文章目录
编码从故事说起
关于计算机的字符编码,很多人都是一知半解的,笔者遇到过做了几年开发的程序员,还是说不清字符编码是什么,乱码又是怎么回事,实际上笔者早期也说不清个所以然,后来有一次做一个自己的app,期初用Java写了一个二进制字典文件的解析器,但是在性能和内存使用方面不甚满意,那时候安卓手机配置还比较低,但是一个外语字典动辄一两百M,所以我又将关键解析部分的代码用C语言重写了一遍,再使用JNI去调用,这时候就遇到了前所未有的大坑,因为一直写Java、Python这类高级语言,这类语言屏蔽了很多二进制流编解码的问题,往往一个函数就能直接将二进制字节转为想要的字符串,而C语言则麻烦得多,当时需要被解析的字典文件编码根本不确定,有的是GBK,有的是UTF-16,甚至还有ISO编码等等,经此一事,查遍资料,最终成功的解决了问题,同时也让我对字符编码问题有了深入理解。这也让我明白了一个道理,不懂C语言的程序员根本不懂计算机,因此我一直推崇程序员要会C语言,否则成不了高手,你会缺乏遇到问题透过现象直指本质的能力。
要说这个字符编码,咱们首先得讲一个故事,帮助不同基础的人理解。
话说六年级二班有小明、小红两位同学,最近班上开了英语课,学着学着有些无聊,这时候小明想给小红传纸条,但是又担心被发现,突然小明灵机一动,在草纸上写下了一串数字12 9 11 5 21,然后就传给了小红,小红看了一眼莫名其妙,这时候小明冲着小红指了指自己英语书后面的字母表,小红看了几眼字母表,顿时明白过来,原来字母表上面有编号,小红按照编号,将这一串数字转换出来,得到的是like u,羞得小红脸色发红,这可真成了“小红”……
这之后小明、小红经常玩这种传纸条的游戏,可是有一次纸条掉到地上,让旁边的狗蛋同学捡到了,起初狗蛋不明所以,可是渐渐的狗蛋同学居然看出了门道,毕竟联想到他们天天翻的字母表,很容易就破解了,狗蛋同学不知道哪来的一股无名火,存心搞个恶作剧,于是冒充小明同学,也用这种方式写了些内容传给小红,这可倒好,气得小红扭过头不理小明同学了。下课后,小明好说歹说才把事情解释清楚,小明又想,传纸条还得把规则弄复杂一点,只有自己两个知道,别人都破解不了,于是小明小红约定,在原来字母表编号的基础上,做一个简单变换,公式是乘2加7,例如原来的12对应字母l,那么现在要先计算,12*2+7就是31,对方收到后再做一次逆运算,那就是(31-7)/2
从这之后,小明小红的纸条再没被人破解过,与此同时,六年级二班兴起一股玩传纸条游戏的风,到后来,不仅仅是对字母编号,还把常用的几十个字也做了编号,编号从26之后开始排,因为要保留前面26个字母。可是班上的小团体,各有各的计算规则,有的是把字母表编号做加2变化,有的是做加5,这样一来相互之间都解不出来,有的强行按照自己的规则解出来是错乱的,有的根本解不出来……
以上故事中,我们把字母或汉字转换成对应的一串数字的过程,就是所谓编码,再将数字恢复成原来内容的过程,也就是所谓的解码。一旦编码和解码的方式不一致,就会产生我们常见的乱码。对于编码、解码和乱码三个概念,相信大家已经有了一个本质的理解了。其实这一点我们在谍战剧中也经常见到,假设地下党约定用新华字典做密码,密文是110页第3行第5个字,结果你用康熙字典去解码,翻到110页第2行第5个字,那肯定就乱码了。
计算机的字符编码
现在回到计算机世界的字符编码问题,要弄清楚计算机字符编码问题,咱们还得继续讲故事。
在计算机中,一切数据都是以二进制的形式存在,对于我们人类而言,二进制是比较难以理解的,人类最容易理解的是十进制,但是二进制转十进制也非常方便,这样一来,我们其实可以把计算机存储的数据简单理解为一些数字。
既然计算机只能存数字,那我们电脑里面存的文档又是怎么回事呢,文字字符这些是怎么来的?其实这个也很好理解,这就像我们一开始讲的小明小红的故事一样,我们只需要给每个字符一个编号,计算机不是只能存数字吗,那就把这个编号存起来,当我们需要显示的时候,再去解码,让显示器把这个编号转换成对应的字符显示到屏幕上就行了。
在小明小红的故事中,编码的目的是为了加密,不让其他人知道密文的意思,而计算机编码的目的则是因为它只能保存数字。
ASCII 码表
现在我们理解了字符和编号之间的一一对应的关系,那就只需要制作一份表格,将每个字符都进行编号,保证每个字符编号的唯一性,这样就彻底解决了让计算处理字符的问题。
不错,业界前辈们也是这个思路,于是在 20 世纪 60 年代,美国人就制作了一张这样的表,被称为ASCII 码(American Standard Code for Information Interchange,美国信息互换标准编码)表
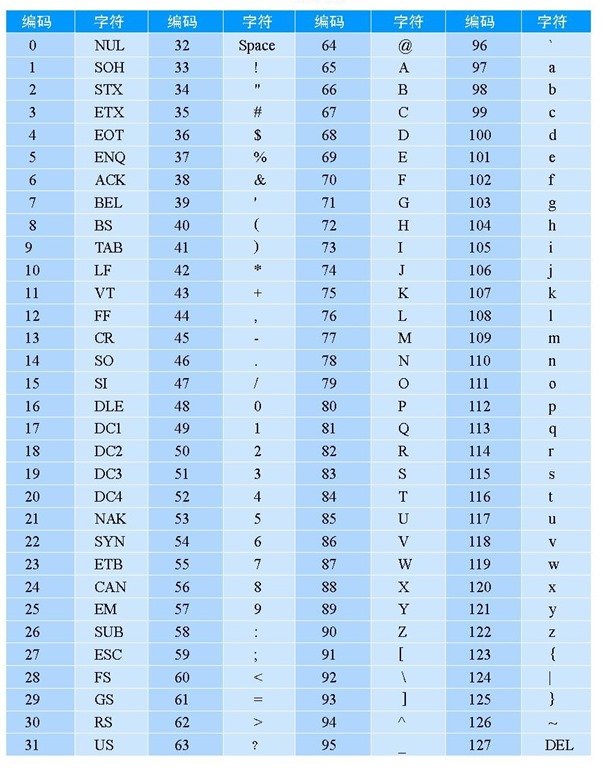
该表编号从0~127,总共表示了128个字符。这个表不仅将26个字母的大小写字符都包含进去了,还包含了很多其他的老美们认为常用的字符,这才凑够了128个,为什么要凑够128呢?这又是另一个故事了,我们知道计算机中是二进制,那个年代,硬件非常差,为了节省空间,他们规定只用一个字节保存字符的编号,那么一个字节是多大?一个字节就是8位二进制,最高位是符号位,所以7位有效,那最大也就是2的7次方,正好就是128。如果对字节不是很理解,只需把它当作一个容量大小单位即可,比如我们常说的U盘多少M,文件多少K就是这个东西,1K就是等于1024个字节大小。关于二进制的知识,请阅读我的另一篇文章。
ASCII 码表被发明之后,老美认为完美了,毕竟计算机是美国人发明的,他们当时哪去管世界上其他国家的文字。在整个欧洲的拉丁语系中,没有一种语言的字母会超过128个,所以当时看确实是足够了。后来计算机在全世界的范围内得到了极大发展和普及,可是计算机却只能使用英语,人们不能使用自己的母语,曾经中国人一度怀疑中文的缺陷,甚至担忧继续使用中文不能进入信息化时代,因为当年中文是不能录入计算机的。
GB2312 ——中国人自己的编码表
这些问题毕竟难不倒聪明人,既然一个字节表示的范围太小,那我们中文可以用两个字节表示嘛,一个字节8位。两个字节就是16位,能表示的最大范围是2的15次方,十进制就是32768,能表示3万多汉字呢,这样一来,我们就解决了计算机表示中文的问题。
最早制定的编码方案称做GB2312编码,全称叫做《信息交换用汉字编码字符集》,它是国家标准总局1980年发布的。当年考虑得非常不充分,GB2312编码仅仅只收录了6763个汉字和中文标点符号等等之类的图形符号682个。经历过的人应该都体会过,自己的名字在电脑里打不出来的痛苦,政府办事,银行开户等等,要怪就怪这些制定标准的老爷们,常用汉字就有七千多个,六千多汉字怎么可能够用嘛。
我们来看看中文编码的缺陷,那就是比英语更占空间。简单算一算,一个汉字占两个字节,那么1K空间,只能存512个字,而1K空间可以存1024个英语字母。
中国人虽然发明了自己的编码表,但是也不敢完全自己玩,还是得跟美国人接轨的,这就体现在GB2312兼容ASCII码表上,简单说,就是ASCII码表中0~127的编号得保留下来,中文得从后面的编号开始排。
GBK 编码
GB2312编码表是真的不够用啊,随着计算机在各行业内的应用,汉字不够用的窘迫也日益突出,最终在1995年12月1日制定了GBK编码,全称《汉字内码扩展规范》。它在GB2312的基础上收录了21003个汉字。
因此,GBK编码是包含GB2312的,当我们需要指明解码方式时,完全可以使用GBK代替GB2312,也就是说我们可以忘掉GB2312了。
要查看GBK编码表的内容,可访问 GBK编码表,亦可查看微软的 page 936表,GBK在Windows中使用page 936表示。
GB18030
在GBK之后,我国又推出了GB18030-2000和GB18030-2005,分别在2000年和2005年发布。它支持ISO国际标准,即 Universal Multilpe-Octet Coded Character Set(简称UCS)
关于支持ISO国际标准这个事,我们得好好说道说道。很多人写的博客资料在这一块都是一笔带过,大概是摘抄的,自己也没弄清楚是怎么回事,然而这是一个关键点。
其他编码
这个故事呢,还得从ASCII码之后的国际形式开始说。话说美国人制定了ASCII码之后,其他国家也日益觉察到计算机的重要意义,都在琢磨着如何将自己的母语录入到计算机。
ISO-8859-1
最简单的当然是欧洲啦,毕竟不管是欧洲哪国语言,字母都不会太多,于是就有了西欧字符集ISO-8859-1。这个ISO-8859-1编码当然也是兼容ASCII码的,所以它的编号也只能从127之后开始排。但是欧洲人想,咱们欧洲字母那么少,不可能用两个字节去存吧,太浪费了,于是开动脑筋,使用无符号8位二进制,一个字节8位,通常只有7位是有效位,但是字符编码,不可能有负数啊,只需要正数就行了,于是将8位都变成有效位,能表示的范围瞬间提升了,最大能表示2的8次方减1,那就是255,255-127是128,也就是说ISO-8859-1除去ASCII码的127个字符,还能存128个欧洲字符。该字符集能支持大部分于欧洲语言,以及欧洲之外的南非荷兰语、斯瓦希里语、印尼语、马来语等。
Shift_JIS 和 Big5
当然,日本人也发明了自己的编码表,用以显示日文,同样也会兼容ASCII码,这就是Shift_JIS编码,而港台地区使用繁体中文,也制作了自己的编码表,称为Big5编码。
各个都做了自己的编码表,但是在互联网时代却出现最尴尬的一幕,那就是无法互通。以前都是单机时代,自己玩自己的也无所谓,可是90年代互联网兴起后,情况就变得不一样了。大家想像一下,如果你有一个日本网友,你怎么给对方发信息?我们说了,字符在计算机中不过是一串编码数字,在网络中传输的也只是这串编号而已。如果你的电脑是用GB2312编码,那么你只能输入中文,发给对方的只是一串GB2312的编号,对方电脑用Shift_JIS编码表将编号转换后,得到必然是一串乱码。
当然,除此之外,也还有其他尴尬的事情,比如你是一位日语老师,你用电脑写教案,肯定是需要中文、日文混排的啊,但是GB2312和GBK显然满足不了,因为它是纯中文编码,它里面只有英语字母和中文,根本没有收录日文呀。
该如何解决这个问题呢?
明白了问题的本质,其实解决起来也很简单。问题的根本原因就是大家各自为政,互不兼容,解决的办法很简单,那就是将全世界的所有语言文字全部放在同一张表里。这样一来,每一个字符都有一个唯一的编号。中文也好,日文、韩文也罢,每个字都有唯一的一个编号,不可能像以前各自为政一样,出现两个字符使用了同一个编号的情况,从此之后再不会出现乱码。
当然,不会出现乱码还是不太可能,但那是另一个故事了,接着说统一编码的事。聪明人不止一个,想到这个办法的当然也不止一个了。
UCS
通用字符集(Universal Character Set),是由ISO制定的ISO 10646编码方式。ISO是国际标准化组织,主要就是定制国际通用标准的。UCS包含了已知语言的所有字符,它的第一个版本发表于1993年。
Unicode
也被称为统一码、万国码,它包括字符集、编码方案。它为每种语言中的每个字符设定了统一并且唯一的编码。它于1990年开始研发,1994年正式发布,最新版本是Unicode 12.1,于2019年4月1日发布,共收录137,929个字符,查看更多 请访问 Unicode官网
整合
同时出现了UCS和Unicode,这反而使问题变得糟糕。人们发明统一编码表的目的,就是为了统一,而不是为了添乱。后来他们双方都意识到了问题,所以双方开始进行整合,到unicode2.0时,unicode编码和UCS编码基本一致了。注意,只是他们的标准合并了,这两个组织可没有合并,仍然独立存在。
到这里,大家终于明白GB18030支持国际标准ISO/IEC10646-1的意义了吧,它使得GB18030包含全部中日韩汉字,以及BIG5编码中的所有汉字。但是请记住,它仍然是一个仅适用于中文汉字的编码。简单说它的区别,就是GB2312和GBK完全是关起门来自己造的编码表,而后续版本GB18030则是在原来基础上注意与国际接轨,字符编号不再是自己随意排了,但是它也仅仅只包含汉字,解决不了我们上面提出来的互联网时代信息互通的问题。
最后做一点澄清,很多资料和博客不负责任的乱写,比如经常看到有人写GB2312、GBK也属于Unicode,或者写它们在Unicode下制定,或者说遵循Unicode,这基本等同于扯淡了,我们已经详细了解了它们的来龙去脉,GBK与Unicode没有一毛钱关系。倒是GB18030,它支持了ISO的UCS字符集,而UCS和Unicode标准已经合并,因此它与Unicode是有关系的。
我们应当如何去看待这些编码表呢?其实没有那么复杂,GB2312或者GBK它是中国人自己的编码,是地区性的,而Unicode是国际的,就这样看待就很Ok了。正常来讲,有了Unicode,以前的那些编码理应废弃淘汰掉,从此再不会有乱码问题。可是谁让那些地区性编码出现得早呢,使用了那么多年,已经深入到了方方面面,不是说废弃就能废弃的,牵扯面广啊。另一个更重要的原因,得算到微软头上!微软的Windows系统几乎占领了全世界绝大多数的桌面电脑,可是微软却非常坑爹的坚持使用地区性编码。什么意思呢,简单说就是,中国的Windows系统就指定使用本土的GBK编码,日本的Windows系统使用日本本土的编码。这就是大家Windows电脑经常出现的乱码的一个重要原因。
UTF-16、UTF-32、UTF-8
有了Unicode码表,似乎所有的问题都解决了,可是为什么又出现了UTF-16、UTF-32、UTF-8这些东东呢?
不要急,且听我慢慢道来。Unicode码只是一张表而已,规定了每个字符对应的编号,可是在计算机中该如何去具体实践它呢?大家想一想,以前的地区性编码表所表示的内容毕竟有限,而Unicode可是包含了全世界所有已知语言的文字啊,因此在具体的存储方案上一直存在问题。
先说说Unicode与UTF-16、UTF-32、UTF-8这些概念的关系。Unicode就相当于一本菜谱大全,定义好了不同菜的配方,UTF-16、UTF-32、UTF-8这些就相当于一个个具体的厨师,做同一道菜,不同的厨师手法也还是不同,出来味道也不同。从这一点我们就能看出,UTF-16、UTF-32、UTF-8这些都是同一个门派,练的同一种武功,这和前面讲的GBK、Big5那些根本不是一回事。
UTF-16、UTF-32和UTF-8的区别
UTF-16
UTF-16是早期对Unicode码表的一个实现版本,一开始它规定用两个无符号字节也就是16位二进制来表示全部字符。那么最大范围也就是2的16次方,可是随着Unicode表收录的字符不断增加,早期才收录六万多个,现在早就远超这个数量,因此2个字节不够用了,没办法,后来就规定使用2或4个字节来存储Unicode码,就是说2个不够用的时候就用4个字节。注意,使用两个字节的UTF-16在USC那边还有另一个名字USC-2。 要记住UTF是 Unicode TransferFormat的缩写,它是Unicode这边的叫法,虽然我们前面讲了USC和Unicode标准合并的事,可是人家两个组织还独立存在呢,所以说啊,这些组织尽给我们找事。

比如在有些工具里,我们只看到UTF-8,却没看到UTF-16,为什么呢?因为这会人家叫另一个名字UCS-2
现在来说说UTF-16的缺点吧,最大的一个缺点就是不兼容ASCII 码。不要惊讶,它真的不兼容ASCII 码,一开始我们就讲了,ASCII码用一个字节表示,UTF-16呢,规定死了必须用2个或4个字节,因此不兼容1个字节的ASCII 码。对于ASCII 码它是用两个字节存的。另一个缺点就是字节乱序问题,它存在大小端问题,也就是所谓的Big Endian和Little Endian问题,简单说就是不适合在网络中传输,很蛋疼,曾经让我非常恼火。在C语言中,它就是所谓的宽字符,要想说清楚这些问题,非得拿C语言写代码举例子不可,此处省略……
最后一点总结,UTF-16算是个历史遗留问题,只有一些很老旧的文档或软件工具会用这种编码,现在的一些新东西如果不考虑兼容以前的老系统,不会再用它了。
UTF-32
顾名思义,就是固定使用4个字节32位来表示Unicode码,当然,它在USC中的另一个名字就是USC-4。说实话,这种编码很难流行,因为它同样不兼容ASCII 码,更过分的是它用4个字节去存ASCII字符,比UTF-16更甚,彻底受到欧美人的唾弃!
你想一想,老外以前ASCII码占一个字节,假如以前写的一篇文档是10K大小,现在突然就增加到4倍,变成40K,这谁受得了。可是事物也有两面性,既然被发明出来,肯定也是有优势的,除了占空间外,使用固定4字节大小,可以让计算机处理字符的速度更快,这对一些搜索处理很有利。
UTF-8
好了,最后终于轮到今天的主角UTF-8了。UTF-8是目前使用最广泛的一种计算机字符编码方式。目前被认为是对Unicode码最好的实现方案。简单说它就是Unicode门派最杰出的弟子。
UTF-8是一种变长编码,它跟上面两种的区别就是,它存储字符的大小是不固定的,它使用1~4个字节大小来存一个字符,它可以完全兼容ASCII码的。存储ASCII码时,它使用1个字节,中文则大多是使用3个字节来存,这样的好处就是可以大大节省空间。
在欧美人主导的世界范围内,这种编码方式非常受欢迎。但是在汉字为主的东亚范围内,人们仍然会犹豫,甚至有人认为这是一种文化歧视或文化不公。因为汉字在以前的GBK中或UTF-16中,都是以2个字节大小来存放,而UTF-8则使用三个字节,这就导致汉字使用UTF-8编码后,会占用更多空间,文件也会变大,而与此同时,使用ASCII码的欧美人却不会有任何影响。
无论如何,在互联网时代,UTF-8都是一种非常优秀的解决方案,现代的新兴编程语言,也都默认使用UTF-8作为源代码文件的指定编码。如Golang、Dart、Python3等。在Mac OS和Linux系统上,UTF-8也是默认的编码方式。因此,在Linux上写的文件,传到Windows系统上直接使用记事本打开,中文就会乱码,Windows默认编码是GBK。这里大家要记住,英文字母作为ASCII码字符,绝大多数时候都不会乱码,因为大部分编码方式都会兼容它,这就是为什么建议新手程序员,不要写中文路径,不要写中文注释的原因所在。
什么是带BOM的UTF-8?
在Windows系统上,许多Windows程序(包括Windows记事本在内)在保存为UTF-8时,会在文档的开头添加字节0xEF,0xBB,0xBF,这是Unicode字节顺序标记,通常称为UTF-8 BOM。注意,Unicode标准既不要求也不建议使用BOM,说白了这就是Windows系统埋下的坑!如果你在Windows系统上保存了UTF-8 带BOM的文档,那么在Linux或Mac OS上可能会无法正确识别。因此,非常不建议使用Windows自带的记事本去编辑源代码,甚至其他文本文件也最好不要用它编辑,因为其他平台都是使用不带BOM的标准UTF-8编码方式。
字符编码与编程
在早期,编程语言刚被发明的时候,几乎都是只支持ASCII码的,例如经典C语言,Python2等,因此在编写源码代码的时候,不能写中文注释,因为源代码是不支持这种非ASCII码字符的,这也是Python2的一大缺点。后来出来标准C语言,拓展了多字节和宽字符的概念,这才使得C语言能适应全世界的不同地区字符。Python2也提供了补救措施,需要在源码开始处手动设置一些环境,以支持中文字面量。直到Python3出来后,默认使用utf-8作为编码方式,这才彻底解决了Python2字符串关于乱码和编码转换的痛苦。
关于编程中字符乱码的问题,在后面的具体编程语言的章节中再详细讨论。
欢迎关注我的公众号:编程之路从0到1
