活动地址:CSDN21天学习挑战赛
文章目录
前言
栈和队列是数据结构的基础知识,本文就来分享一波笔者对于栈和队列的学习心得,由于水平有限,难免存在纰漏,还请见谅。
栈
1.栈的概念及结构
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。
栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
- 压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
- 出栈:栈的删除操作叫做出栈。出数据也在栈顶

总括
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入删除数据的
代价比较小。
也可以用链表,要用可以用带头双向循环链表,如果用单链表可以考虑把链表尾部作为栈底,链表头部作为栈顶。要求节省空间时可以考虑链表实现,不过本文主要用顺序表实现栈。

栈和系统栈区的区别
在进程地址空间中有一个栈区,虽然它也具有一些类似于数据结构中栈的特性,比如说后进先出,但是它是内存区域的划分,而数据结构中的栈是一种数据的组织和存储方式,它们两个完全不是一个东西,千万不要混淆了!
概念选择题
1.一个栈的初始状态为空。现将元素1、2、3、4、5、A、B、C、D、E依次入栈,然后再依次出栈,则元素出
栈的顺序是( )。
A .12345ABCDE
B. EDCBA54321
C. ABCDE12345
D. 54321EDCBA
这个就很简单了,栈的特性是先进后出、后进先出,按顺序入栈,出栈的时候就是倒着顺序出,直接可以选出B。
2.若进栈序列为 1,2,3,4 ,进栈过程中可以出栈,则下列不可能的一个出栈序列是()
A. 1,4,3,2
B. 2,3,4,1
C. 3,1,4,2
D. 3,4,2,1
题目只是给定了进栈的顺序,并且进栈过程中可以出栈,我们分别看看这几种情况:
对于A,进1马上出1,然后再连续进2、3、4,最后连续出4、3、2,所以是可能的。
对于B,先进1、2,出2,进3,再出3,随后进4再出4,最后出1,所以是可能的。
对于C,先进1、2、3,出3,这时候栈顶元素就是2,要出栈只能是出2,不可能出1,所以是不可能的,选C。
对于D,连续进1、2、3,出3,进4,出4,然后依次出2、1,所以是可能的。
2.栈的实现
栈结构的声明
因为使用顺序表实现的栈,所以会有很多顺序表的“影子”,对顺序表不熟悉的可以先去看看我写的顺序表的实现。基本上和顺序表大同小异,结构体中用动态顺序表存储栈元素,设置一个栈顶下标,还有一个栈容量变量。
typedef int STDataType;
typedef struct stack
{
STDataType* arr;
int top;
size_t capacity;
}ST;
栈的初始化
没啥好说的,和动态顺序表一样的思路,初始化的时候先不开辟空间,等到push的时候再一起考虑。
void StackInit(ST* pS)
{
assert(pS);
pS->arr = NULL;
pS->top = pS->capacity = 0;
}
栈的销毁
思路和动态顺序表也是一样的,把动态内存释放掉,指针置为NULL,其他成员置为0。
void StackDestory(ST* pS)
{
assert(pS);
free(pS->arr);
pS->arr = NULL;
pS->top = pS->capacity = 0;
}
入栈操作
由于栈的特性决定了元素只能从栈顶进入,增加元素的函数仅此一个,所以检查容量和扩容操作无需另外封装成一个函数,直接包含在入栈操作函数中即可。
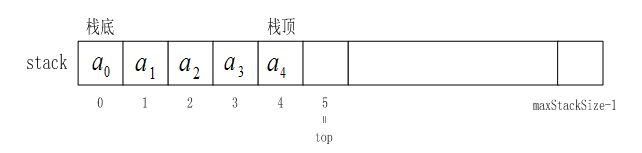
使用top控制元素两种方案,一个方案是top对应栈顶元素的下一个位置,所以其初始值为0,另一个方案是top对应栈顶元素,所以其初始值为-1,我们这里选择使用的是第一个方案。
顺便提一嘴,数据结构的所有操作都推荐用函数封装实现,无论是多么简单的操作,因为这样的话使用者完全无需考虑实现细节,直接就可以使用,最简单的例子就是上面两个方案的选择,有些人选的第一种,有些人选的是第二种,它们在实现的具体细节上是有差异的,但是实现的功能效果完全一样,直接提供函数接口就不需要考虑多种情况。
在检查容量或扩容后接下来就是元素入栈,由于top对应的就是栈顶的下一个位置,所以直接把元素放到这个位置,再让top自增1即可。
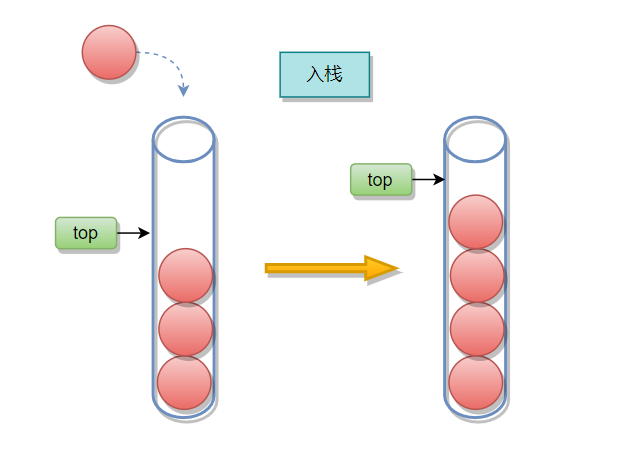
void StackPush(ST* pS, STDataType tar)
{
assert(pS);
//检查是否满容以及扩容
if (pS->top == pS->capacity)
{
int newCapacity = (pS->capacity == 0) ? 4 : pS->capacity * 2;
ST* tmp = (STDataType*)realloc(pS->arr, newCapacity * sizeof(STDataType));
pS->capacity = newCapacity;
pS->arr = tmp;
}
//元素入栈
pS->arr[pS->top] = tar;
pS->top++;
}
出栈操作
删除元素要先看看栈是不是空,可以封装一个检测栈是否为空的函数。
bool StackEmpty(ST* pS)
{
assert(pS);
return pS->top == 0;
}
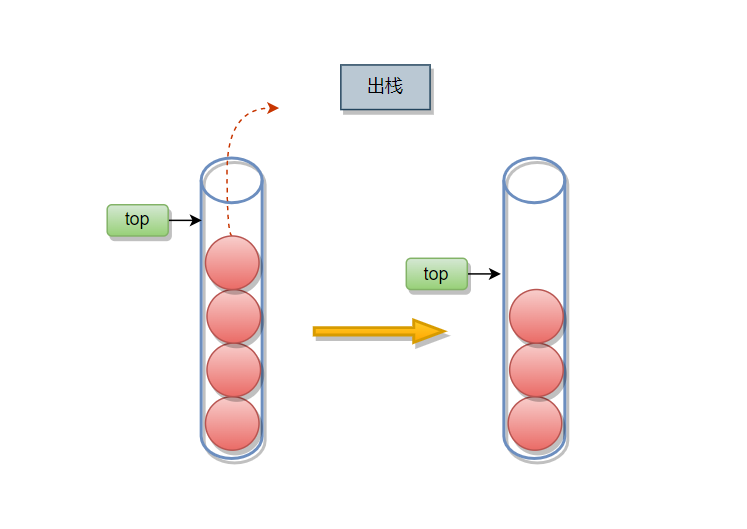
栈不为空,有数据可以删,直接让top自减1即可,上图中看起来是把元素清除掉,实际上并不是,原来的数据还在,只是等待下一次入栈操作将其覆盖。
void StackPop(ST* pS)
{
assert(pS);
assert(!StackEmpty(pS));
--pS->top;
}
访问栈顶元素
根据我们这里的设计,栈顶元素对应下标就是top-1。
STDataType StackTop(ST* pS)
{
assert(pS);
assert(!StackEmpty(pS));
return pS->arr[pS->top-1];
}
求栈的元素个数
根据我们的设计,top既可以表示栈顶元素的下一个位置,又可以表示栈的元素个数。
int StackSize(ST* pS)
{
assert(pS);
return pS->top;
}
队列
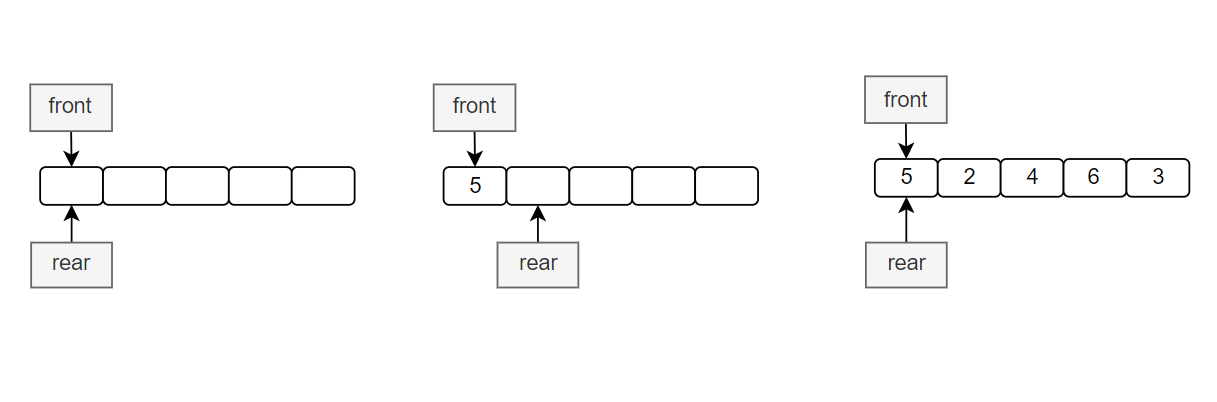
1.队列的概念及结构
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出
FIFO(First In First Out) 队列的特性。进行插入操作的一端称为队尾 ,进行删除操作的一端称为队头 。

2.队列的实现
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数
组头上出数据,效率会比较低 。这里我们就用单链表来实现一下队列。
队列结构的声明
由于我们是用单链表实现的,所以每一个队列元素都对应一个单链表结点,那就会有存值的变量和存下个结点的指针。
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
队列的操作离不开头尾指针,那不妨把两个指针封装到结构体中。我们这里再添上一个成员——size用来实时记录队列长度,为什么这样设计呢?多设计这么一个成员,等到我们要实现函数计算队列长度时就很高效了,如果没有这一成员,估摸着就是要遍历队列求长度了,时间复杂度就是O(n),若是有这么个成员记录队列长度的话,直接返回这个size即可,时间复杂度直接O(1),这不薄纱遍历?
typedef struct Queue
{
QNode* front;
QNode* rear;
size_t size;
}Que;
初始化队列
首先要把队列的两个指针置为NULL作为初始化,这里的assert断言是为了防止传入pQ为NULL,因为传入正常的话是结构体的指针,不可能为NULL,为NULL的话很可能是传入出错,这里就用assert来检测。
void QueueInit(Que* pQ)
{
assert(pQ);
pQ->front = pQ->rear = NULL;
pQ->size = 0;
}

入队列
其实就是单链表的尾插,因为没有哨兵头结点,我们要区分出插入第一个元素的情况和不是第一个元素的情况。
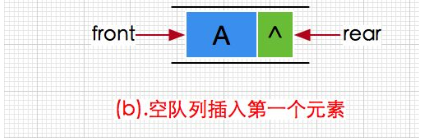
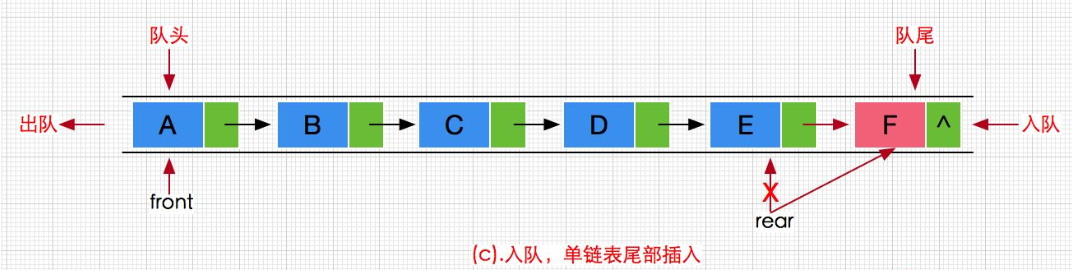
void QueuePush(Que* pQ, QDataType tar)
{
assert(pQ);
QNode* newNode = (QNode*)malloc(sizeof(QNode));
if (newNode == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
//不为空就初始化结点
newNode->data = tar;
newNode->next = NULL;
}
if (pQ->rear == NULL)
{
pQ->front = pQ->rear = newNode;
}
else
{
pQ->rear->next = newNode;
pQ->rear = newNode;
}
++pQ->size;
}
队列是否为空
在实现出队列之前,先实现一个很简单的函数,就是来判断队列是否为空的函数。有多简单呢?队列什么时候为空呀?头尾指针都是NULL的时候不就说明队列里一个元素都没有嘛。这里返回值用bool类型,如果队列为空返回真,不为空返回假。
bool QueueEmpty(Que* pQ)
{
assert(pQ);
return pQ->front == NULL && pQ->rear == NULL;
}
出队列
为什么我们前面要先实现判断队列是否为空呢?你想啊,队列使用单链表实现的,出队列实质上就是头删操作,链表为空时还能再删吗?删不了,所以要检测防止链表为空的情况先。
出队列又怎么出呢?想想单链表头删,先把当前头结点地址暂存一份,然后队头指针指向下一结点,此时再用此前暂存的头结点地址free释放掉之前的头结点。
不过还有一个要注意的点,那就是出队列出到最后一个元素出队列后,队尾指针要记得置为NULL,不然会有野指针问题!
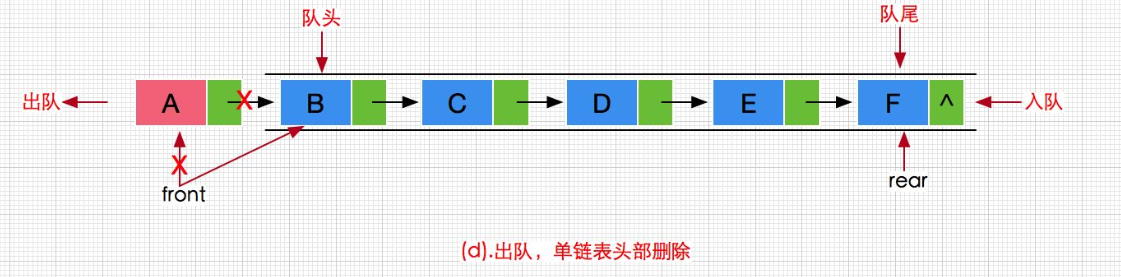
void QueuePop(Que* pQ)
{
assert(pQ);
assert(!QueueEmpty(pQ));
if (pQ->front->next == NULL)
{
free(pQ->front);
pQ->front = pQ->rear = NULL;
}
else
{
QNode* del = pQ->front;
pQ->front = pQ->front->next;
free(del);
}
--pQ->size;
}
获取队列头元素
这个十分地简单,取出队头指针指向元素的值即可,不过要注意检测队列是否为空先。
QDataType QueueFront(Que* pQ)
{
assert(pQ);
assert(!QueueEmpty(pQ));
return pQ->front->data;
}
获取队列尾元素
这个和上面那个有异曲同工之妙,也就是基本一样的思路。
QDataType QueueRear(Que* pQ)
{
assert(pQ);
assert(!QueueEmpty(pQ));
return pQ->rear->data;
}
获取队列长度
欸,这不简单吗?直接返回size不就成了吗?还遍历个啥呀,这波啊,这波是薄纱遍历。
int QueueSize(Que* pQ)
{
assert(pQ);
return pQ->size;
}
销毁队列
实质上就是销毁单链表,没什么别的办法,遍历队列,把结点一个一个释放掉,然后指针置为NULL。
void QueueDestory(Que* pQ)
{
assert(pQ);
QNode* cur = pQ->front;
while (cur)
{
QNode* del = cur;
cur = cur->next;
free(del);
}
pQ->front = pQ->rear = NULL;
}
3.循环队列
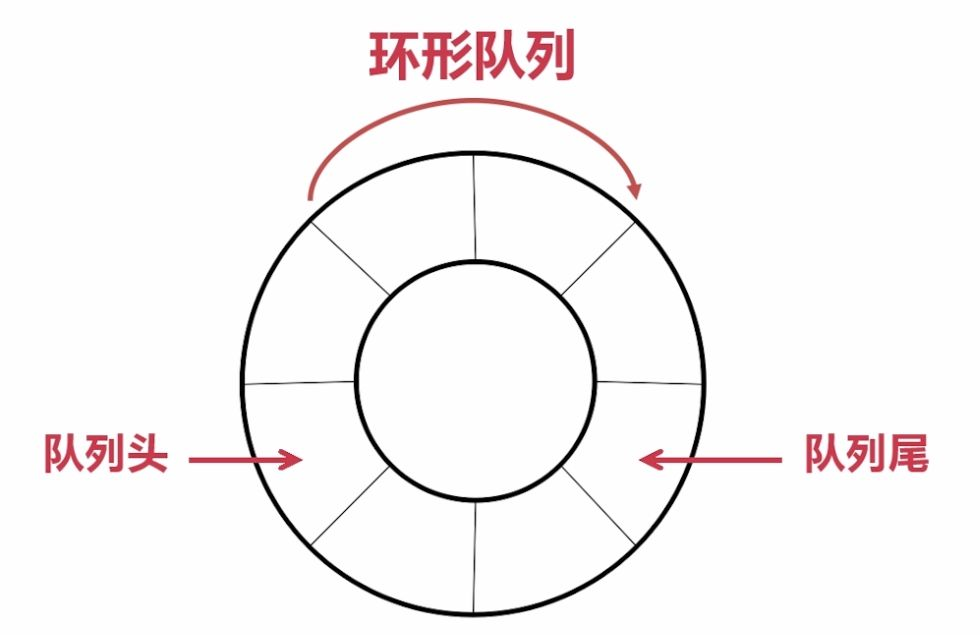
实现所用的结构
用单链表不太好,比如说你要获取队尾元素就要遍历一遍,而用顺序表直接用队尾下标-1即可,还有就是单链表创建起来比顺序表麻烦,要一个一个结点地创建,还要全部链接起来。不如就用动态顺序表的好。
循环队列中的元素插入或删除不改变空间,采取的是覆盖的策略。其实这道题的关键是要准确判空和判满,我们这里让rear指向队尾元素下一个位置,那么问题就来了,我们就无法区分空和满两种状态了。为什么?
如图,空和满两种状态下队头指针和队尾指针都指向同一位置。
解决方法:
- 增加一个size来计数
- 增加一个空间,满的时候永远留一个位置,比如循环队列是4个元素,就开5个空间。
rear位置的下一个位置是front就是满了的状态,front和rear指向同一位置就是空了的状态。不过要注意这是逻辑结构的结论,如图为逻辑结构队列满的状态,但是我们用的是动态顺序表来实现循环队列的,物理结构上却是另一种形态,我们的操作要基于物理结构。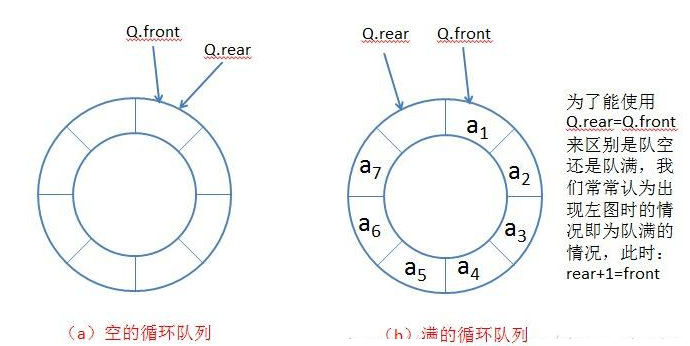
如图,我们要注意如何处理,让rear下标+1后%N,N代表空间总数(包括多开的一个空间),判断结果与front下标是否相等。

选择题练习
现有一循环队列,其队头指针为front,队尾指针为rear;循环队列长度为N-1。其队内有效长度为?(假设多开辟一个空间,实际空间大小为N)
A. (rear - front + N) % N + 1
B. (rear - front + N) % N
C. (rear - front) % (N + 1)
D. (rear - front + N) % (N - 1)
要算有效长度要注意有两种情况,如果rear比front小的话,rear-front就是负数,所以不能直接相减,那怎么把两种情况统一到一个式子上呢?可以让rear和front的差值加上空间总数N再让结果模上N,能防止下标越界,实现逻辑上的循环。所以选择B。

OJ练习题
-
括号匹配问题:20. 有效的括号 - 力扣(LeetCode)
-
用队列实现栈。225. 用队列实现栈 - 力扣(LeetCode)
-
用栈实现队列。232. 用栈实现队列 - 力扣(LeetCode)
-
设计循环队列。 622. 设计循环队列 - 力扣(LeetCode)
