前言
本文基于C语言来分享一波笔者对于排序算法的插入排序中的希尔排序的学习心得与经验,由于水平有限,纰漏难免,欢迎指正交流。
希尔排序
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
为什么又称为缩小增量法呢?我们看看直接插入排序,每次比较元素是不是一个一个单位移动的?其实直接插入排序默认增量(用gap表示)就是1了,也就是每隔一个元素比较一次。希尔排序就是从初始设定的增量开始,对序列进行直接插入排序,然后每排序完一次就让增量gap减小,最后一次就是增量为1的直接插入排序。
步骤:
-
预排序 目的:使序列不断接近有序
间隔为gap的数据分为一组,一共就有gap组,每一轮逐次让各个分组内的数据进行直接插入排序,每一轮结束后都让gap减小。
-
直接插入排序
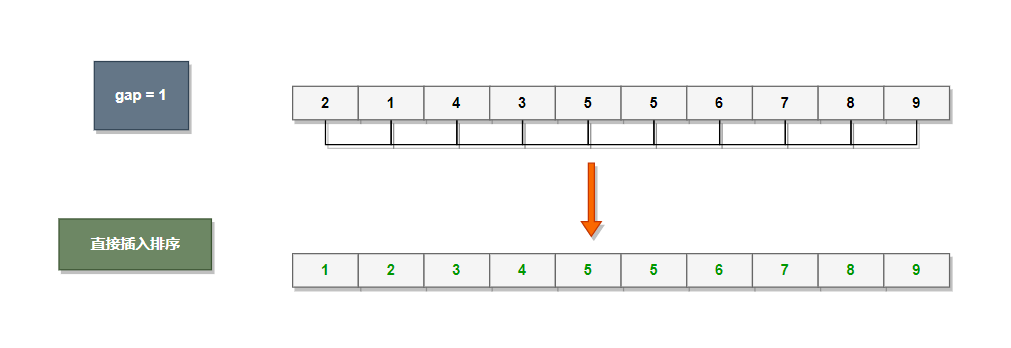
gap减小到1时再进行最后一次直接插入排序。
根据以下示例讲解过程(要求排升序):
我们一开始选定gap为3,然后就有如图的分组,不同颜色的数字代表不同组,实际上每组的排序都相当于直接插入排序改进版,也就是把gap的值从1变成了3。
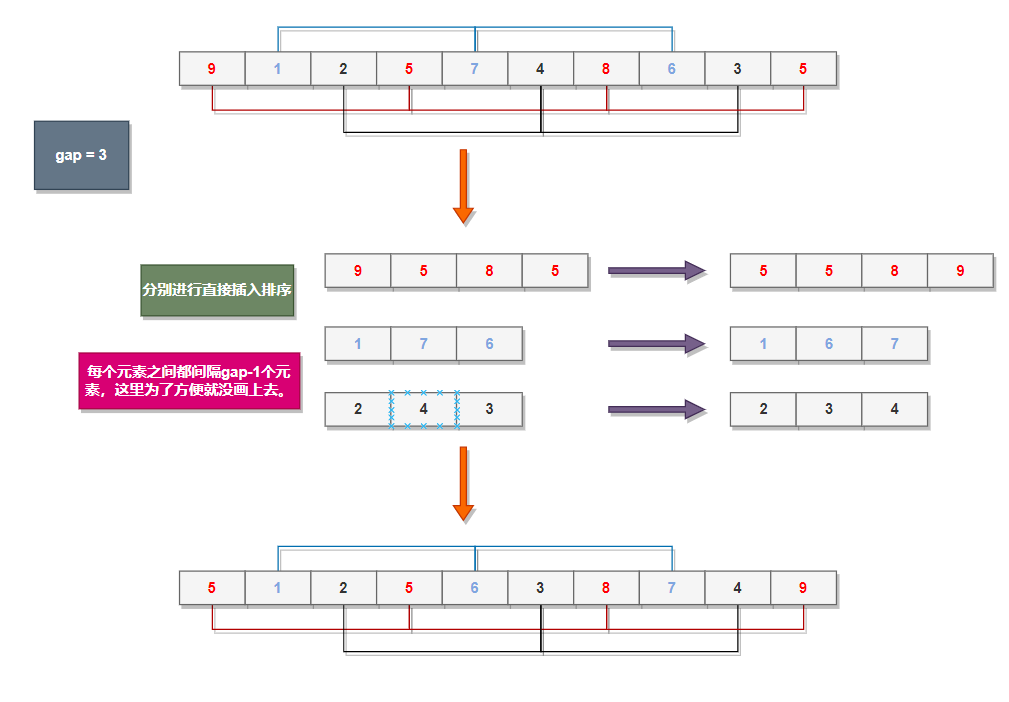
int gap = 3;
//单轮排序
for(int j = 0; j < gap; ++j)
{
//单组排序
for(int i = 0; i < n - gap; i += gap)
{
int end = i;
int tmp = arr[end + gap];
while(end >= 0)
{
if(tmp < arr[end])
{
arr[end + gap] = arr[end];
}
else
break;
end -= gap;
}
arr[end + gap] = tmp;
}
}
我们对于gap的取值这里取初始值为sz / 3 并且每次都gap = gap / 3 + 1 ,加1是为了让gap最后能为1。assert是为了检测arr指针是否为空,正常情况下都不可能为空的。
void ShellSort(int* arr, int sz)
{
assert(arr);
int gap = sz;
while(gap > 1)
{
gap = gap / 3 + 1;
//单轮排序
for(int j = 0; j < gap; ++j)
{
//单组排序
for(int i = j; i < n - gap; i += gap)
{
int end = i;
int tmp = arr[end + gap];
while(end >= 0)
{
if(tmp < arr[end])
arr[end + gap] = arr[end];
else
break;
end -= gap;
}
arr[end + gap] = tmp;
}
}
}
}
我们发现,这样实现的话代码看起来有点…唬人,乍一看这不套了四个循环么?这样是一组一组地完成,有没有方法让代码看起来更"舒心"?
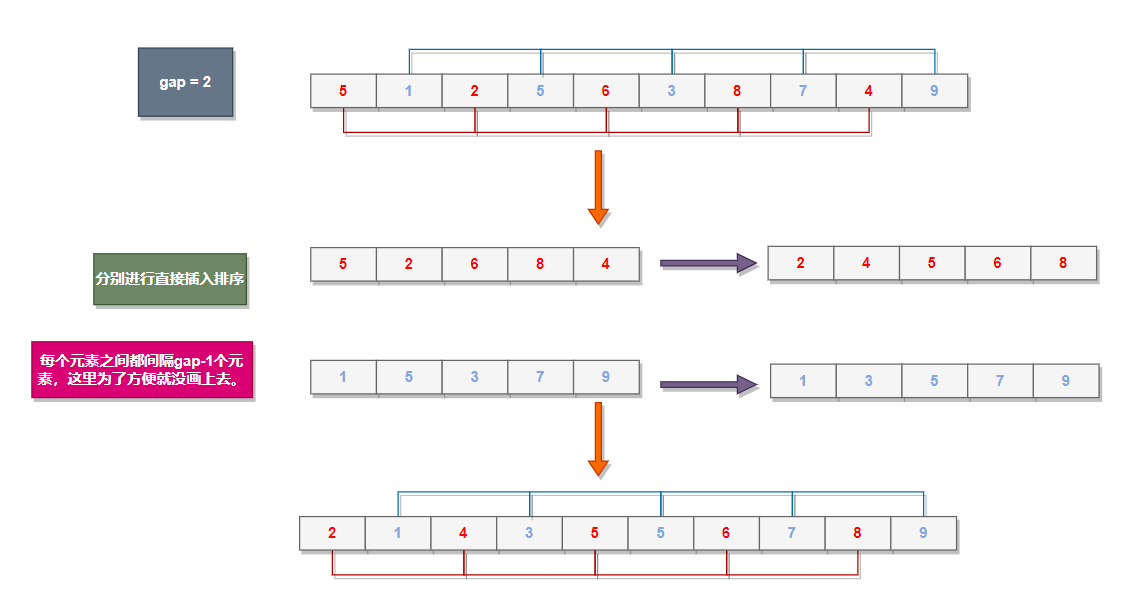
我们可以让gap组数据依次多组并排进行,什么意思呢?就拿下面这张图举例,就让end每次都只向后走一步,遇到红色组的数据就进行红色组的直接插入排序,遇到蓝色组的就进行蓝色组的,遇到黑色组的就进行黑色组的。end每走完一次就是一整轮排序。
void ShellSort(int* arr, int sz)
{
assert(arr);
int gap = sz;
while(gap > 1)
{
gap = gap / 3 + 1;
//单轮排序
for(int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = arr[end + gap];
while(end >= 0)
{
if(tmp < arr[end])
arr[end + gap] = arr[end];
else
break;
end -= gap;
}
}
}
}
我们发现:
gap越大,大的数据可以越快地跳到后面,小的数据可以越快地跳到前面(就比如gap为3的话一次可以跨越三个元素位置来排序,而gap为1的话那就慢多了)。
gap越小,跳得越慢(就比如gap为1的话一次只能隔一个元素来排序),越接近有序。
注意事项:
-
gap>1就是预排序
-
gap == 1就是直接插入排序
-
我们要保证最后一次gap是1,而gap的取值有多种方案,这里推荐
gap = sz / 2和gap /= 2或者gap = sz / 3和gap = gap / 3 + 1。
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就
会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。 - 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些书中给出的
希尔排序的时间复杂度都不固定


因为我们的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,我们暂时就按照:O(n1.25)到O(1.6n1.25)来算,效率和O(nlogn)相近,在数据量大的时候它略逊于O(nlogn)。无论如何,希尔排序都在时间复杂度上突破了O(n2)。
- 稳定性:不稳定
感谢观看,你的支持就是对我最大的鼓励~