文章目录
一、BN(Batch Normalization)
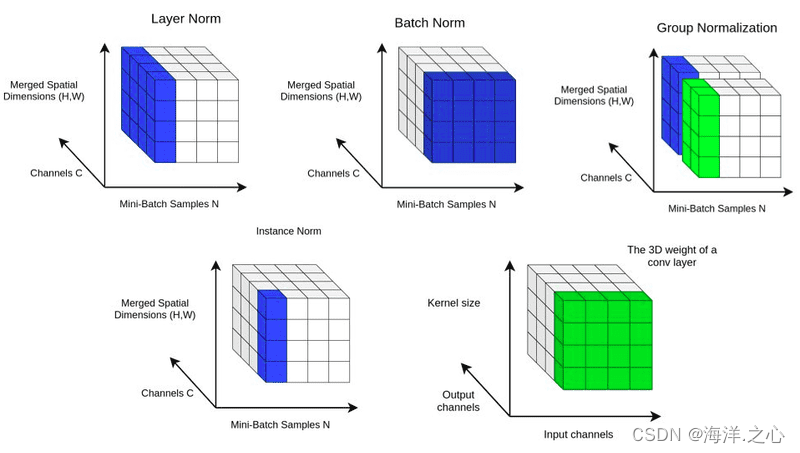
批量归一化(Batch Normalization,BN)是一种用于深度神经网络的正则化和优化方法。它通过对每一批训练样本的特征进行归一化,使得网络在训练过程中更稳定,加速收敛,同时还能够一定程度上克服梯度消失问题。下面是批量归一化的工作原理和步骤:
-
批量归一化操作: 对于每一批训练样本,在卷积层或全连接层的输出上进行归一化操作。
-
计算均值和方差: 对于每个特征通道,计算当前批次样本在该通道上的均值和方差。
-
归一化: 使用计算得到的均值和方差对当前批次的每个样本进行归一化操作,将特征值调整为均值为0,方差为1。
-
缩放和平移: 引入两个可学习的参数,一个缩放参数和一个平移参数,用于将归一化后的特征进行缩放和平移,使得网络可以恢复一定的自由度。
-
反向传播: 批量归一化引入了两个可学习的参数,因此需要在反向传播过程中计算这两个参数的梯度,以便进行参数更新。
批量归一化的优点包括:
-
加速收敛: 批量归一化可以减少训练过程中的内部协变量偏移,从而加速模型的收敛速度。
-
稳定性: 批量归一化可以使每一层的输入保持在一个稳定的范围内,有助于避免梯度爆炸或梯度消失问题。
-
正则化: 批量归一化在一定程度上具有正则化的效果,有助于减少过拟合的风险。
-
不依赖学习率: 批量归一化可以减少对学习率的敏感性,允许使用较大的学习率。
-
适用于多种架构: 批量归一化适用于卷积层和全连接层,适用于不同的深度神经网络架构。
虽然批量归一化在训练神经网络时具有许多优点,但在实际应用中,也需要注意一些细节,如在测试阶段如何进行归一化、是否使用可学习的参数等。
二、LN(Layer Normalization)
层归一化(Layer Normalization,LN)是一种神经网络正则化方法,类似于批量归一化(Batch Normalization,BN),但它的计算方式和应用场景略有不同。与批量归一化一样,层归一化旨在加速训练收敛并减少梯度消失问题。
以下是层归一化的主要特点和工作原理:
-
计算方式: 在层归一化中,对于每个样本,计算每个特征维度上的均值和方差,然后对每个特征维度进行归一化。与批量归一化不同的是,层归一化不是在整个批次内进行归一化,而是在样本级别进行。
-
适用场景: 层归一化在适用场景上与批量归一化有所不同。它更适用于循环神经网络(RNN)等序列数据建模的情况,因为在RNN中,批次大小可能会受限,而层归一化不依赖于批次大小。
-
平移和缩放: 与批量归一化类似,层归一化也引入了可学习的平移和缩放参数,用于对归一化后的特征进行调整,以保留一定的模型表示能力。
-
解决梯度消失: 层归一化的主要目的之一是缓解梯度消失问题。在RNN等深度结构中,梯度消失问题尤为突出,层归一化可以提供更稳定的梯度流动。
总的来说,层归一化在一些特定情况下,如处理序列数据时,可以是一个有效的正则化方法。它与批量归一化一样,有助于改善网络的训练和收敛性能,并可以用于处理梯度消失等问题。
三、IN(Instance Normalization)
实例归一化(Instance Normalization,IN)是一种神经网络正则化方法,类似于批量归一化(Batch Normalization,BN)和层归一化(Layer Normalization,LN),但其计算方式和应用场景有所不同。实例归一化主要用于图像生成和风格转换等任务,以保持样本内的特征一致性。
以下是实例归一化的主要特点和工作原理:
-
计算方式: 对于每个样本,在每个特征通道上进行归一化,使得每个样本的每个特征通道均值为0,方差为1。
-
适用场景: 实例归一化主要适用于需要保持样本内特征一致性的任务,如图像生成、风格迁移等。在这些任务中,每个样本都是一个独立的实例,批次内的样本之间可能存在显著差异。
-
平移和缩放: 类似于批量归一化和层归一化,实例归一化也引入了可学习的平移和缩放参数,用于对归一化后的特征进行调整。
-
保持特征一致性: 实例归一化的主要目的是保持样本内的特征一致性,从而在图像生成等任务中获得更好的效果。它可以帮助生成更真实、更一致的图像。
总的来说,实例归一化在图像生成、风格转换等任务中可以是一个有用的正则化方法。它与批量归一化和层归一化一样,可以改善训练和收敛性能,但在适用场景和计算方式上有所不同。根据任务需求,选择合适的归一化方法可以提升神经网络的性能。
四、GN(Group Normalization)
组归一化(Group Normalization,GN)是一种神经网络正则化方法,类似于批量归一化(Batch Normalization,BN)、层归一化(Layer Normalization,LN)和实例归一化(Instance Normalization,IN),但其计算方式和适用场景有所不同。组归一化可以在一定程度上克服批量归一化在小批次情况下的问题,并且适用于不同大小的批次。
以下是组归一化的主要特点和工作原理:
-
计算方式: 将特征通道分为若干组(group),在每个组内进行均值和方差归一化,然后通过缩放和平移参数对数据进行调整。每个组可以包含一定数量的特征通道。
-
适用场景: 组归一化适用于不同大小的批次,尤其在小批次情况下表现更好,因为它不会受到批次内样本数的限制。它也适用于需要降低计算复杂度的情况。
-
平移和缩放: 类似于其他归一化方法,组归一化引入了可学习的平移和缩放参数,用于对归一化后的特征进行调整。
-
计算效率: 组归一化的计算量较小,因为它将特征通道分组处理,减少了计算的复杂度,适用于计算资源有限的情况。
-
特征独立性: 不同于批量归一化,组归一化在每个组内进行归一化,有助于保持特征的独立性,对于不同特征的影响较小。
总的来说,组归一化是一种兼顾计算效率和适用于不同批次大小的正则化方法。它适用于小批次情况,且能够在不同任务中提供一定程度的正则化和优化效果。根据实际情况和任务需求,选择合适的归一化方法可以提升神经网络的性能。
五、SN(Switchable Normalization)
可切换归一化(Switchable Normalization,SN)是一种结合了多种归一化方法的正则化技术,可以在不同情况下切换使用不同的归一化方式。SN的目标是在不同任务或不同层中选择最适合的归一化方法,从而提高模型的性能和泛化能力。
以下是可切换归一化的主要特点和工作原理:
-
多种归一化方法: SN结合了批量归一化(Batch Normalization,BN)、层归一化(Layer Normalization,LN)和实例归一化(Instance Normalization,IN)等不同的归一化方法,形成了一个可切换的策略。
-
权重参数控制: SN引入了一个权重参数,用于控制不同归一化方法之间的切换。通过学习这个权重参数,网络可以自适应地选择在不同层中使用哪种归一化方法。
-
适用性: SN适用于需要在不同任务或不同层中灵活选择归一化方法的情况。不同任务或不同层的特点可能不同,选择不同的归一化方式可以提升模型性能。
-
任务自适应: SN可以根据任务的特性自适应地选择合适的归一化方法,从而在不同任务上获得更好的效果。
总的来说,可切换归一化是一种旨在充分利用不同归一化方法的正则化技术,能够根据任务需求选择最适合的归一化方式。它可以提高模型的适应性和泛化能力,适用于各种不同的神经网络任务。
六、区别
BN(Batch Normalization)、LN(Layer Normalization)、IN(Instance Normalization)、GN(Group Normalization)和SN(Switchable Normalization)是不同的归一化方法,用于神经网络中的正则化和加速训练。它们在计算方式、适用场景和优缺点等方面有所不同。以下是它们的主要区别:
-
BN(Batch Normalization):
- 计算方式:在每个批次内,对每个特征维度进行均值和方差归一化,使得每个特征的均值为0,方差为1。然后,通过缩放和平移参数对数据进行调整。
- 适用场景:适用于深层网络,有助于缓解梯度消失问题,加速收敛,减少训练时间。
- 优缺点:在训练过程中引入了小批量噪声,可能降低模型的泛化性能。需要额外的缩放和平移参数。
-
LN(Layer Normalization):
- 计算方式:在每个样本内,对每个特征维度进行均值和方差归一化,使得每个特征的均值为0,方差为1。然后,通过缩放和平移参数对数据进行调整。
- 适用场景:适用于 RNN(循环神经网络)等对序列数据建模的场景,不依赖于批次的大小。
- 优缺点:在样本维度上进行归一化,不引入批次内噪声,有助于处理变长序列。
-
IN(Instance Normalization):
- 计算方式:在每个样本内,对每个特征维度进行均值和方差归一化,使得每个样本的每个特征的均值为0,方差为1。然后,通过缩放和平移参数对数据进行调整。
- 适用场景:适用于图像生成和风格转换等需要保持样本内特征一致性的任务。
- 优缺点:在样本内进行归一化,适合需要样本级别特征的任务。
-
GN(Group Normalization):
- 计算方式:将特征通道分为若干组(group),在每个组内进行均值和方差归一化,然后通过缩放和平移参数对数据进行调整。
- 适用场景:适用于较小批次大小或特征通道较多的情况,不受批次大小影响。
- 优缺点:在通道维度上进行归一化,有较小的计算开销,适用于小批次情况。
-
SN(Switchable Normalization):
- 计算方式:结合了 BN、LN 和 IN,通过学习一个权重参数来在这些不同的归一化方法中进行切换,从而根据任务需求自适应选择使用哪一种。
- 适用场景:适用于具有不同特点的不同任务,能够在不同任务中获得最佳性能。
- 优缺点:增加了一个权重参数来控制不同归一化方法的切换,增加了模型的复杂性。
总的来说,这些不同的归一化方法在不同的情况下有其适用性和优劣势。根据任务需求、数据分布和模型结构,选择合适的归一化方法可以提升神经网络的训练和泛化性能。