1.链表
链表不同于顺序表,顺序表底层采用数组作为存储容器,需要分配一块连续且完整的内存空间进行使用,而链表则不需要,它通过一个指针来连接各个分散的结点,形成了一个链状的结构,每个结点存放一个元素,以及一个指向下一个结点的指针,通过这样一个一个相连,最后形成了链表。它不需要申请连续的空间,只需要按照顺序连接即可,虽然物理上可能不相邻,但是在逻辑上依然是每个元素相邻存放的,这样的结构叫做链表(单链表)。
链表分为带头结点的链表和不带头结点的链表,戴头结点的链表就是会有一个头结点指向后续的整个链表,但是头结点不存放数据

而不带头结点的链表就像上面那样,第一个节点就是存放数据的结点,一般设计链表都会采用带头结点的结构,因为操作更加方便。
我们来尝试定义一下:
public class LinkedList<E> {
//链表的头结点,用于连接之后的所有结点
private final Node<E> head = new Node<>(null);
private int size = 0; //当前的元素数量还是要存一下,方便后面操作
private static class Node<E> {
//结点类,仅供内部使用
E element; //每个结点都存放元素
Node<E> next; //以及指向下一个结点的引用
public Node(E element) {
this.element = element;
}
}
}
1.1插入
链表的插入该怎么做:可以先修改新插入的结点的后继结点(也就是下一个结点)指向,指向原本在这个位置的结点,接着我们可以将前驱结点(也就是上一个结点)的后继结点指向修改为我们新插入的结点,这样,我们就成功插入了一个新的结点,现在新插入的结点到达了原本的第二个位置上
public void add(E element, int index){
Node<E> prev = head; //先找到对应位置的前驱结点
for (int i = 0; i < index; i++)
prev = prev.next;
Node<E> node = new Node<>(element); //创建新的结点
node.next = prev.next; //先让新的节点指向原本在这个位置上的结点
prev.next = node; //然后让前驱结点指向当前结点
size++; //完事之后一样的,更新size
}
我们来重写一下toString方法看看能否正常插入:
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
Node<E> node = head.next; //从第一个结点开始,一个一个遍历,遍历一个就拼接到字符串上去
while (node != null) {
builder.append(node.element).append(" ");
node = node.next;
}
return builder.toString();
}
- 考虑插入位置是否合法:
public void add(E element, int index){
if(index < 0 || index > size)
throw new IndexOutOfBoundsException("插入位置非法,合法的插入位置为:0 ~ "+size);
Node<E> prev = head;
for (int i = 0; i < index; i++)
prev = prev.next;
Node<E> node = new Node<>(element);
node.next = prev.next;
prev.next = node;
size++;
}
1.2删除
插入操作完成之后,我们接着来看删除操作,那么我们如何实现删除操作呢?实际上也会更简单一些,我们可以直接将待删除节点的前驱结点指向修改为待删除节点的下一个


这样,在逻辑上来说,待删除结点其实已经不在链表中了,所以我们只需要释放掉待删除结点占用的内存空间就行了

public E remove(int index){
if(index < 0 || index > size - 1) //同样的,先判断位置是否合法
throw new IndexOutOfBoundsException("删除位置非法,合法的删除位置为:0 ~ "+(size - 1));
Node<E> prev = head;
for (int i = 0; i < index; i++) //同样需要先找到前驱结点
prev = prev.next;
E e = prev.next.element; //先把待删除结点存放的元素取出来
prev.next = prev.next.next; //可以删了
size--; //记得size--
return e;
}
这样,我们就成功完成了链表的删除操作。
- 获取对应位置上的元素:
public E get(int index){
if(index < 0 || index > size - 1)
throw new IndexOutOfBoundsException("非法的位置,合法的位置为:0 ~ "+(size - 1));
Node<E> node = head;
while (index-- >= 0) //这里直接让index减到-1为止
node = node.next;
return node.element;
}
public int size(){
return size;
}
- 什么情况下使用顺序表,什么情况下使用链表呢?
- 通过分析顺序表和链表的特性我们不难发现,链表在随机访问元素时,需要通过遍历来完成,而顺序表则利用数组的特性直接访问得到,所以,当我们读取数据多于插入或是删除数据的情况下时,使用顺序表会更好。
- 而顺序表在插入元素时就显得有些鸡肋了,因为需要移动后续元素,整个移动操作会浪费时间,而链表则不需要,只需要修改结点 指向即可完成插入,所以在频繁出现插入或删除的情况下,使用链表会更好。
虽然单链表使用起来也比较方便,不过有一个问题就是,如果我们想要操作某一个结点,比如删除或是插入,那么由于单链表的性质,我们只能先去找到它的前驱结点,才能进行。为了解决这种查找前驱结点非常麻烦的问题,我们可以让结点不仅保存指向后续结点的指针,同时也保存指向前驱结点的指针
这样我们无论在哪个结点,都能够快速找到对应的前驱结点,就很方便了,这样的链表我们成为双向链表(双链表)
2.栈
栈(也叫堆栈,Stack)是一种特殊的线性表,它只能在在表尾进行插入和删除操作
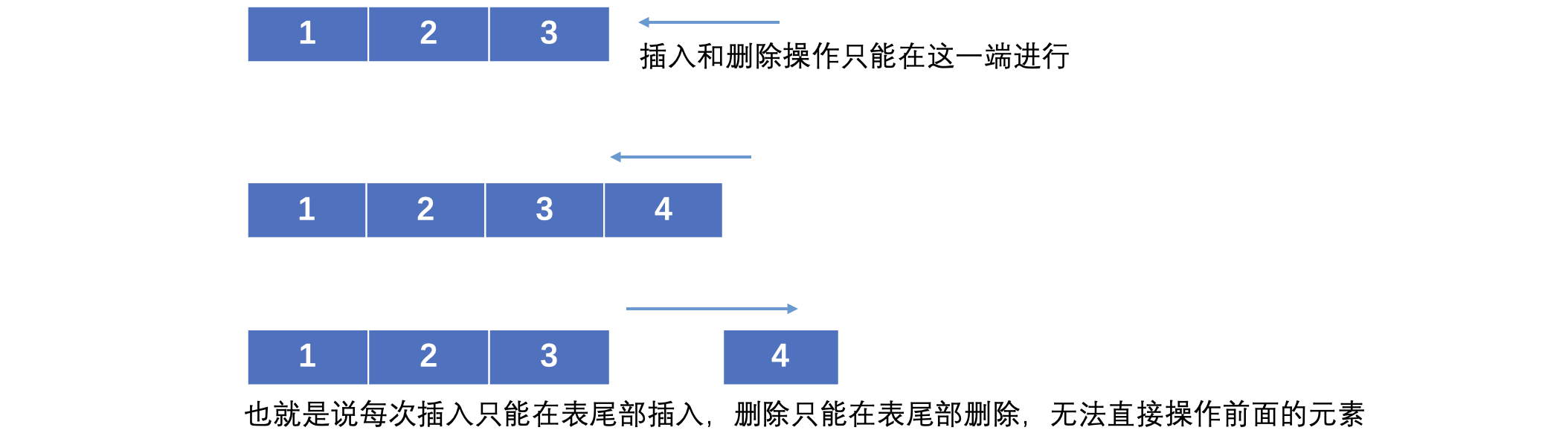
底部称为栈底,顶部称为栈顶,所有的操作只能在栈顶进行,也就是说,被压在下方的元素,只能等待其上方的元素出栈之后才能取出,就像我们往箱子里里面放的书一样,因为只有一个口取出里面的物品,所以被压在下面的书只能等上面的书被拿出来之后才能取出,这就是栈的思想,它是一种先进后出的数据结构(FILO,First In, Last Out)
实现栈也是非常简单的,可以基于我们前面的顺序表或是链表,这里我们需要实现两个新的操作:
- pop:出栈操作,从栈顶取出一个元素。
- push:入栈操作,向栈中压入一个新的元素。
栈可以使用顺序表实现,也可以使用链表实现
2.1入栈
当有新的元素入栈,只需要在链表头部插入新的结点即可,我们来尝试编写一下:
public class LinkedStack<E> {
private final Node<E> head = new Node<>(null); //大体内容跟链表类似
private static class Node<E> {
E element;
Node<E> next;
public Node(E element) {
this.element = element;
}
}
}
入栈操作:
public void push(E element){
Node<E> node = new Node<>(element); //直接创建新结点
node.next = head.next; //新结点的下一个变成原本的栈顶结点
head.next = node; //头结点的下一个改成新的结点
}
2.2出栈
出栈也是同理,所以我们只需要将第一个元素移除即可:
public E pop(){
if(head.next == null) //如果栈已经没有元素了,那么肯定是没办法取的
throw new NoSuchElementException("栈为空");
E e = head.next.element; //先把待出栈元素取出来
head.next = head.next.next; //直接让头结点的下一个指向下一个的下一个
return e;
}
3.队列
前面我们学习了栈,栈中元素只能栈顶出入,它是一种特殊的线性表,同样的,队列(Queue)也是一种特殊的线性表。
就像我们在超市、食堂需要排队一样,我们总是排成一列,先到的人就排在前面,后来的人就排在后面,越前面的人越先完成任务,这就是队列,队列有队头和队尾
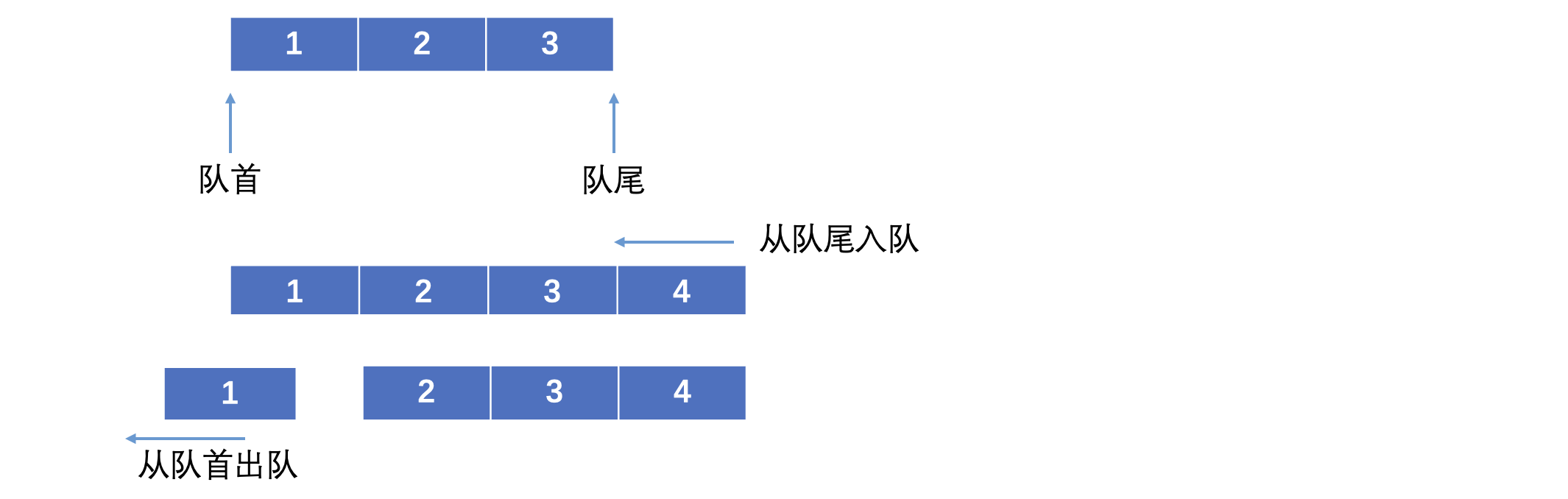
秉承先来后到的原则,队列中的元素只能从队尾进入,只能从队首出去,也就是说,入队顺序为1、2、3、4,那么出队顺序也一定是1、2、3、4,所以队列是一种先进先出(FIFO,First In, First Out)的数据结构。
队列也可以使用链表和顺序表来实现,只不过使用链表的话就不需要关心容量之类的问题了,会更加灵活一些
public class LinkedQueue<E> {
private final Node<E> head = new Node<>(null);
public void offer(E element){
//入队操作
Node<E> last = head;
while (last.next != null) //入队直接丢到最后一个结点的屁股后面就行了
last = last.next;
last.next = new Node<>(element);
}
public E poll(){
//出队操作
if(head.next == null) //如果队列已经没有元素了,那么肯定是没办法取的
throw new NoSuchElementException("队列为空");
E e = head.next.element;
head.next = head.next.next; //直接从队首取出
return e;
}
private static class Node<E> {
E element;
Node<E> next;
public Node(E element) {
this.element = element;
}
}
}