Prometheus的告警规则、记录规则都是采用配置文件管理,适合奉行Infrastructure as Code的公司或团队内部使用。但如果要把监控能力开放给全公司,就要支持协同操作的 UI,让各个团队互不干扰的同时共享成果。
开源方案:
-
Grafana
擅长可视化,监控绘图领域的事实标准
-
夜莺(Nightingale)
侧重告警管理,可通过夜莺搭建公司级的监控系统,把监控告警能力赋予公司所有团队。
1 夜莺简介
最初滴滴开源,之后捐给中国计算机学会开源发展委员会(CCF ODC),整合云原生开源生态的众多能力,为用户提供开箱即用、一体化全方位的云原生监控解决方案。
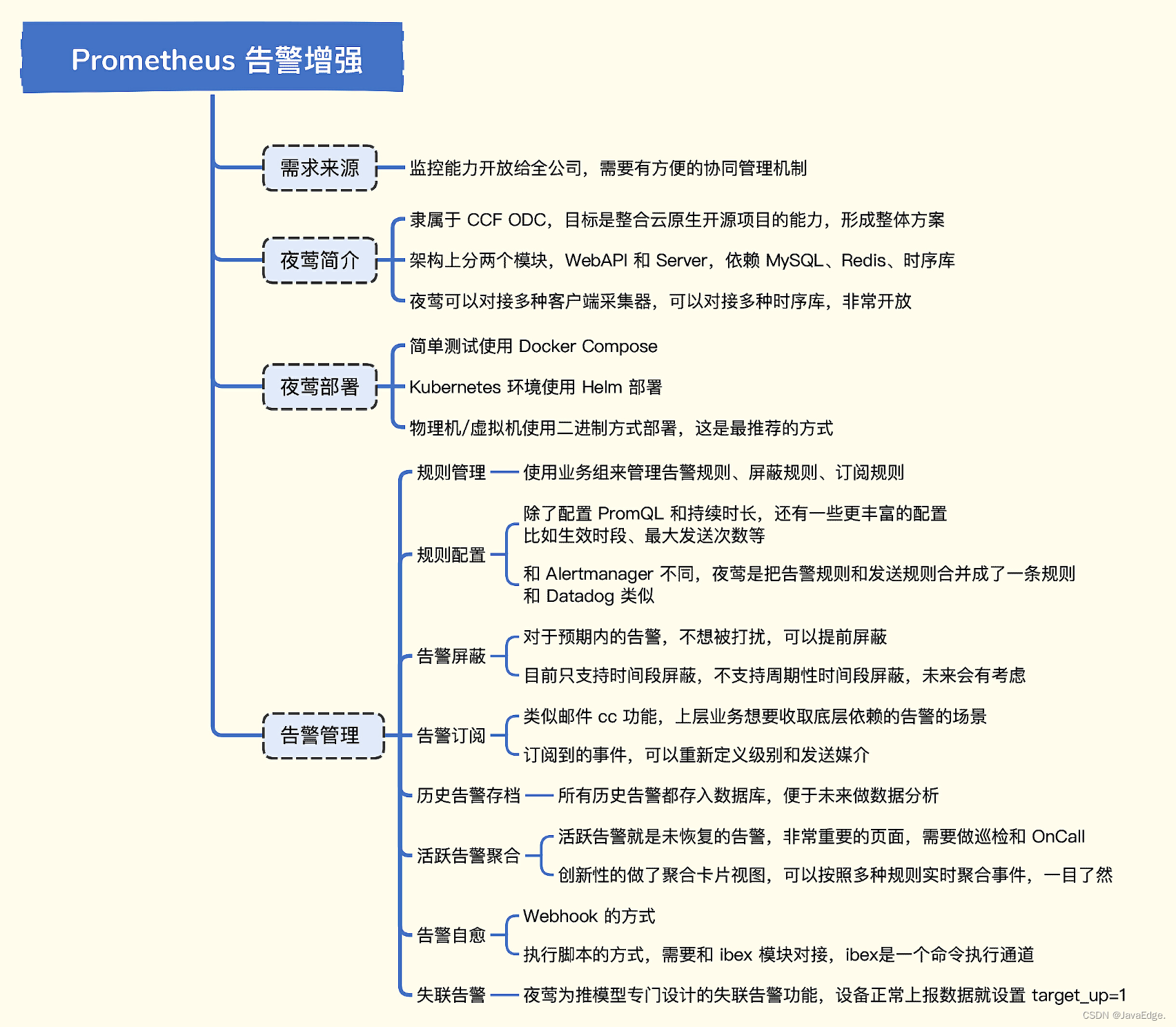
1.1 夜莺架构
Agents
监控数据采集器,夜莺可对接多种 Agent,如 Categraf、Telegraf、Grafana-Agent、Datadog-Agent。这些 Agent 都是 PUSH 模型,周期性采集监控数据,推给 Server 的 HTTP 接口。
Server
接收到数据后,通过 Remote Write 协议把数据转发给时序库,这里时序库使用Prometheus,Prometheus 要想接收 Remote Write 协议的数据,需在启动参数开启 --enable-feature=remote-write-receiver。也可使用M3DB、VictoriaMetrics、Thanos等作为时序库。
Server相当于Pushgateway,也是告警引擎,周期性从 MySQL 中同步告警规则,做规则判断生成告警事件并发送,对标Prometheus的告警引擎和Alertmanager模块。Server 还会往 Redis 发送心跳信息,不过后面的版本有计划下掉 Redis,直接使用 MySQL 处理心跳。
Webapi 模块
提供 HTTP 接口,与前端 JavaScript 交互:
- 响应管理请求,比如告警规则、屏蔽规则、监控大盘的增删改查
- 响应时序数据查询,作为一个 Proxy 把请求转发给后面的时序库,等时序库返回结果之后再转发给前端
若有些监控数据使用 Exporter 采集,就需 PULL 模型的采集支持。通常有3种做法:
- 直接使用 Prometheus 本身,配置 Scrape 规则
- 单独部署一个 agent mode 模式的 Prometheus 作为抓取器,和时序库的职能做进程级别的拆分
- 使用其他支持 PULL 模式的抓取器,如 Categraf、Grafana-Agent
2 部署夜莺
最简单方式 Docker compose:
git clone https://github.com/ccfos/nightingale.git
cd docker
docker-compose up -d
浏览器访问 nwebapi 提供的 18000 端口就能看到登录页面,默认用户是root,密码 root.2020。
对Kubernetes和Helm熟悉,可采用 Helm 的方式部署。最常用还是 二进制的方式部署。
服务端部署完成之后,可采集一些监控数据看看真实效果,推荐 安装 Categraf。也可使用其他熟悉的采集器。
3 告警管理
Prometheus告警管理在prometheus.yml配置告警规则,在alertmanager.yml中配置发送规则,都是需要修改配置文件的,上百人使用的话不好协同管理。而夜莺提供UI配置能力(也有API),并在一些方面增强,如更丰富的告警规则配置、历史事件存档、活跃事件聚合查看、对接告警自愈等。
3.1 规则管理
一个公司可能会有几十上百团队配置成千上万条告警规则,显然不能用一个扁平化的表格来罗列管理,夜莺引入了一个 业务组 的概念,每一条规则都要归属于某一个业务组,只有这个业务组的人可以管理组内的规则。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-31KuFYnD-1682925334603)(null)]
当然,业务组下面不仅有告警规则,还有监控大盘、监控对象、屏蔽规则、订阅规则、告警自愈脚本等等。业务组是夜莺里最重要的一个管理概念。
3.2 规则配置
核心还是 PromQL和持续时长。增强配置,如规则生效时间段、是否仅在本业务组生效、是否启用恢复通知、留观时长、最大发送次数等。
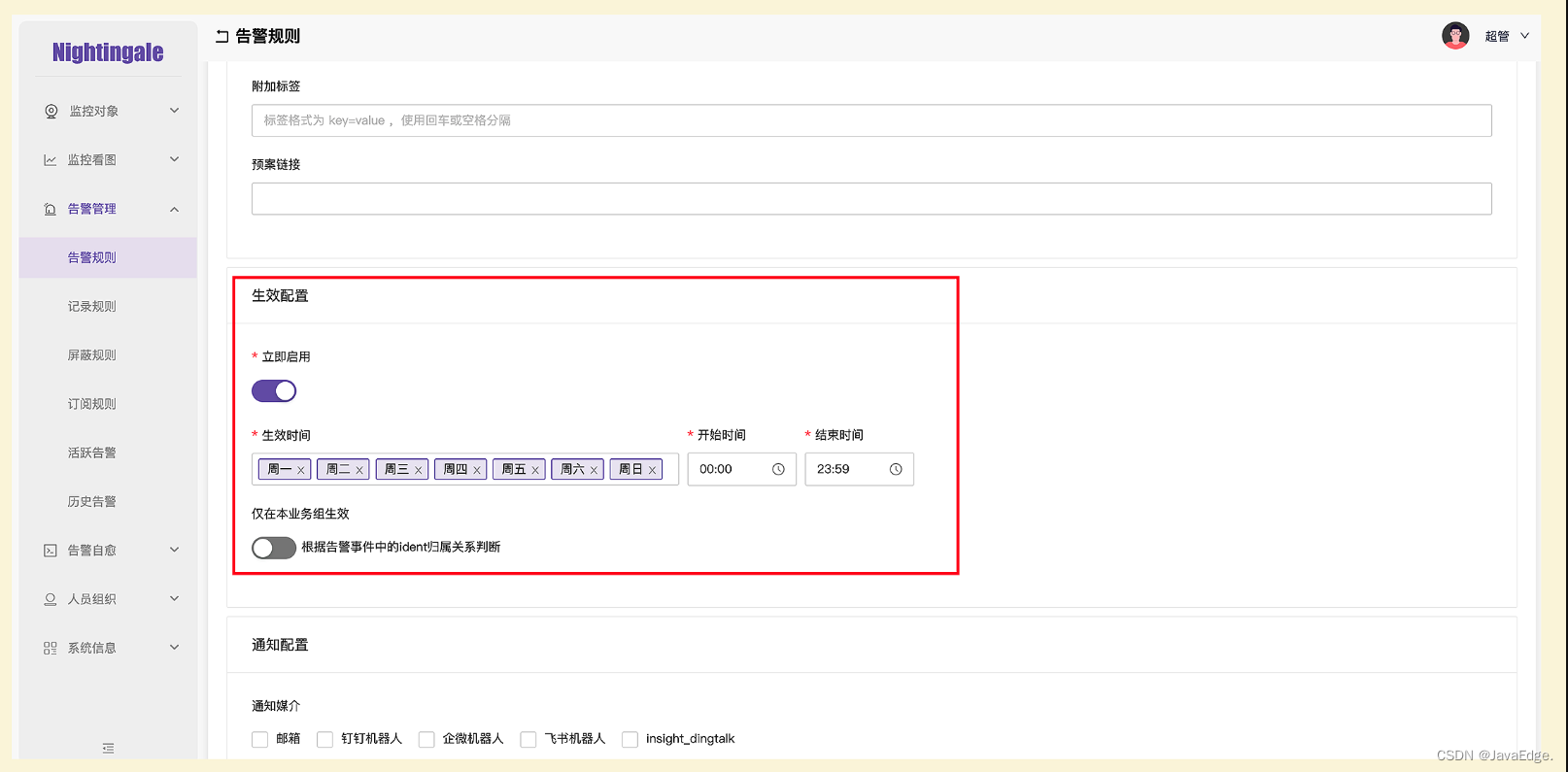
夜莺告警规则是把PromQL和发送方式整合到一条规则,这和Alertmanager不同,Prometheus告警规则只有PromQL、持续时长、附加标签、注解这些基本信息,至于发给谁、怎么发都在 Alertmanager 配置。
Prometheus+Alertmanager,可看做订阅式,告警规则中不指定接收者,在 Alertmanager 的配置中统一设置过滤条件和对应的接收者。非常灵活,但灵活东西需定规范,否则易乱,如大家统一按照业务线标签做订阅:
- 就要求时序数据都要打上业务线的标签
- 或把业务线的标签放到告警规则的附加标签
Alertmanager适合场景
所有告警都统一由某团队负责时,Prometheus+Alertmanager算最佳实践。
Borgmon集群和Borg集群一一对应,Borgmon要处理对应Borg集群上的所有应用的告警,不知道在 Borgmon 中是怎么处理告警规则的?在 Borgmon 中,告警规则是通过配置文件定义的。Borgmon 的配置文件通常包括:
-
告警规则:定义监控指标的阈值和告警策略,例如当 CPU 使用率超过 80% 时触发告警,发送邮件通知运维人员。
-
数据源:定义监控数据的来源,如 Prometheus、Graphite。
-
数据转换:定义监控数据的转换方式,如将监控数据进行聚合、过滤、计算。
-
告警通知:定义告警通知的方式和接收人,如发送邮件、短信、微信。
在 Borgmon 中,每个 Borg 集群都对应一个 Borgmon 集群,Borgmon 集群负责处理该 Borg 集群上所有应用的告警。当监控指标的值超过阈值时,Borgmon 会根据告警策略触发告警,并将告警信息发送给指定的接收人。
Borgmon的配置文件是动态加载,可通过 API 接口或命令行工具修改配置文件,实现灵活的告警规则管理。
夜莺处理方式像Datadog,每个团队配置自己的告警规则,发给自己这个团队,即自己管自己的,不需要把告警规则和接收规则拆到两个地方分别配置,我个人觉得更加直观一些,而且夜莺也支持订阅方式。
告警屏蔽
对一些告警事件做静默处理。对于那些预期内的告警,处理人不希望被打扰就会短时间做一下屏蔽,通常是根据标签对事件做过滤。
夜莺目前只能按时间段屏蔽,比如屏蔽凌晨0点到早上7点的所有告警。
告警订阅
像Alertmanager,可根据告警规则或标签做事件订阅,类似邮件抄送。
比如我是业务方,我的业务跑在Kubernetes,Kubernetes平台发生重大故障,我希望及时知道,可订阅Kubernetes所有严重告警。虽然我希望得知Kubernetes的严重告警,但我毕竟不是Kubernetes的运维人员,所以我在订阅这类事件时,不希望用电话这种方式接收告警,只希望用邮件之类轻量级方式,所以订阅规则中通常可以重新定义发送媒介、重新定义事件级别。
历史告警存档
夜莺依赖MySQL做数据持久化,所以告警事件可直接存入数据库,所有的历史告警都可以追踪查询。虽然这个功能很简单,但很多企业都需要,自证清白时很重要。
所有历史告警存档也可用于后续分析,从这些数据易知哪些业务线的告警发送得最多,消耗电话、短信费用最多,哪些业务线的告警解决得最快,哪些人是接收告警的劳模。从侧面反映出这个团队的告警策略需要优化,或者业务稳定性需优化。
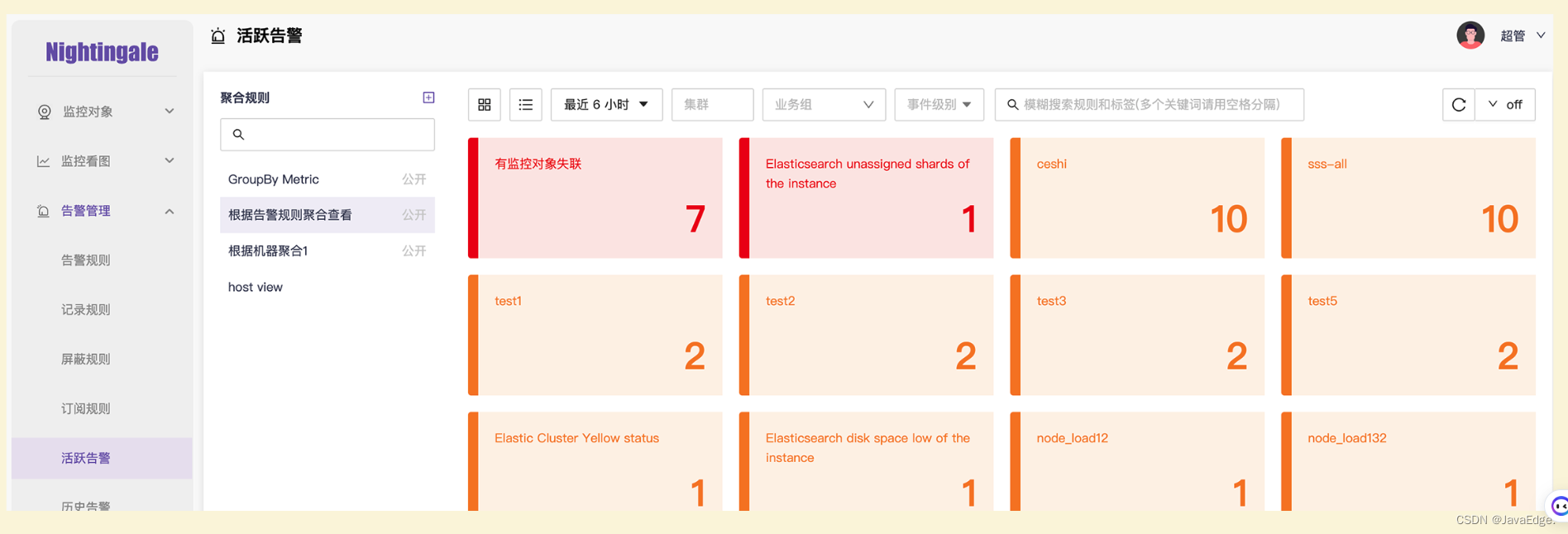
活跃告警聚合
所谓活跃告警就是未恢复的告警,活跃告警功能很重要,应该作为日常巡检必须要关注的页面。
为减少查看的心理负担,便于给告警事件分类,夜莺支持聚合卡片视图,而且聚合规则是可以自定义的,比如当前有300条未恢复的告警,我们可以根据告警规则聚合查看,也可以根据地域、业务线、服务、机器等维度聚合查看。
告警自愈
当告警事件触发之后,能自动触发一个恢复动作来止损,这就是所谓的告警自愈。一般监控系统都会支持Webhook,告警触发之后自动回调某个接口,我们就可以在这个接口里写一些自动化逻辑,但是这种方式还是要写个HTTP Server的,成本略高。夜莺除了支持Webhook之外,还可以在告警时自动执行某个脚本,用户就可以直接在脚本里写逻辑了。
告警自愈依赖 ibex 模块,这是一个批量执行脚本的小工具,你可以安装测试一下。不过有些公司会觉得有安全隐患,不敢开启这个功能,我觉得纯内网环境问题不大,如果开放到公网的话确实需要小心。
自愈脚本要能够在机器上运行,需要有较强的权限管控,这个权限也是依赖业务组的机制,只有这个业务组的管理人员,才能去这个组内的机器上跑脚本。夜莺里有个对象管理,主要就是管机器的,设计对象管理功能很重要的一个原因就是为了支持告警自愈。
失联告警
夜莺主用push模式接收监控数据,所以感知监控对象失联是问题。PromQL 有 absent 函数,但用起来麻烦,如果要为100台机器配置失联告警,就要配置100条告警规则。
夜莺在服务端加了个逻辑,接收到监控数据后,自动从数据中解析出 ident 标签当机器标识,然后为这机器生成 target_up 指标。这机器有监控数据上报,则 target_up 的值设置为 1;如果长时间收不到机器的指标上报,则 target_up 的值设置为 0。于是,只需配置一条告警规则就覆盖所有监控对象。
4 Prometheus Yaml迁移
老 Yaml 文件管理规则可不动,甚至如果 Prometheus 只是给自己团队使用的话也不太需要引入夜莺,只有那些想要 把监控能力开放给全公司用的场景 才需要引入夜莺,而且新规则可以用夜莺管理,老的规则不迁移或者慢慢迁移都是可以的。 技术是为解决现实问题,没有非黑即白。
5 总结
增强Prometheus告警管理能力,因为Prometheus的Yaml文件管理方式不方便公司级协同管理。Grafana和夜莺都可以解决这个问题:
- Grafana更擅长看图
- 夜莺更擅长告警管理
夜莺告警管理能力:
- 规则管理,包括告警规则、屏蔽规则、订阅规则
- 事件管理,包括历史事件、活跃事件
- 告警自愈