告警规则的设置是通过yml文件来设置,因此需要遵从yml的语法
groups:
- name: example #报警规则组的名字
rules:
- alert: InstanceDown #检测job的状态,持续1分钟metrices不能访问会发给altermanager进行报警
expr: up == 0
for: 1m #持续时间 , 表示持续一分钟获取不到信息,则触发报警
labels:
serverity: page # 自定义标签
annotations:
summary: "Instance {{ $labels.instance }} down" # 自定义摘要
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes." # 自定义具体描述
可以设置规则组, 规则组主要是做个告警类型的区分,比如说跟内存相关,IO相关,等等。
rules 下面 就是设置具体的规则。
告警规则的设置主要在于expr表达式的设置,以及annotations里面的提示消息的设置。
对于不了解PromSQL查询语言的,独自写表达式的难度是非常大的,我这里有个非常好的办法,我们可以从grafana
控制台获取查询语言,然后根据这个来写表达式。
第一步
进入grafana的控制台,找到任意一个视图。
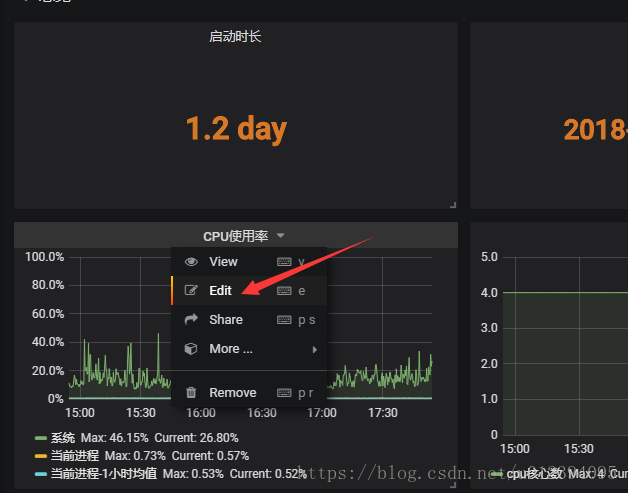
点击edit
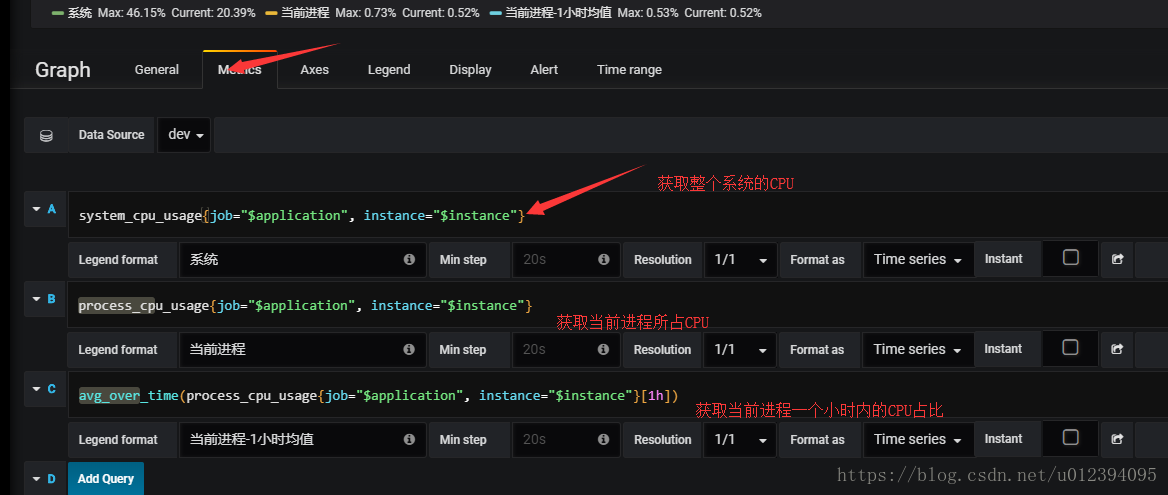
进入edit页面,可以看到**metrics **这个tab栏 , 这里就有各个指标的查询函数。 这里举个例子,比如
获取整个系统的CPU占比
system_cpu_usage{job="$application", instance="$instance"}
这个函数是指定了Job(应用的唯一标识,默认为应用名)和instance(应用的IP:端口)的,我们在实际使用的时候可以这样
system_cpu_usage{job="MSG-MS", instance="192.168.139.120:8080"}
想知道这个具体能查出来的数据是什么,可以访问prometheus的控制台。
http://10.208.204.46:9090/graph
查询结果如下
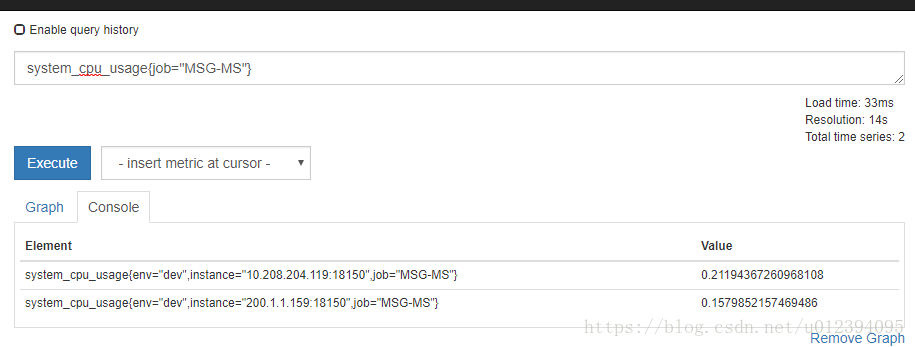
最下方,我们可以看到查询出来的结果。

查询的时候除了可以使用等号,也可以使用其他运算符
=:选择正好相等的字符串标签
!=:选择不相等的字符串标签
=~:选择匹配正则表达式的标签(或子标签)
!=:选择不匹配正则表达式的标签(或子标签)
举个例子:
system_cpu_usage{ job=~'.*MSG.*' } # 包含MSG的JOB
system_cpu_usage这个括号里面的值,都可以用来做查询条件。 后面value即为查出来的值
由此根据上面的准备,我们就可以定义如下的告警规则
groups:
- name: example #报警规则组的名字
rules:
- alert: CPU负载告警 # 规则名称
expr: system_cpu_usage{job="MSG-MS"}> 0.7 # 表示如果MSG-MS这个应用整个系统的CPU超过70% ,则触发告警
for: 10s #持续时间 , 表示持续10秒都是高于70%的,则报警
labels:
serverity: page # 自定义标签
annotations:
summary: "{{ $labels.job}} - {{ $labels.instance }} 的CPU 太高了" # 自定义摘要
description: "应用名: {{ $labels.job }} 实例名: {{ $labels.instance }} , 环境: {{ $labels.env }} , 当前值为 : {{ $value }}" # 自定义具体描述
上面的告警规则, 我们用到了labels这个变量,以及value这个变量来输出信息。
labels 使用方法 :
在我们使用prometheus控制台做测试查询的时候,system_cpu_usage括号里面的属性,就是labels可以取到的值

value 使用:
上图中的value值
