1、为什么要使用批归一化
在训练深度学习模型过程中 当我们更新之前的权重时 每个中间激活层的输出分布在每次迭代中都会发生变化 为了防止这种情况的发生 就需要修正所有的分布 就是说 如果遇到一些分布移位的问题 我们不应该让它们移位 以帮助进行梯度优化并防止梯度消失 这将有助于我们神经网络更快的进行训练
分布变化怎么了 网络不可以学吗?
1、如图所示 BN可以让数据分布到梯度敏感区域 可以进行高效的更新
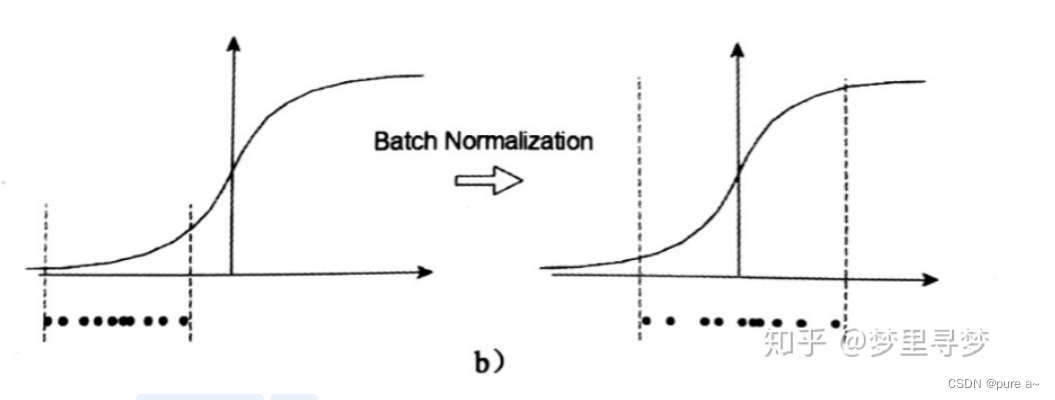
2、神经网络本身就是为了学习数据的分布 如果训练集和测试集的分布不同 那么导致学习的神经网络泛化能力大大降低 再用mini-batch训练网络的时候 不同batch的数据分布也有可能不同 那么网络就要在每次迭代的时候都去适应不同的分布 这会大大降低网络的训练速度
如何实现?
通过减去批次上的经验均值除以经验标准差来归一化前一个输出层的输出(在没有处理的时候计算均值 标准差?)使得数据看起来像高斯分布
训练的每一层 BN的计算过程如下

得到数据样本的均值-》得到数据样本的方差-》减均值 除方差-》变换重构输出y
为什么要有变换重构?
如果仅仅使用上面的归一化公式 对网络某一层A的输出数据做归一化 然后送到网络的下一层B 这样是会影响到本层网络A所学习到的特征的
比如 网络中间某一层学习到特征数据本身就分布在S型激活函数的两侧 强制把他归一化处理 标准差限制在1 把数据变换成分布于S函数的中间部分 相当于把这层网络学到的特征搞坏了 所以会增加变换重构 保留网络学习到的特征
使用场景:
网络训练的时候遇到收敛速度很慢 梯度爆炸等无法训练的情况 可以使用BN来解决
为什么?
解决网络收敛速度慢的问题-》因为BN可以让数据 集中到激活函数梯度大的地方 来使得参数更快的更新
解决梯度爆炸的问题-》在反向传播的过程中 每一层梯度都是由上一层乘以本层的数据得到的 如果归一化的话 数据均值都在0附近 所以不会产生梯度爆炸的情况
预测阶段如何做归一化?
测试阶段没有mini-batch 一般只输入一个测试样本查看结果 那么在测试的时候如何得到均值和标准差 ??
网络一旦训练完毕 参数都是固定的 这个时候即使每批训练样本进入网络 那么BN层计算的均值和标准差都是固定不变的??
在测试的时候 使用所有训练数据的均值 训练数据的标准差
好处:
收敛更快
降低了初始权重的重要性
对超参数的鲁棒性
泛化所需的数据更少
缺点:
导致训练时间增加
不适用于循环神经网络
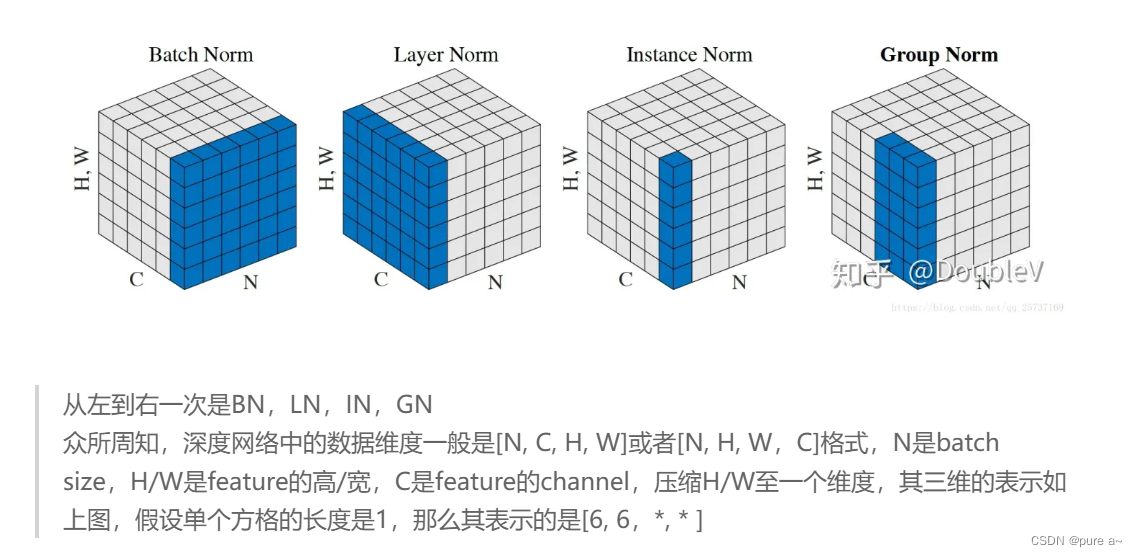
其他类似的方法
层归一化
实例归一化
组归一化(+权重标准化)
同步归一化
要与参数初始化问题进行区分、
参数初始的不好
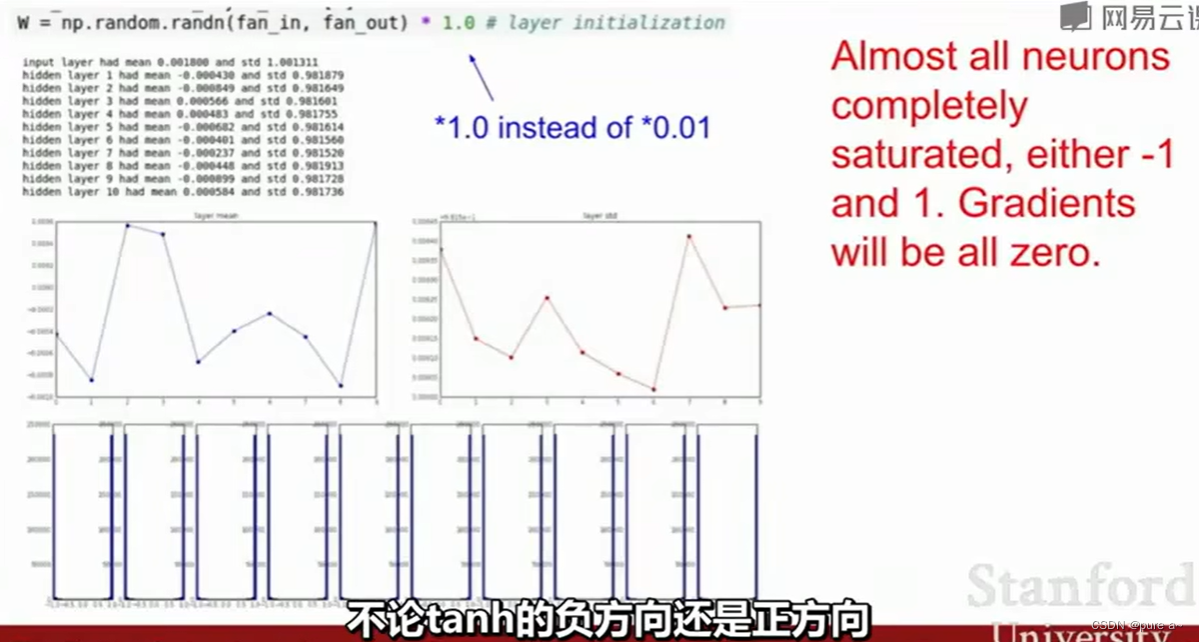
参数初始的好
相同点:二者都是缓解梯度消失 梯度爆炸问题
不同点:参数初始化时为了让参数不至于过大或者过小 可以经过激活函数后仍具有较好的分布
BN是为了保证每一层的输出都符合标准分布 可以保证网络学到更好的特征
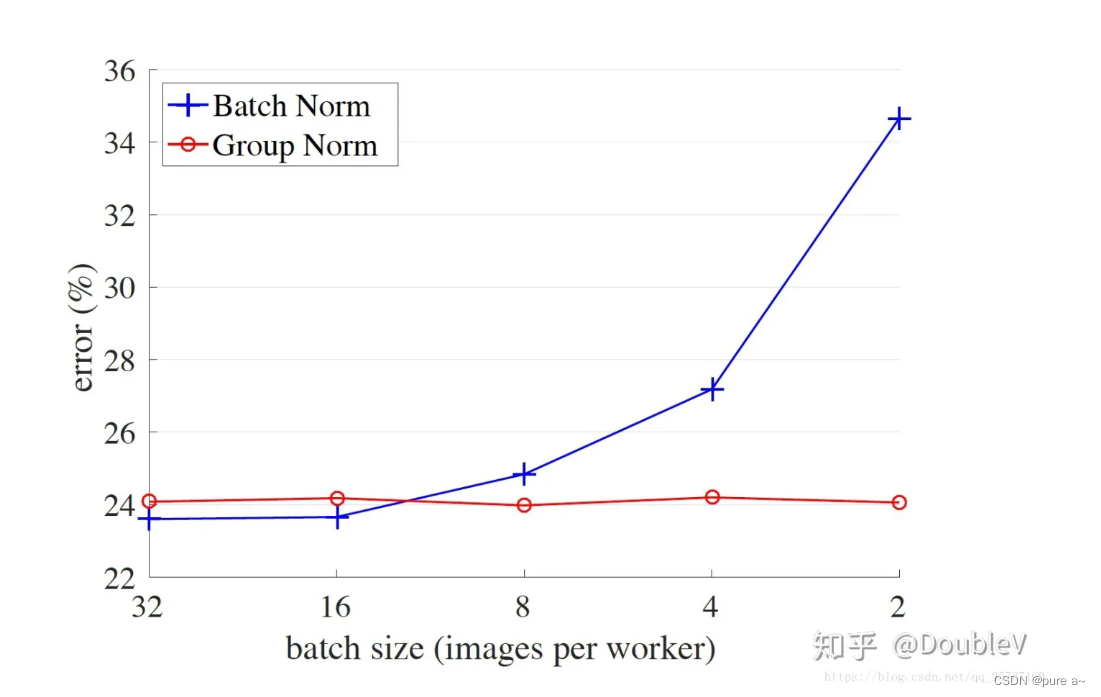
批归一化和batchsize的关系
为什么要有GN?
因为LN在卷积层中表现不好
还有就是 BN对batchsize的依赖过大 较小的batchsize其表现性能不好