字符集
所谓集合是指作为整体看的一堆“东西”,所以字符集的字面意思就是“一类字符(Character)”的集合。字符通常指代类字形单位或符号,包括字母、数字、运算符号、标点符号、其他符号及一些功能性符号。
常见字符集:ASCII字符集、GB2312字符集、BIG5字符集、GBK字符集、GB18030字符集、Unicode字符集等,字符集中主要包含了字符与ID的对应关系。
编码&解码
编码(Encoding)一般指目标信息从一种形式通过一定的规则转换为另一种形式的过程。相对于计算机底层来说,所有的数据在存储与运算时都要使用二进制数表示(高电平为“1”,低电平为“0”),人类若要与其进行“通信”,便需要将自身可以识别的字符集转换为计算机可以识别的“1”和“0”,他们之间的转换关系(即映射)便是所谓的编码过程。
解码(Decoding)则是编码的逆过程。
ASCII
ASCII (American Standard Code for Information Interchange,美国信息交换标准码),包括ASCII字符集与ASCII(编)码。ASCII字符集共128个对象,包括52个英文字母大小写、10个阿拉伯数字、英文标点及一些控制符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示128个字符(扩展ASCII 码则将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号)。’
ANSI
由于许多国家的语言不能使用ASCII进行完整的表示,不同的国家和地区则制定了不同的标准,由此产生了GB2312、BIG5、Shift_JIS等各自的标准(包含字符集与编码方式)。这些使用 双字节或更多字节来代表一个字符的各种ASCII延伸,统称为ANSI标准,有时也称为"MBCS(Muilti-Bytes Character Set,多字节字符集)"。例如,简体中文系统下,ANSI代表GB2312标准;繁体中文系统下ANSI代表BIG5标准,日文系统下,ANSI代表Shift_JIS标准。
Unicode
但由于不同 ANSI标准之间互不兼容(例如,无法将简单的将属于两种不同语言的文字,存储在同一段ANSI编码的文本中),为了解决这些局限,Unicode(又称统一码、万国码、单一码)标准(包含字符集与编码方式)应运而生。它为不同语言中的不同字符设定了唯一的二进制码,用以满足跨语言、跨平台的字符处理需求。
UTF-8、UTF-16、UTF-32等都是Unicode字符集常用的“具体”编码方式(Unicode编码方式只包含一组字符与相应ID之间的逻辑映射,并没有指定代码点如何在计算机上存储)。
UTF-8
UTF-8(Unicode Transformation Format,8位元)是针对Unicode字符集的一种可变长度字符编码(使用1~4字节为每个字符编码),且UTF-8编码是ASCII码的一个超集,其编码中单字节仍与ASCII编码方式相同,使得原来处理ASCII字符的软件无须或只进行少部分修改后,便可继续使用,也正是由于此原因,使得UTF-8编码方式被广泛使用。
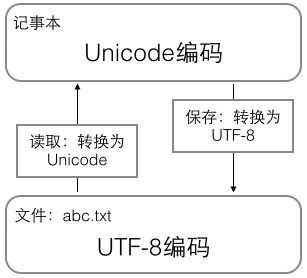

Unicode与UTF-8的转换关系如上图所示。
UTF-16
UTF-16(Unicode Transformation Format,16位元)与UTF-8都属于可变长度字符编码,但好处在于Unicode字符集中大部分常用字符都以固定长度的字节(双字节)存储(其余字符使用两个双字节进行存储),不过UTF-16却无法兼容于ASCII编码。
UTF-32
UTF-32(Unicode Transformation Format,32位元)不同于UTF-8与UTF-16,其是一种固定长度字符编码,对每一个Unicode字符集中的元素都使用四字节进行编码。此种编码方式空间利用率极低,虽然在进行截断操作时较为方便,但相对于UTF-8与UTF-16并没有较大优势。
总结
具体的Unicode字符对应关系,可以查询unicode.org,或者中日韩汉字编码表。