论文地址:https://arxiv.org/pdf/1512.03385.pdf
pytorch官方预训练模型地址:
'resnet18': 'https://download.pytorch.org/models/resnet18-f37072fd.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-b627a593.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-0676ba61.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-63fe2227.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-394f9c45.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth'pytorch官方resnet网络代码(包括resnet18、34、50、101、152,resnext50_32x4d、resnext101_32x8d、wide_resnet50_2、wide_resnet101_2):torchvision.models.resnet — Torchvision 0.11.0 documentation![]() https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html
https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html
----------------------------------------------------------------分割线-------------------------------------------------------
如下图,论文中介绍了几种常见的resnet网络结构,为了了解resnet的原理以及代码实现,对resnet18及resnet50进行结构分析和代码复现就够了。resnet18的block在代码中实现的时候是BasicBlock,而resnet50的block在实现的时候是Bottleneck。BasicBlock和Bottleneck的区别在于前者是用两个3x3的卷积组成的,后者是用两个1x1的卷积加一个3x3的卷积组成的。

下图是resnet18和resnet50的网络模型结构图,转自
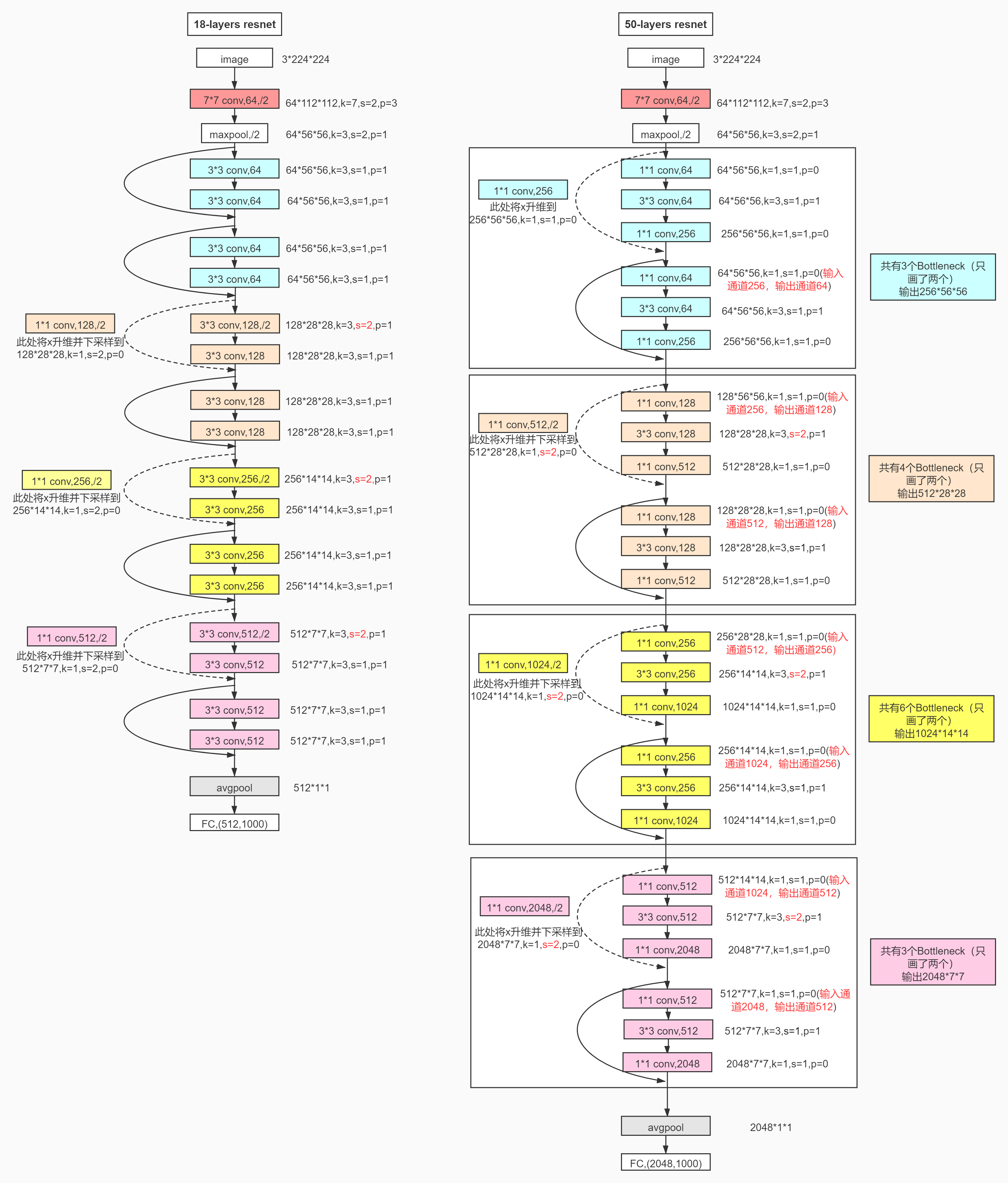
其中需要注意的一些点:
1. resnet50第一个layer(由多个block组成)中的第一个shortcut使用1x1的卷积,但stride为1,特征图尺寸不变;
2.每个layer第一个shortcut采用1x1的卷积将上一个block(两个1x1卷积+一个3x3卷积组成一个block的输出升维,从第二个layer开始stride为2,特征图长宽尺寸缩小一半才能够保持和上一个layer的输出尺寸保持相同;
3.resnet50第一个layer中每个卷积的stride都是1,从第二个layer开始第一个block中的3x3卷积的stride为2,其余的还都是1;
BasicBlock和Bottleneck的pytorch实现:
BasicBlock
class BasicBlock(nn.Module):
expansion: int = 1
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return outBottleneck
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion: int = 4
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
欢迎大家进群交流: