Normalization之BN, LN, IN, GN

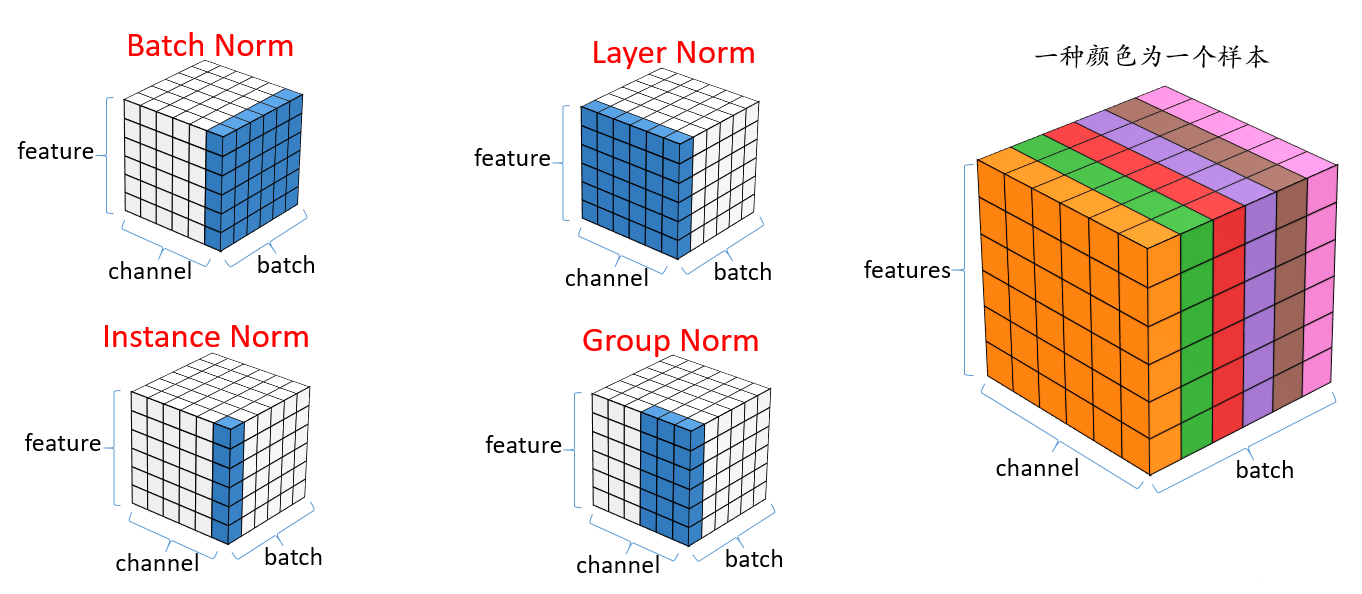

Batch Norm:
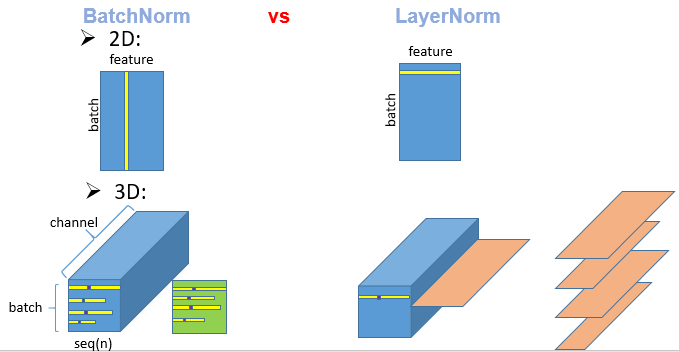
和batch norm对比一下说明什么是layerNorm,以及为什么我们在这些变长的应用里面不使用batchnorm
2D: 考虑最简单的情况:二维输入,二维输入是一个矩阵,每一行是一个样本,每一列是特征;batchNorm所干的事情就是每一次,把每一个列(即每一个特征),把它在一个小mini-batch里面把它变成均值为0,方差为1.那如何把一个向量变成均值为0方差为1呢? (x-μ)/σ 白化,标准化,规范化 pytorch的官方文档中还会加在分母加epsilon,防止分母为0,有助于训练的稳定性,还会用γ,β来进行一个仿射变换(γβ为可学习量),大致思路就是上面的
Layer Norm:
layerNorm和BN很像,layerNorm干的事情就是对每个样本,即每一行变成均值为0,方差为1,可以认为layerNorm是把整个数据转置一下放到BN里面计算后再转置回去一下
3D: 上面是在输入是二维的情况下,而在我们的Transformer或者RNN里面,输入的是一个三维的,因为它输入的是一个序列的样本,每一个样本里面有很多个元素,你给一个句子,里面有n个词,每一个词对应一个向量的话,还有一个batch的话,那就对应一个3D的东西。
N: 列不再是特征了,而是序列的长度,每一列代表一个序列,相当于一个样本句子?把它的整个序列的元素以及它的整个batch全部搞出来,把其均值搞成0方差变成1,就是如下图切出来一块绿色的,然后拉成一个向量,然后和之前做一样的运算 LayerNorm: 的切法为:橙色的切片
NLP中会用到LayerNorm,而很少用到BatchNorm
Instance Norm:
用于风格迁移上,per sample, per channel,对每个样本的每个维度单独去算均值和方差
Group Norm:
GroupNormalization :何凯明提出来的,解决BN的一些问题,和LN最像,需要先对channel划分为group,就像群卷积中一样(把输入通道划分为不同的group),和batchsize是无关的
Batch Normalization是在batch这个维度上Normalization,但是这个维度并不是固定不变的,比如训练和测试时一般不一样,一般都是训练的时候在训练集上通过滑动平均预先计算好平均-mean,和方差-variance参数,在测试的时候,不再计算这些值,而是直接调用这些预计算好的来用,但是,当训练数据和测试数据分布有差别时,训练机上预计算好的数据并不能代表测试数据,这就导致在训练,验证,测试这三个阶段存在inconsistency。
而GN介于LN和IN之间,其首先将channel分为许多组(group),对每一组做归一化,GN的极端情况就是LN和I N,分别对应G等于C和G等于1
GN优于BN,LN,IN