作者 |杨亦诚
背景
作为深度学习领域的 “github”,HuggingFace 已经共享了超过 100,000 个预训练模型,10,000 个数据集,其中就包括了目前 AIGC 领域非常热门的“文生图”,“图生文”任务范式,例如 ControlNet, StableDiffusion, Blip 等。通过 HuggingFace 开源的 Transformers, Diffusers 库,只需要要调用少量接口函数,入门开发者也可以非常便捷地微调和部署自己的大模型任务,你甚至不需要知道什么是 GPT,BERT 就可以用他的模型,开发者不需要从头开始构建模型任务,大大简化了工作流程。从下面的例子中可以看到,在引入 Transformer 库以后只需要5行代码就可以构建一个基于 GPT2 的问答系统,期间 HuggingFace 会为你自动下载 Tokenizer 词向量库与预训练模型。

图:HuggingFace 预训练模型任务调用示例
但也正因为 Transformer, Diffusers 这些库具有非常高的易用性,很多底层的代码与模型任务逻辑也被隐藏了起来,如果开发者想针对某个硬件平台做特定的优化,则需要将这些库底层流水行进行拆解再逐个进行模型方面的优化。下面这张图就展示了利用 HuggingFace 库在调用 ControlNet 接口时的逻辑, 和他底层实际的流水线结构:
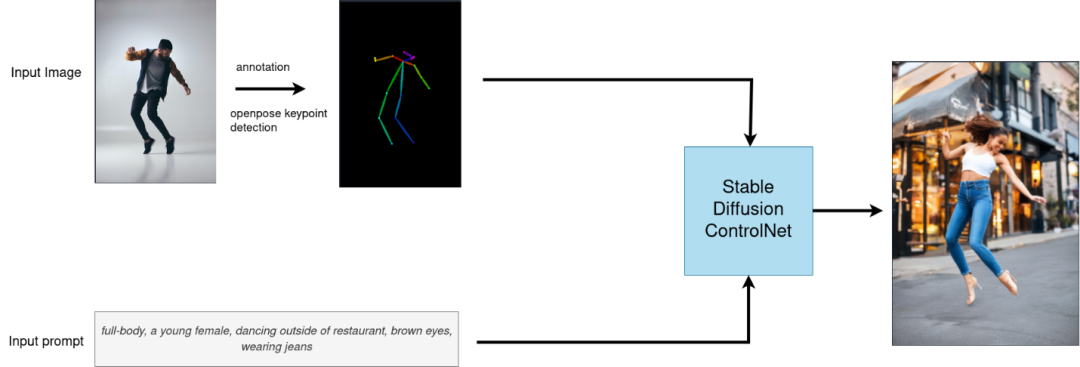
图:ControlNet 接口调用逻辑

图:ControlNet 实际运行逻辑
一. OpenVINO™简介
用于高性能深度学习的英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,以期在从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。
在推理后端,得益于 OpenVINO™ 工具套件提供的“一次编写,任意部署”的特性,转换后的模型能够在不同的英特尔硬件平台上运行,而无需重新构建,有效简化了构建与迁移过程。此外,为了支持更多的异构加速单元,OpenVINO™ 的runtime API底层采用了插件式的开发架构,基于 oneAPI 中的 oneDNN 等函数计算加速库,针对通用指令集进行深度优化,为不同的硬件执行单元分别实现了一套完整的高性能算子库,充分提升模型在推理运行时的整体性能表现。
可以说,如果开发者希望在英特尔平台上实现最佳的推理性能,并具备多平台适配和兼容性,OpenVINO™是不可或缺的部署工具首选。因此接下来的方案也是在探讨如何利用 OpenVINO™ 来加速 HuggingFace 预训练模型。
二. OpenVINO™ 部署方案
简单来说目前有两种方案可以实现利用 OpenVINO™ 加速 Huggingface 模型部署任务,分别是使用 Optimum-Intel 插件以及导出 ONNX 模型部署的方式,两种方案均有不同的优缺点。
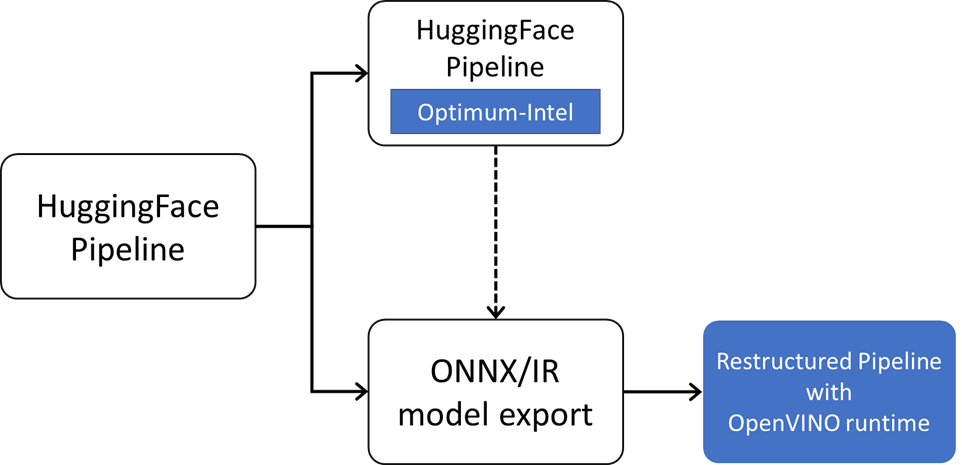
图:OpenVINO™ 部署 HuggingFace 模型路径
方案一:使用 Optimum-Intel 推理后端
Optimum-Intel 用于在英特尔平台上加速 HuggingFace 的端到端流水线。它的 API 和Transformers或是 Diffusers 的原始 API 极其相似,因此所需代码改动很小。目前Optimum-Intel已经集成了OpenVINO™ 作为其推理任务后端,在大部分 HuggingFace 预训练模型的部署任务中,开发者只需要替换少量代码,就可以实现将 HuggingFace Pipeline 中的模型通过 OpenVINO™ 部署在 Intel CPU 上,并加速推理任务,OpenVINO™ 会自动优化 bfloat16 模型,优化后的平均延迟下降到了 16.7 秒,相当不错的 2 倍加速。从下图可以看到在调用 OpenVINO™ 的推理后端后,我们可以最大化 Stable Diffusion 系列任务在 Intel CPU 上的推理性能。

图:Huggingface 不同后端在 CPU 上的性能比较
项目地址: https://github.com/huggingface/optimum-intel

图:只需2行代码替换,利用 OpenVINO™ 部署文本分类任务
此外 Optimum-Intel 也可以支持在 Intel GPU 上部署模型:

图:在 Intel GPU 上加载 Huggingface 模型
Optimum Intel 和 OpenVINO™ 安装方式如下:
$ pip install optimum[openvino]在部署Stable Diffusion 模型任务时,我们也只需要将StableDiffusion Pipeline 替换为 OVStableDiffusionPipeline 即可。
from optimum.intel.openvino import OVStableDiffusionPipelineov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
除此以外 Optimum-Intel 还引入了对 OpenVINO™ 模型压缩工具 NNCF 组件的支持,NNCF 目前可以支持 Post-training static quantization (训练后量化)和 Quantization-aware training (训练感知量化)两种模型压缩模式,前者需要引入少量不带标签的样本数据来校准模型输入的数据分布,定制量化参数,后者则可以在保证模型准确性的情况下,进行量化重训练。将 HuggingFace 中丰富的数据集资源作为校准数据或是重训练数据,我们可以轻松完成对预训练模型的 Int8 在线量化与推理,具体示例如下:

图:后训练量化示例
方案二:使用 OpenVINO™ runtime 进行部署
当然 Optimum-Intel 库在提供极大便捷性的同时,也有一定的不足,例如对于新模型的支持存在一定的滞后性,并且对 HuggingFace 库存在依赖性,因此第二种方案就是将 HuggingFace 的预训练模型直接导出为 ONNX 格式,再直接通过 OpenVINO™ 的原生推理接口重构整个 pipeline,以此来达到部署代码轻量化,以及对新模型 pipeline enable 的目的。
这里提供三种导出模型的方案:
1. 使用 Optimum-Intel 接口直接导出 OpenVINO™ 的 IR 格式模型:

图:使用 Optimum-Intel 直接导出 IR 文件
2. 使用 HuggingFace 原生工具导出 ONNX 格式模型:
HuggingFace 的部分库中是包含 ONNX 模型导出工具的,以 Transformer 库为例,我们可以参考其官方文档实现 ONNX 模型的导出。
使用方法:https://huggingface.co/docs/transformers/index
3. 使用 PyTorch 底层接口导出 ONNX 格式模型:
如果是 Optimum-Intel 还不支持的模型,同时 HuggingFace 库也没有提供模型导出工具的话,我们就要通过基础训练框架对其进行解析,由于 Transformer 等库的底层是基于 PyTorch 框架进行构建,如何从 PyTorch 框架导出 ONNX 模型的通用方法,可以参考官方的说明文档:https://docs.openvino.ai/latest/openvino_docs_MO_DG_prepare_model_convert_model_Convert_Model_From_PyTorch.html
这里我们再以 ControlNet 的姿态任务作为示例,从本文背景章节中的任务流程图中我们不难发现 ControlNet 任务是基于多个模型构建而成,他的 HuggingFace 测试代码可以分为以下几个部分:
项目仓库:https://huggingface.co/lllyasviel/sd-controlnet-openpose
1) 加载并构建 OpenPose 模型任务
openpose = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')2) 运行 OpenPose 推理任务,获得人体关键点结构
image = openpose(image)3) 加载并构建 ControlNet 模型任务
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16)
4) 下载并构建 Stable Diffusion 系列模型任务,并将 ControlNet 对象集成到 StableDiffusion 原始的 pipeline 中
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16)
5) 运行整个 pipeline 获取生成的结果图像
image = pipe("chef in the kitchen", image,num_inference_steps=20).images[0]
可以看到在1,3,4步任务中够封装了模型的下载,因此我们需要对这些接口进行“逆向工程”,找出其中的 PyTorch 的模型对象,并利用 PyTorch 自带的 ONNX 转换接口 torch.onnx.export(model, (dummy_input, ), 'model.onnx'),将这些对象导出为ONNX格式,在这个接口最重要的两个参数分别为 torch.nn.Module 模型对象 model,和一组模拟的输入数据 dummy_input,由于 PyTorch 是支持动态的 input shape,输入没有固定的 shape,因此我们需要根据实际情况,找到每个模型的 input shape,然后再创建模拟输入数据。在这个过程这里我们分别需要找到这个几个接口所对应库的源码,再进行重构:
1) OpenPose 模块
首先是人体姿态关键点检测任务的代码仓库:
https://github.com/patrickvonplaten/controlnet_aux/tree/master/src/controlnet_aux/open_pose
通过解析推理时实际调用的模型对象,我们可以了解到,这个模型的 PyTorch 对象类为 class bodypose_model(nn.Module),输入为 NCHW 格式的图像 tensor,而他在 controlnet_aux 库推理过程中抽象出的实例是 OpenposeDetector.body_estimation.model,因此我们可以通过以下方法将他导出为 ONNX 格式:
torch.onnx.export(openpose.body_estimation.model, torch.zeros([1, 3, 184, 136]), OPENPOSE_ONNX_PATH)因为 OpenVINO™ 支持动态的 input shape,所以 export 函数中对于输入的长和宽可以随机定义。
2) StableDiffusionControlNetPipeline 模块
我们可以把第3和第4步中用到的模型放在一起来看:
https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py#L188

图:StableDiffusionControlNetPipeline 对象初始化参数
可以看到在构建 StableDiffusionControlNetPipeline 的时候,会初始化4个 torch.nn.Module 模型对象,分别是 vae, text_encoder, unet, controlnet, 因此我们在重构任务的过程中也需要手动导出这几个模型对象,此时你必须知道每一个模型的 input shape,以此来构建模拟输入数据,这里比较常规的做法是:直接调取 pipeline 中的成员函数进行单个模型的推理任务作为 torch.onnx.export 函数中的 model 实例。
pipe.text_encoder(uncond_input.input_ids.to(device),attention_mask=attention_mask,)
单独调取 text_encoder 推理任务
遍历 StableDiffusionControlNetPipeline 的 __call__ 函数,我们也不难发现,多个模型之间存在串联关系。因此我们也可以模仿 StableDiffusionControlNetPipeline 的调用任务,构建自己的 pipeline,并通过运行这个 pipeline 找到每个模型的 input shape。直白来说就是先重构任务,再导出模型。
(https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py#L188)
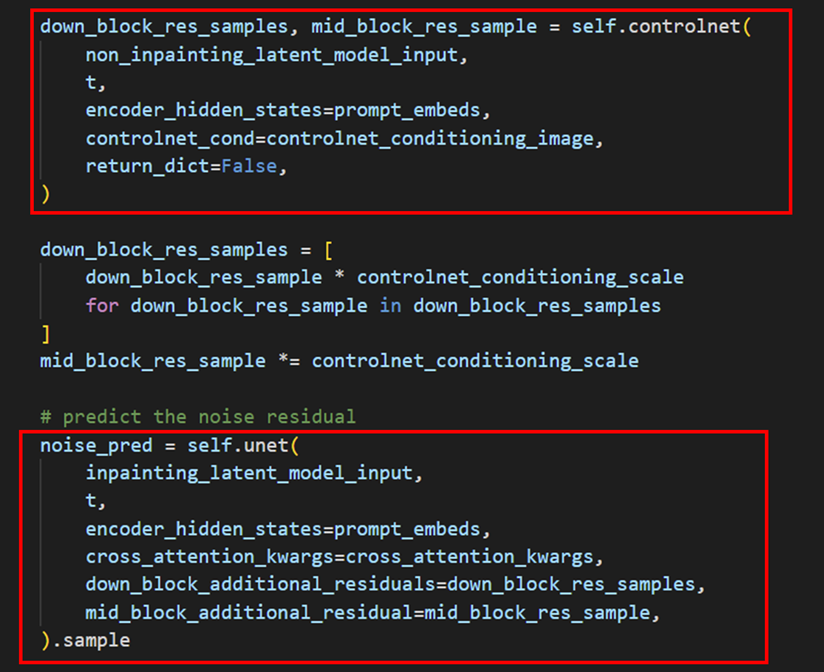
图:ControlNet 和 Unet 串联
为了更方便地搜索出每个模型的输入数据维度信息,我们也可以为每个模型单独创建一个“钩子”脚本,用于替换原始任务中的推理部分的代码,“钩取”原始任务的输入数据结构。以 ControlNet 模型为例。
3) 查询原始模型的输入参数,将以对应到实际任务的输入参数。
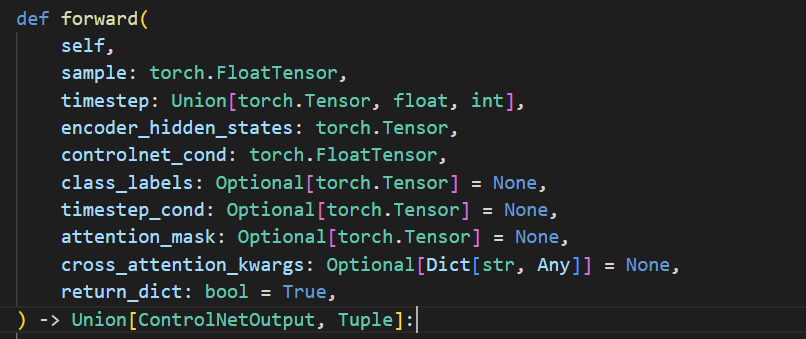
https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py#L188
4) 创建钩子脚本
class controlnet_input_shape¬¬(object):def __init__(self, model) -> None:super().__init__()self.model = modelself.dtype = model.dtypedef __call__(self,latent_model_input,t,encoder_hidden_states,controlnet_cond,return_dict):print("sample:" + str(latent_model_input.shape),"timestep:" + str(t.shape),"encoder_hidden_states:" + str(encoder_hidden_states.shape),"controlnet_cond:" + str(controlnet_cond.shape))def to(self, device):self.model.to(device)
5) 将钩子对象替换原来的 controlnet 模型对象,并运行原始的 pipeline 任务
hooker = controlnet_input_shape(pipe.controlnet)pipe.controlnet = hooker
6) 运行结果
$ “sample:torch.Size([2, 4, 96, 64]) timestep:torch.Size([]) encoder_hidden_states:torch.Size([2, 77, 768]) controlnet_cond:torch.Size([2, 3, 768, 512])”模型导出以及重构部分的完整演示代码可以参考以下示例,这里有一点需要额外注意因为 OpenVINO™ 的推理接口只支持 numpy 数据输入,而 Diffuers 的示例任务是以 Torch Tensor 进行数据传递,所以这里建议开发用 numpy 来重新实现模型的前后处理任务,或是在 OpenVINO™ 模型输入和输入侧提前完成格式转换。
完整项目地址:https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/235-controlnet-stable-diffusion/235-controlnet-stable-diffusion.ipynb
三. 总结
作为当下最火的预训练模型仓库之一,HuggingFace 可以帮助我们快速实现 AIGC 类模型 的部署,通过引入 Optimum-Intel 以及 OpenVINO™ 工具套件,开发者可以更进一步提升这个预训练模型在英特尔平台上的任务性能。以下是这两种方案的优缺点比较:
