会搜索到的python的flask库自己写。 这种方式的问题在于,你得自己写很多额外的代码,麻烦,同时部署不方便,你需要一个单独部署python环境的服务器,如果你到别人企业里私有化部署难不成你还一步步给它安装一个python环境吗?所以照我来看,这也只是一种临时方案,无法满足我一键部署一键生产的要求。
于是在翻遍了github的机器学习的生产部署库后,我终于看到了一款完美符合我需求,即使渣渣服务器也能跑的免费开源库----bentoml。
bentoml非常通用,基本支持常见的框架,这里就不说了,总之就是非常通用,深度学习的模型也可以通过它布,下面我还是用最简单的sklearn讲解。
在讲解bentoml库的同时我也将分享我自己的部署方案。
所以流程是?
其实在搜索机器学习模型部署的过程中最头疼的事情就是你没有一个清晰的概念,该怎么做,服务器是什么,怎么和我的模型联系在一起,怎么通过API调用,而网上的很多文章也不讲具体的流程,把代码往那一贴就完事了,也不知道是从哪抄来的代码,又或者是官方示例,不知所云。
下面给出我自己画的大概流程图配合食用:

那么代码是?
首先是安装,这个想必大家懂得都懂了
pip install bentoml
这里说一下bentoml目前最高兼容python3.8,虽然3.9也能用,但是假如你用不习惯win10的docker想用虚拟机装环境跑docker时请务必保持各包(python,sklearn,numpy等等)版本一致,不然可能导致某些复杂模型结果不准(比如stackingclassifier)。
然后就是第一步,本地先把模型训练到完美的程度,当然如果你只想随便试一下能不能用,建议抄示例:
from sklearn import svm
from sklearn import datasets
# Load training data
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Model Training
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
这一步我在流程图上写.ipynb是因为个人喜欢用Jupyterlab跑模型,在部署的过程中把你的关键代码复制到notebook里跑一跑是一个好习惯。总之,你要在这一步保证你的代码就算作为一个脚本文件也能顺利运行。
第二步,利用bentoml库打包模型,个人不喜欢官网的打包架构方式,不利于操作和理解,在这里我们把主体分为export.py和bento_service.py两部分。export.py为主体,涵盖了模型的训练和打包两部分,bento_service.py作为一个类导入进export.py里使用。你需要把它们放到conda的python解释器的具体目录下方便后面的命令行操作。
具体如下:
#export.py
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from bento_service_json import IrisClassifier
from sklearn.decomposition import PCA
df_temp1 = pd.read_excel('temp1.xlsx')
df_temp2 = pd.read_excel('temp-e.xlsx')
le = preprocessing.LabelEncoder()
x = df_temp1.iloc[:,1:17]
y = le.fit_transform(df_temp1.iloc[:,17])
x1 = df_temp2.iloc[:,1:17]
y1 = le.fit_transform(df_temp2.iloc[:,17])
X_train, X_test, y_train, y_test = train_test_split(x, y,
train_size=0.8, test_size=0.2, random_state=42)
estimators = [
('GB', GradientBoostingClassifier(learning_rate=1.0, max_depth=8, max_features=0.35000000000000003, min_samples_leaf=9, min_samples_split=6, n_estimators=100, subsample=0.6500000000000001,random_state=42)),
('tree', DecisionTreeClassifier(criterion="gini", max_depth=9, min_samples_leaf=1, min_samples_split=2,random_state=42))
]
model = StackingClassifier(
estimators=estimators,stack_method='predict',final_estimator=KNeighborsClassifier(n_neighbors=3, p=2, weights="uniform")
)
model.fit(X_train,y_train) #模型1
X_train, X_test, y_train, y_test = train_test_split(x1, y1,
train_size=0.75, test_size=0.25, random_state=42)
clf=GaussianNB()
clf.fit(X_train,y_train) #模型2
# 从bento_service.py里面抽取的服务类
iris_classifier_service = IrisClassifier()
# 打包两个模型
iris_classifier_service.pack('StackingClassifier', model)
iris_classifier_service.pack('GaussianNB', clf)
# 保存到本地,路径可自己写
saved_path = iris_classifier_service.save()
别看代码那么长,其实只是把第一步的训练代码放了进去,同时加上了四行打包代码,另外为了拓展知识,我们在这里使用了两个模型,同时打包进一个服务里面。
#bento_service.py
import pandas as pd
import json
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import JsonInput
from bentoml.frameworks.sklearn import SklearnModelArtifact
@env(infer_pip_packages=True) #打包时自动寻找所有的依赖
@artifacts([SklearnModelArtifact('StackingClassifier'),SklearnModelArtifact("GaussianNB")])#定义的两个模型
class IrisClassifier(BentoService):
@api(input=JsonInput(), batch=False)#使用jsoninput,batch注意为false
def predict(self, parsed_json):
df = pd.read_json(parsed_json,orient='table')#将json转换为dataframe
data1 = df[["Aggression", "pressure", "anxiety", "suspect", "balance","confidence", "energy", "self-regulation", "inhibition", "neuroticism","deperession", "happiness", "fh_m", "fh_s","I","E"]]#选取特征列
result = pd.DataFrame([['StackingClassifier', self.artifacts.StackingClassifier.predict(data1),'HealthType=2'], ['GaussianNB', self.artifacts.GaussianNB.predict_proba(data1)[:, 0],'Probability']])
return json.loads(result.to_json(orient="records")) #按行导出json
bento_service.py是核心,如果代码报错90%可能性是出自这块,这块我们比较关心的是输入和输出,输入有多种方式,你也可以直接用dataframeinput,但这里我们为了扩展知识采取了与示例不同的json方式,json的输入格式如下:
datain = '{"schema":{"fields":[{"name":"index","type":"integer"},{"name":"Aggression","type":"number"},{"name":"pressure","type":"number"},{"name":"anxiety","type":"number"},{"name":"suspect","type":"number"},{"name":"balance","type":"number"},{"name":"confidence","type":"number"},{"name":"energy","type":"number"},{"name":"self-regulation","type":"number"},{"name":"inhibition","type":"number"},{"name":"neuroticism","type":"number"},{"name":"deperession","type":"number"},{"name":"happiness","type":"number"},{"name":"I","type":"number"},{"name":"E","type":"number"},{"name":"fh_m","type":"number"},{"name":"fh_s","type":"number"},{"name":"Extroversion","type":"number"},{"name":"Stability","type":"number"}],"primaryKey":["index"],"pandas_version":"0.20.0"},"data":[{"index":100,"Aggression":46.58,"pressure":23.35,"anxiety":41.71,"suspect":37.76,"balance":64.67,"confidence":79.75,"energy":31.07,"self-regulation":72.71,"inhibition":23.41,"neuroticism":23.65,"deperession":25.13,"happiness":28.26,"I":28.99,"E":4.23,"fh_m":2.26,"fh_s":0.71,"Extroversion":0.36,"Stability":0.43}]}'
用pd.read_json时传入的json一定要包含schema,不然pandas不知道用什么数据类型去读你传过来的数据,这边非常建议百度json,复制校验一下你的json格式对不对,如果你传的json包含很多斜杠,说明你用了json.dumps,你应该用json.loads方法先把斜杠去掉再传。
核心的predict方法,想返回什么参数,是预测值还是概率,都可以自己定义自己写。
在准备好两个py文件之后,进入第三步,启动命令行:
输入python export.py,就会开始运行你的脚本程序,如果出现以下字样:

表示模型已经打包成功了!现在你可以启动你的服务了。使用bentoml serve IrisClassifier:latest命令启动你最新生成的服务,或者把latest改为你要启动的服务的版本号,比如上图里就是20220110113101_2C47F4,实际上是年月日时分秒加六位十六进制。

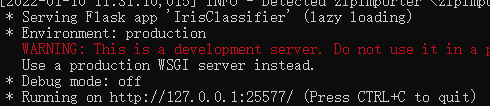
你就拿到了你本地服务器的ip地址,http://127.0.0.1:25577,模型已经跑在服务器上了,接下来进行本地传参测试:
import requests
response = requests.post("http://127.0.0.1:25577/predict", json=datain) #datain是你要传的json
print(response.text)
#[{"0": "StackingClassifier", "1": [1], "2": "HealthType=2"}, {"0": "GaussianNB", "1": [1.0], "2": "Probability"}]
返回结果了(命令行也能看到返回什么),我自己定义了三个字段,一个是模型名称,一个是返回的概率值,另一个是返回的数据类型。
这上面都大功告成之后,接下来就是第四步导出了:
这里我只讲win10的docker安装的一些问题:
一.请预留至少10个G的C盘空间,docker本身不大,它的vmdx文件很大(我这里占了7个G)。
二.想要docker_engine跑起来,要么安装linux内核的虚拟环境(wsl2),要么安装hyper-V,hyper-V相对于wsl2运行更慢,但是安装更傻瓜,windows程序和功能里面勾上就会安装重启。

成功起来之后长这样。
确保docker能运行之后,在命令行里输入:
bentoml containerize IrisClassifier:latest -t iris-classifier
bentoml就会自动把你的最新版本的服务容器化为docker的镜像。使用镜像的话可以pull但是这里选择更简单的不需要网络的方式,即把镜像save为tar包:
docker save -o iris.tar
这也就是第五步,在你的电脑上完成的最后一步,时间可能有点久,生成的tar包大概有1个G多大。
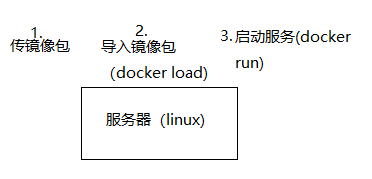
完成之后先把iris.tar远程传到linux服务器的root目录下,
在linux服务器的shell上使用以下命令:
#centos没安装docker的先一键安装docker
#curl -sSL https://get.daocloud.io/docker | sh
#装载镜像
docker load -i iris.tar
#启动服务
docker run -p 5000:5000 iris-classifier:20220110113101_2C47F4
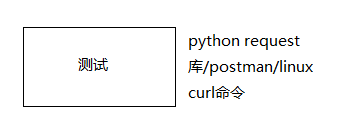
这样就在linux服务器的5000端口上跑起来了服务,可以使用postman和curl命令传参测试。
到此,我们完成了一个模型周期的生产部署,还有很多细节,限于篇幅限制就不写了,希望各位参阅官方文档:
https://docs.bentoml.org/en/0.13-lts/quickstart.html
官方项目地址:
https://github.com/bentoml/BentoML
这是一个非常良心的开源库,希望能有更多的人使用和发展它!