文章目录
告警流程
Prometheus主要是提供了数据的采集和存储,Alertmanager组件主要实现告警功能。Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
Prometheus告警流程:
prometheus–>触发阈值–>超出持续时间–>alertmanager–>分组|抑制|静默–>媒体类型–>邮件|钉钉|微信等发送通知

Prometheus根据rule规则判断指标是否超过阈值,如果超出阈值且持续一段时间未恢复就发送告警到Alertmanager。Alertmanager根据配置中定义的规则对告警进行分组/抑制/静默处理,最后以不同的形式发送给接收人
部署Alertmanager
下载安装包
tar xf alertmanager-0.25.0.linux-amd64.tar.gz -C /usr/local/
ln -sv /usr/local/alertmanager-0.25.0.linux-amd64 /usr/local/alertmanager
/usr/local/alertmanager/alertmanager -h #查看帮助信息
准备service文件
root@prometheus-server-01:~# cat /lib/systemd/system/alertmanager.service
[Unit]
Description=Prometheus Alertmanager
After=network.target
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file="/usr/local/alertmanager/alertmanager.yml"
[Install]
WantedBy=multi-user.target
启动alertmanager服务
systemctl daemon-reload
systemctl start alertmanager.service
systemctl status alertmanager.service
systemctl enable alertmanager.service
访问alertmanager界面
Alertmanager配置介绍
Alertmanager的配置介绍可以参考官方文档:https://prometheus.io/docs/alerting/latest/configuration
一般情况下Altermanager的配置文件会包含以下几个部分:
- global(全局配置):用来定义一些全局的公共参数,比如Smtp邮件服务器配置、企业微信配置等
- template(告警模板):用于定义告警通知时的模板,比如邮件模板、微信模板等
- router(告警路由规则):用于定义告警的分发策略
- receivers(接收者):用于定义告警接收人,可以是邮箱、微信等。一般配和告警路由规则来使用,实现不同的告警发给不同的接收人
- inhibit_rules(告警抑制规则):用于定义告警抑制规则,避免垃圾告警产生
完整格式如下:
global:
[ smtp_from: <tmpl_string> ]
[ smtp_smarthost: <string> ]
[ smtp_hello: <string> | default = "localhost" ]
[ smtp_auth_username: <string> ]
[ smtp_auth_password: <secret> ]
[ smtp_auth_password_file: <string> ]
[ smtp_auth_identity: <string> ]
[ smtp_auth_secret: <secret> ]
[ smtp_require_tls: <bool> | default = true ]
[ slack_api_url: <secret> ]
[ slack_api_url_file: <filepath> ]
[ victorops_api_key: <secret> ]
[ victorops_api_key_file: <filepath> ]
[ victorops_api_url: <string> | default = "https://alert.victorops.com/integrations/generic/20131114/alert/" ]
[ pagerduty_url: <string> | default = "https://events.pagerduty.com/v2/enqueue" ]
[ opsgenie_api_key: <secret> ]
[ opsgenie_api_key_file: <filepath> ]
[ opsgenie_api_url: <string> | default = "https://api.opsgenie.com/" ]
[ wechat_api_url: <string> | default = "https://qyapi.weixin.qq.com/cgi-bin/" ]
[ wechat_api_secret: <secret> ]
[ wechat_api_corp_id: <string> ]
[ telegram_api_url: <string> | default = "https://api.telegram.org" ]
[ webex_api_url: <string> | default = "https://webexapis.com/v1/messages" ]
[ http_config: <http_config> ]
[ resolve_timeout: <duration> | default = 5m ]
templates:
[ - <filepath> ... ]
route: <route>
receivers:
- <receiver> ...
inhibit_rules:
[ - <inhibit_rule> ... ]
time_intervals:
[ - <time_interval> ... ]
下面是一个示例配置文件:
global:
#在5m内收到Prometheus发来相同告警情况下认为告警已经恢复
resolve_timeout: 5m
#SMTP邮件服务器配置
smtp_smarthost: 'localhost:25'
smtp_from: '[email protected]'
smtp_auth_username: 'alertmanager'
smtp_auth_password: 'password'
#告警模板文件
templates:
- '/etc/alertmanager/template/*.tmpl'
#告警路由规则,所有告警信息进入后的根路由
route:
#告警分组规则,例如,这里表示具有相同alertname值的告警会被分为一组。这个值是可以修改的,并不一定是alertname
group_by: ['alertname']
# 在一个新的告警分组被创建后,需要等待group_wait指定的时间来初始化通知,这种方式可以确保有足够的时间为同一分组获取多条告警,
# 然后一起发送这些告警到接收人
group_wait: 30s
# 同一组告警发送时间间隔,如果一个组第一次告警已经发送,则等待group_interval时间再来发送组内新的告警
group_interval: 5m
#重复告警间隔时间,如果一条告警已经发送成功,则需要等待repeat_interval时间才能重新发送
repeat_interval: 3h
#默认接收人
receiver: team-X-mails
#子路由配置,上面的所有属性都会被子路由,并且可以在每个子路由上覆盖
routes:
# 子路由规则1
- matchers:
- service=~"foo1|foo2|baz"
receiver: team-X-mails
#子路由下还可以继续配置子路由
routes:
- matchers:
- severity="critical"
receiver: team-X-pager
#子路由规则2
- matchers:
- service="files"
receiver: team-Y-mails
routes:
- matchers:
- severity="critical"
receiver: team-Y-pager
#子路由规则3
- matchers:
- service="database"
receiver: team-DB-pager
group_by: [alertname, cluster, database]
routes:
- matchers:
- owner="team-X"
receiver: team-X-pager
continue: true
- matchers:
- owner="team-Y"
receiver: team-Y-pager
#告警抑制规则配置
inhibit_rules:
#此配置表示如果发生多个告警时,它们的alertname和node标签值相同,那么产生critical级别的告警就不产生warning级别的告警。告警级别可以在Prometheus的rules中定义
- source_matchers: [severity="critical"]
target_matchers: [severity="warning"]
equal: [alertname, node]
#告警接收人定义
receivers:
- name: 'team-X-mails'
email_configs:
- to: '[email protected]'
- name: 'team-X-pager'
email_configs:
- to: '[email protected]'
pagerduty_configs:
- service_key: <team-X-key>
- name: 'team-Y-mails'
email_configs:
- to: '[email protected]'
- name: 'team-Y-pager'
pagerduty_configs:
- service_key: <team-Y-key>
- name: 'team-DB-pager'
pagerduty_configs:
- service_key: <team-DB-key>
关于告警的分组、抑制和静默解释:
- 分组:将同类型的警告进行分组,并将同组的多个告警合并为一个通知发送,避免短时间内收到大量告警通知,被告警通知淹没
- 抑制:当某条告警已经发送,停止重复发送由此告警引起的其它告警。例如当一个节点down后,其上部署的服务也会触发不可用的告警,这时候就可以配置忽略由于节点down而造成的服务不可用告警
- 静默:一个简单的定时静音机制,例如服务器需要升级维护时,可以设置这个时间段内告警静默,不再发送告警通知
在AlertManager中通过路由(route)来定义告警的处理方式。路由是一个基于标签匹配的树状怕匹配结构,根据接收到告警的标签匹配相应的处理方式。路由树状结构大致如下图所示:
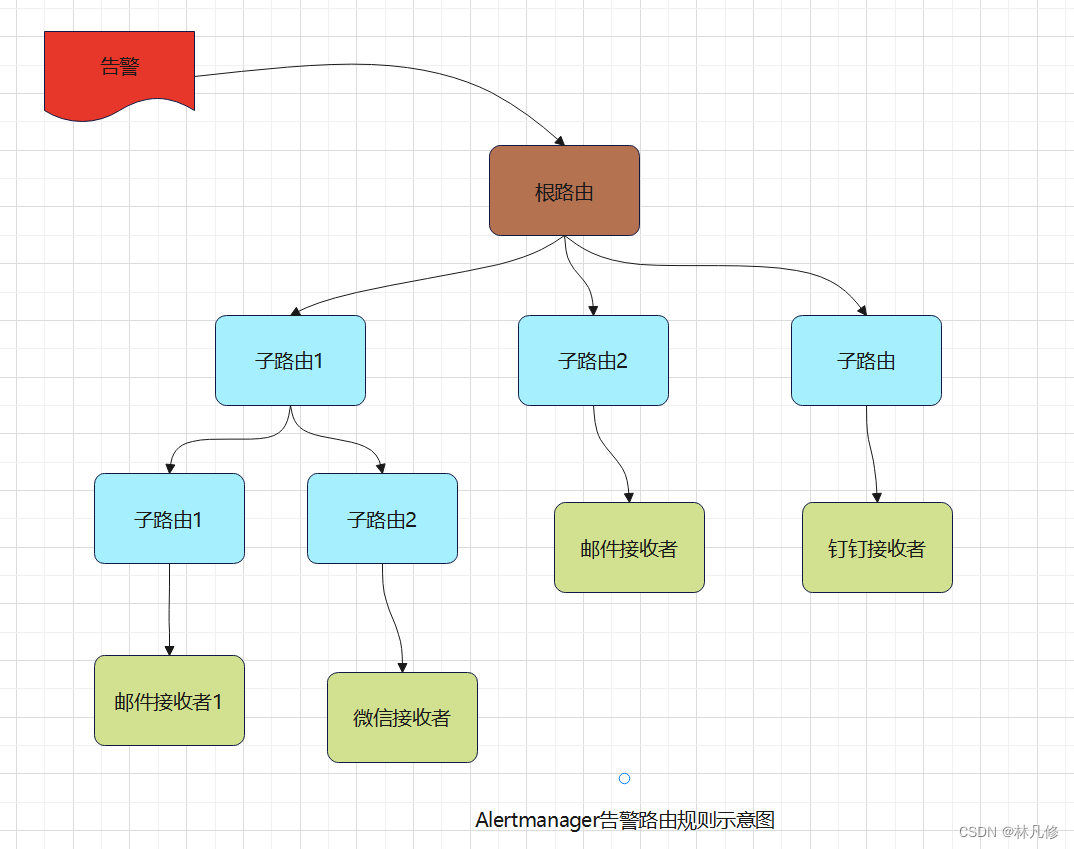
默认情况下,Alertmanager接收到的每个告警都会先到根路由(配置文件中的route字段),然后遍历匹配所有的子路由(配置中的route.routes字段),再往下遍历匹配子路由的子路由(配置中的route.routes.routes字段),以此类推,直到找到最深的匹配的路由,并将告警通知发送到此路由定义的接收者。但如果路由中设置了continue的值为false,那么告警在匹配到第一个子节点之后就会停止,不再继续往下匹配。如果不能匹配任何一个子路由,那么告警会基于当前路由节点定义规则进行处理。
其中告警的匹配使用matchers字段定义,标签和标签值可以使用等值匹配或者正则表达式匹配,具体可以参考官方文档:https://prometheus.io/docs/alerting/latest/configuration/#matcher
需要注意:根路由必须匹配所有的告警,即不能设置matchers
关于路由设置中的几个时间配置,也需要详细解释一下:
- group_wait:当Altertmanager收到一条新告警时,会先根据group_by指定的标签为其确定一个组,然后等待group_wait指定时间,在此时间段内如果收到同一个group的其它告警,则这些告警会被合并为一条通知发送给接收人,可以认为Alertmanager发送通知的单位是组
- group_interval:在一个组的告警被第一次发送后,该组会进入睡眠/唤醒周期,睡眠时长为group_interval指定时间,在睡眠期间该group不会进行任何发送告警的操作(但会插入/更新group中的内容),睡眠结束后进入唤醒状态,然后检查是否需要发送新的告警通知或者重复已发送的告警(resolved类型的告警在发送完成后会从group中剔除)。这就是group_interval的作用
- repeat_interval:如果一条告警已经发送成功,则需要等待repeat_interval时间才能重复发送。但是repeat_interval并不能真正代表告警的实际重复间隔,假如一条告警达到了repeat_interval时间,但它所属的组此时还处于睡眠状态,此时是无法发送重复告警的。所以实际的重复告警间隔应该大于repeat_interval,但小于repeat_interval+group_interval
Prometheus rule文件配置
Prometheus的rule文件是用来定义告警触发规则,主要是使用PromQL语句来查询指标,然后进行判断。可以参考官方文档介绍:https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
下面是一个示例rule文件:
groups:
- name: alertmanager_pod.rules #告警规则组名,注意这和Altermanager中的组不是一个概念
rules:
- alert: Pod_all_cpu_usage #告警名称,对应标签alertname
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{
image!=""}[5m]))*100) > 10 #告警表达式
for: 2m #持续时长,表示上面的表达式满足且超过两分钟才会触发告警
labels: #对告警附加的标签
severity: critical
service: pods
project: myserver
annotations: #告警通知中的注释内容,可用于描述告警具体信息
description: 容器 {
{
$labels.name }} CPU 资源利用率大于 10% , (current value is {
{
$value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
#expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 10 #内存大于10%
expr: sort_desc(avg by(name)(irate(node_memory_MemFree_bytes {
name!=""}[5m]))) > 2*1024*1024*1024 #内存大于2G
for: 2m
labels:
severity: critical
project: myserver
annotations:
description: 容器 {
{
$labels.name }} Memory 资源利用率大于 2G , (current value is {
{
$value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
#expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 50*1024*1024
expr: sum by (name)(irate(container_network_receive_bytes_total{
container_name="POD"}[1m])) > 0
for: 2m
labels:
#severity: critical
project: myserver
annotations:
description: 容器 {
{
$labels.name }} network_receive 资源利用率大于 50M , (current value is {
{
$value }})
- alert: node内存可用大小
expr: node_memory_MemFree_bytes < 524288000 #内存小于500兆
for: 30s
labels:
project: node
annotations:
description: node节点可用内存小于500M
修改Prometheus配置,加载此rule文件
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets: #指定alertmanager地址,可以指定多个,Prometheus会将告警发到这些指定的Alertmanager
- 192.168.122.21:9093
rule_files: #指定要加载的rule文件
- "/usr/local/prometheus/rules/test-rules.yml"
配置修改之后重启Prometheus
systemctl restart prometheus
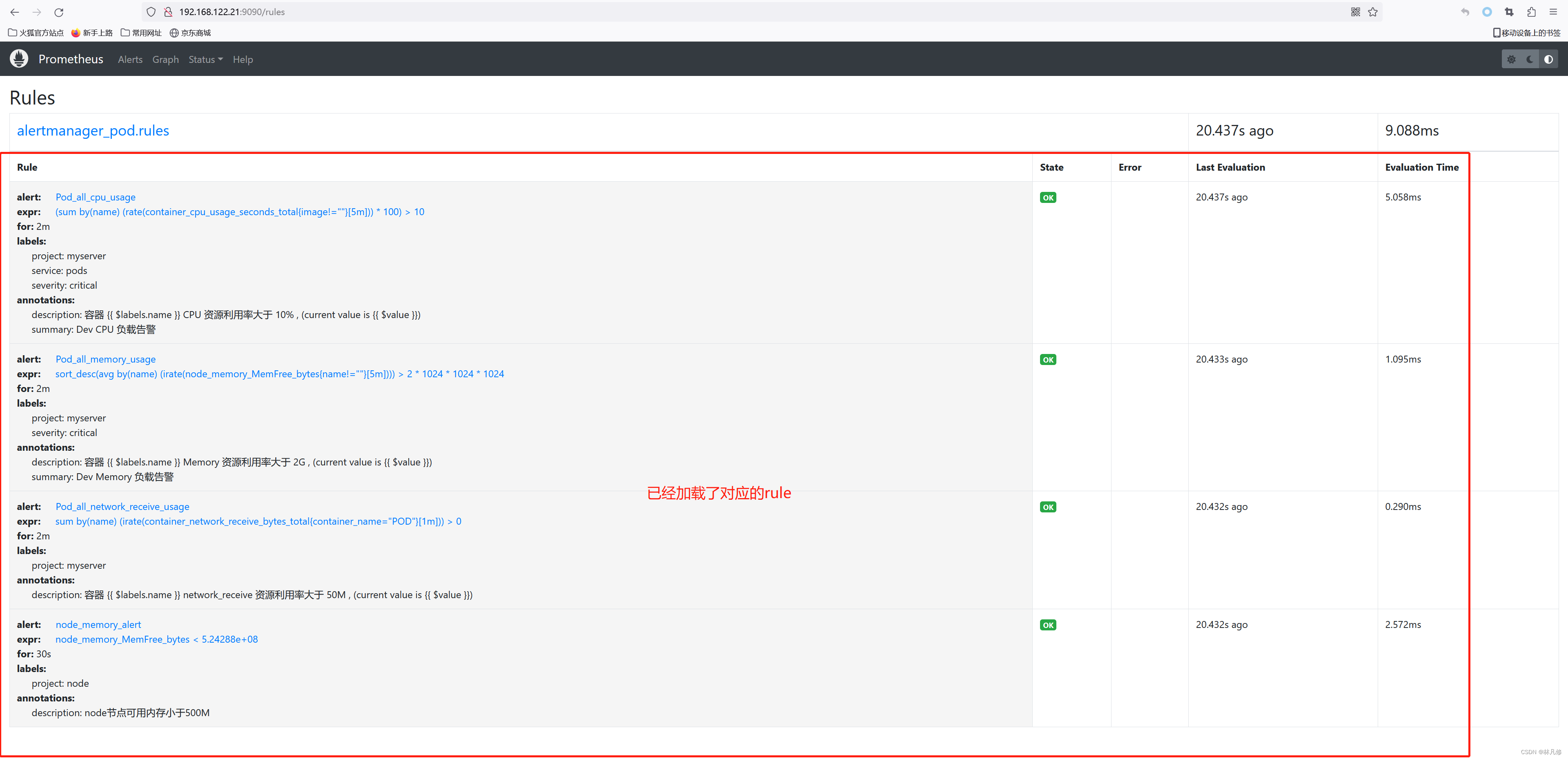
在Prometheus界面查看是否已经加载对应的rule
邮件告警
开启邮箱授权
以QQ邮箱为例,开启邮箱的POP3/SMTP服务
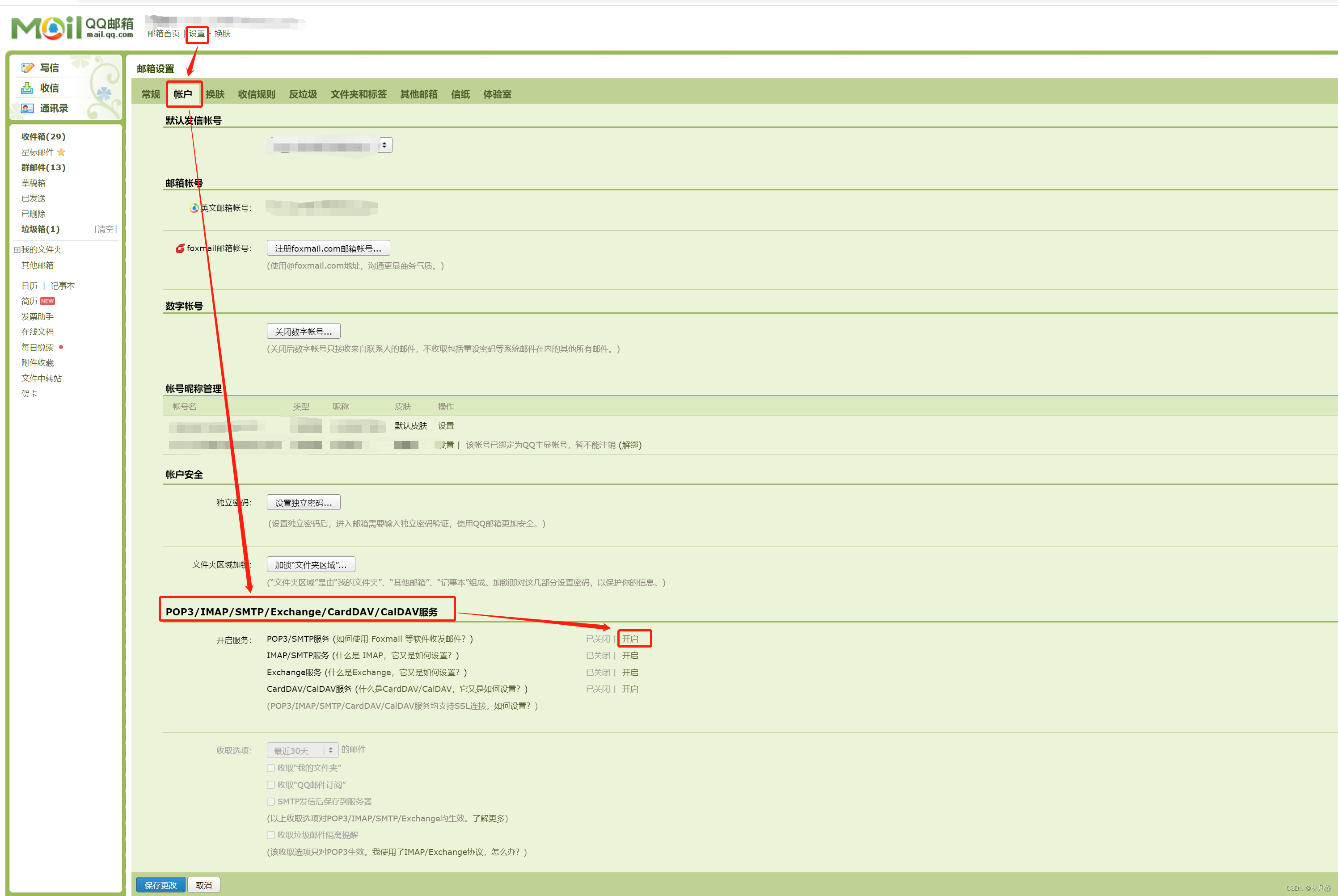
开启之后会得到一个授权码,妥善保存
配置Alertmanager
修改Alertmanager配置,添加邮件服务器配置、告警路由规则配置和告警接收者配置
global:
resolve_timeout: 5m
#添加邮件服务器配置
smtp_from: "[email protected]" #指定发件人地址
smtp_smarthost: "smtp.qq.com:465" #smtp服务器地址
smtp_auth_username: "[email protected]" #邮箱服务器认证用户名
smtp_auth_password: "xxxxx" #邮箱服务器认证密码。QQ邮箱是之前获取的授权码
smtp_require_tls: true #访问smtp服务器是否需要tls
smtp_hello: "qq.com" #向SMTP服务器发送测试消息的内容
#添加告警路由规则,目前只有根路由,所以所有的告警都会发给默认接收者email-receiver
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receiver: 'email-receiver' #指定告警消息接收者
receivers:
#添加email-receiver接收者
- name: email-receiver
email_configs: #邮件配置
- send_resolved: true #是否发送告警恢复消息
to: [email protected] #收件人
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置修改完成后,重启Alertmanager
systemctl restart alertmanager
验证
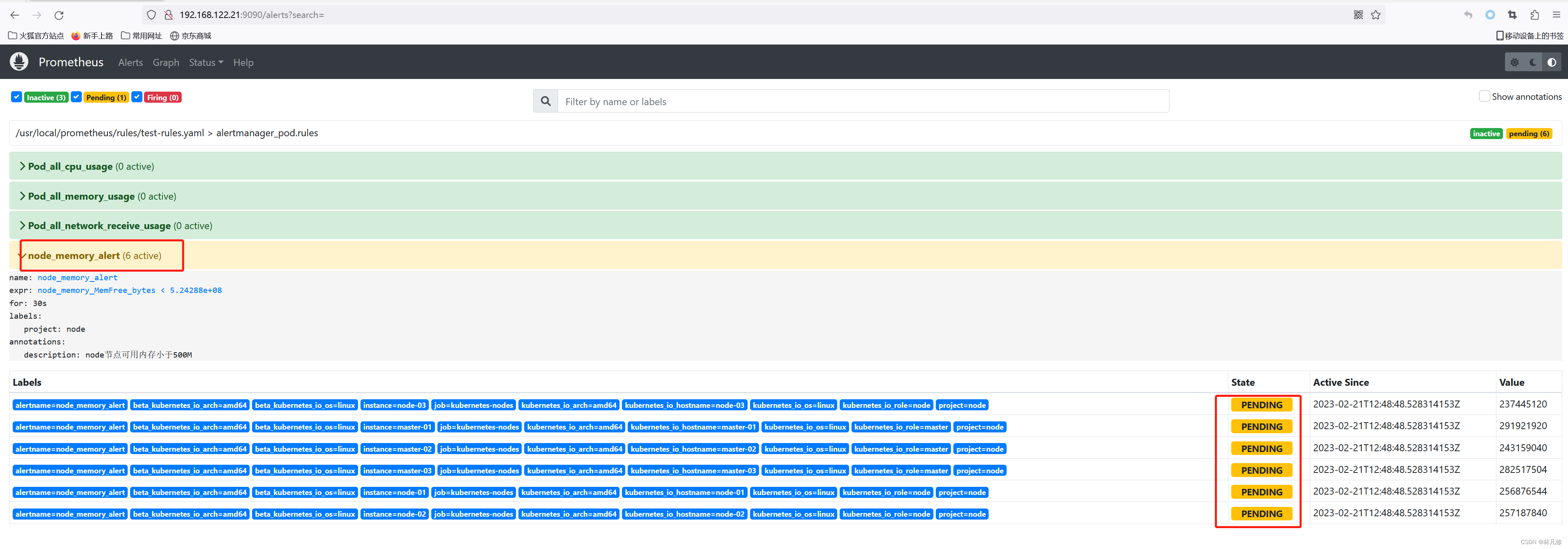
在Prometheus界面查看Alerts,如下图所示,可以看到在node_memory_alert这个规则下有六条告警处于Pending状态
等待一段时间刷新再看,发现这六条告警已经变为Firing状态,如下图,这表示已经将告警发送至Alertmanager
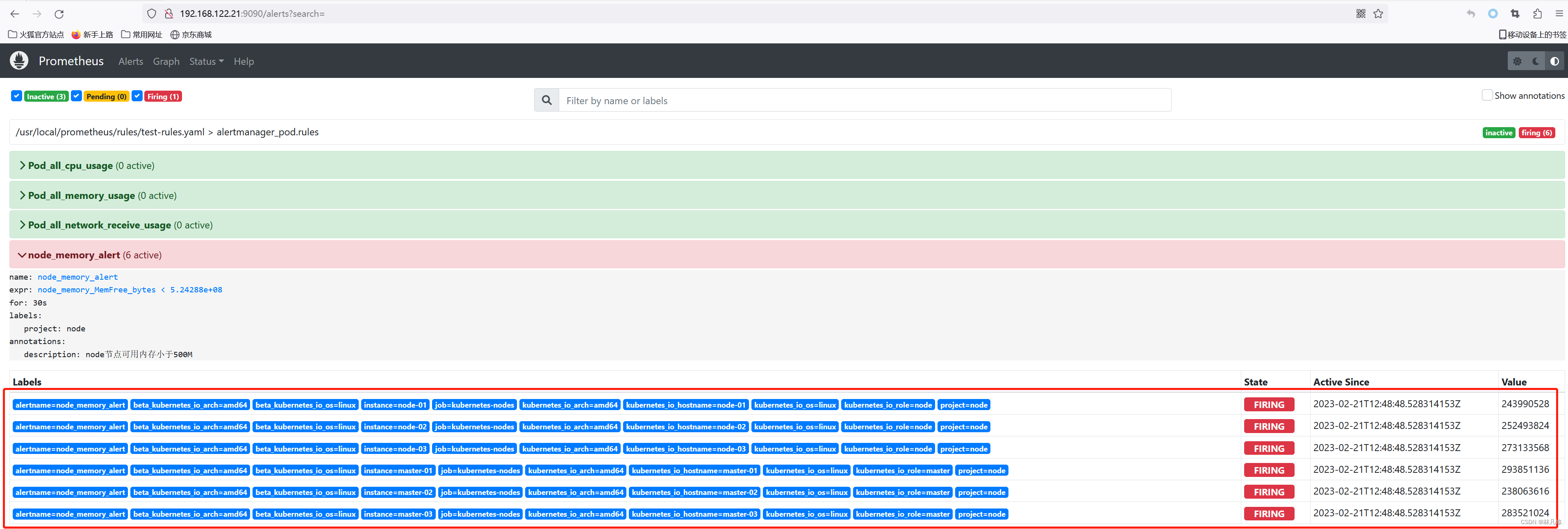
Prometheus中的告警存在3中状态:
- inactive:表示无事件发生,没有告警
- pending:已经触发阈值但为满足告警持续时间(即rule中的for字段)
- firing:已经触发阈值且满足持续时间,并且已经将告警发送至Alertmanager
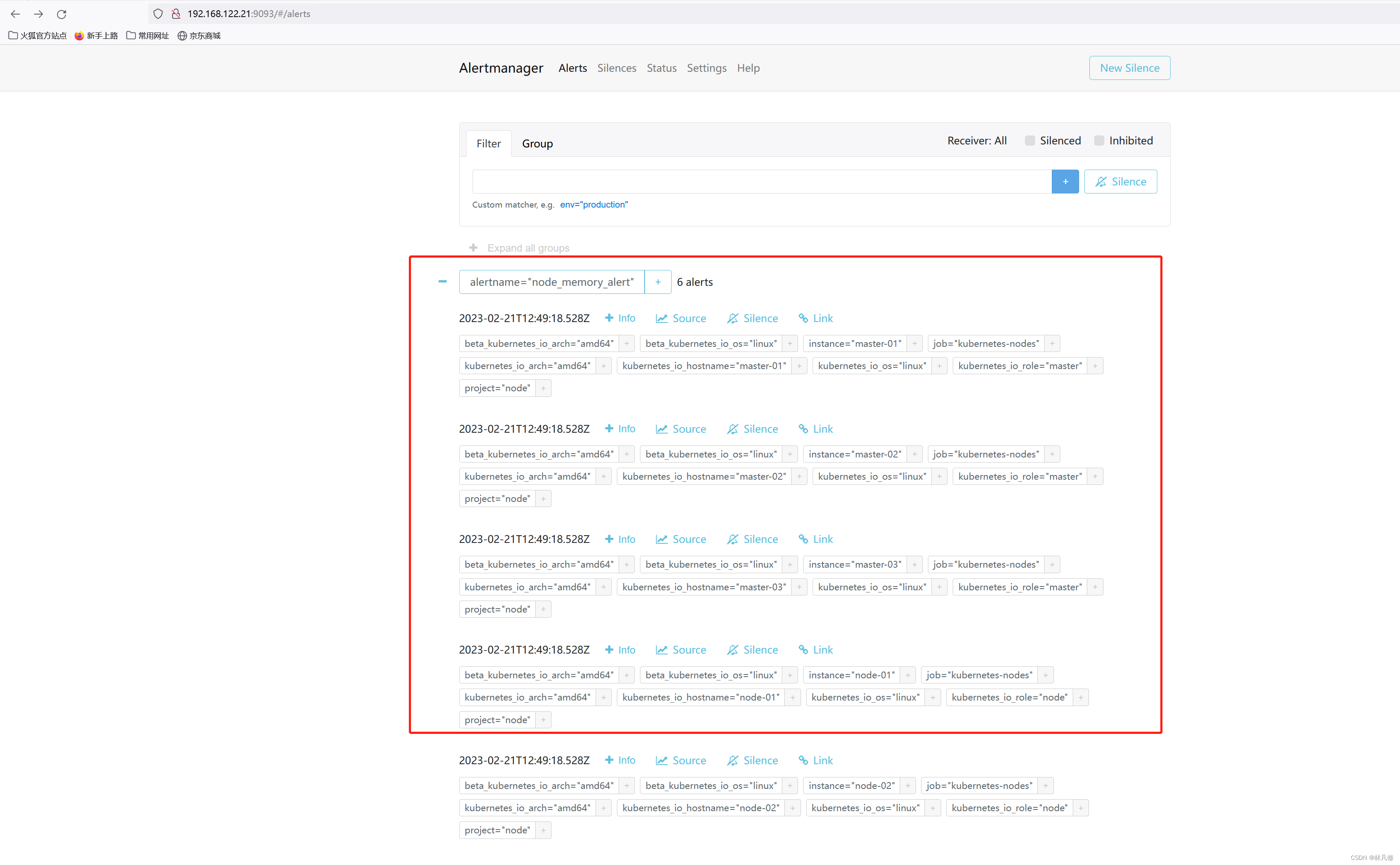
在Alertmanager界面查看数据,确实收到了这六条告警,如下图:
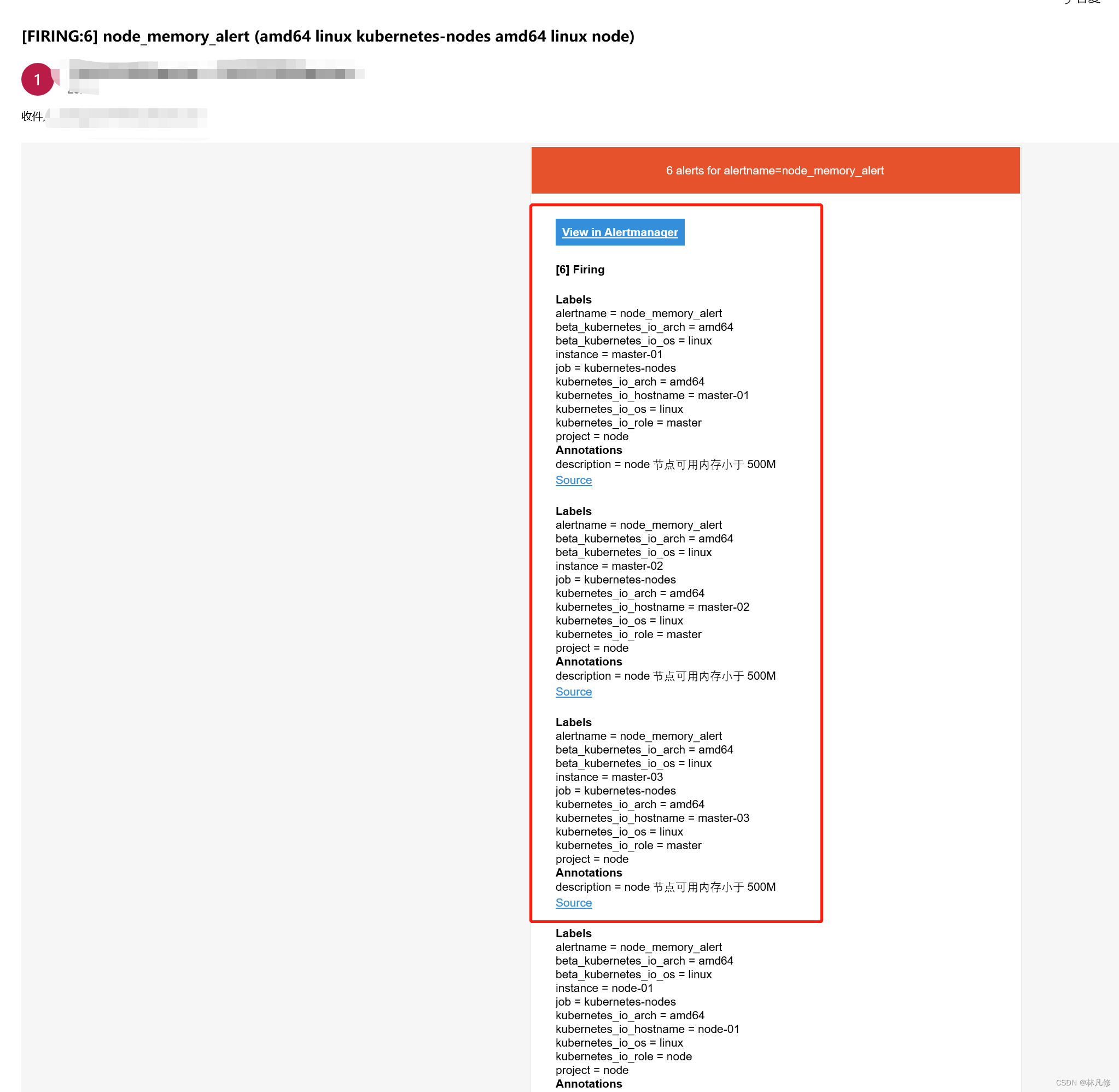
在目标邮箱中查看,也收到了关于这六条告警的通知,如下图:
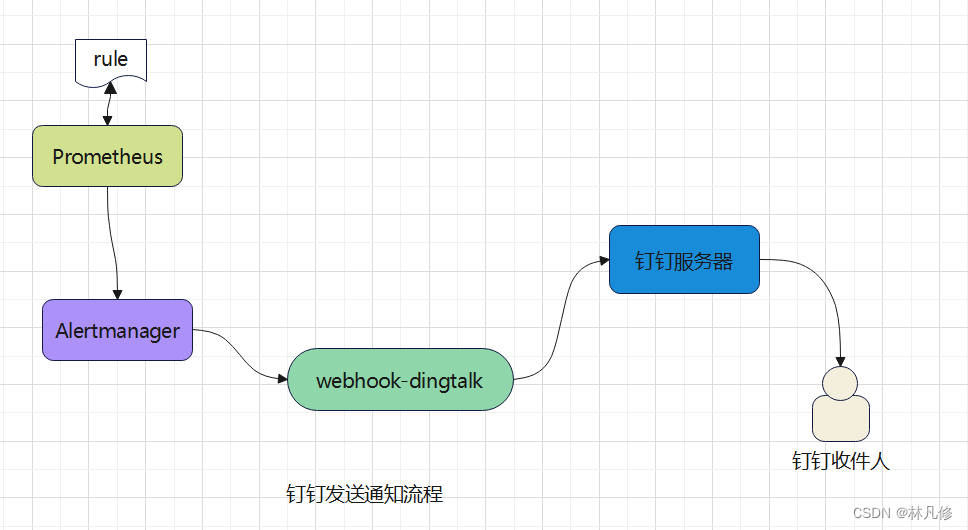
钉钉告警
Alertmanager目前还不支持直接向钉钉发送通知,需要借助一个代理程序webhook-dingtalk实现,其流程大概如下图所示:
钉钉创建群组和群组机器人
在钉钉群聊的群设置中选择机器人管理,然后点击添加机器人
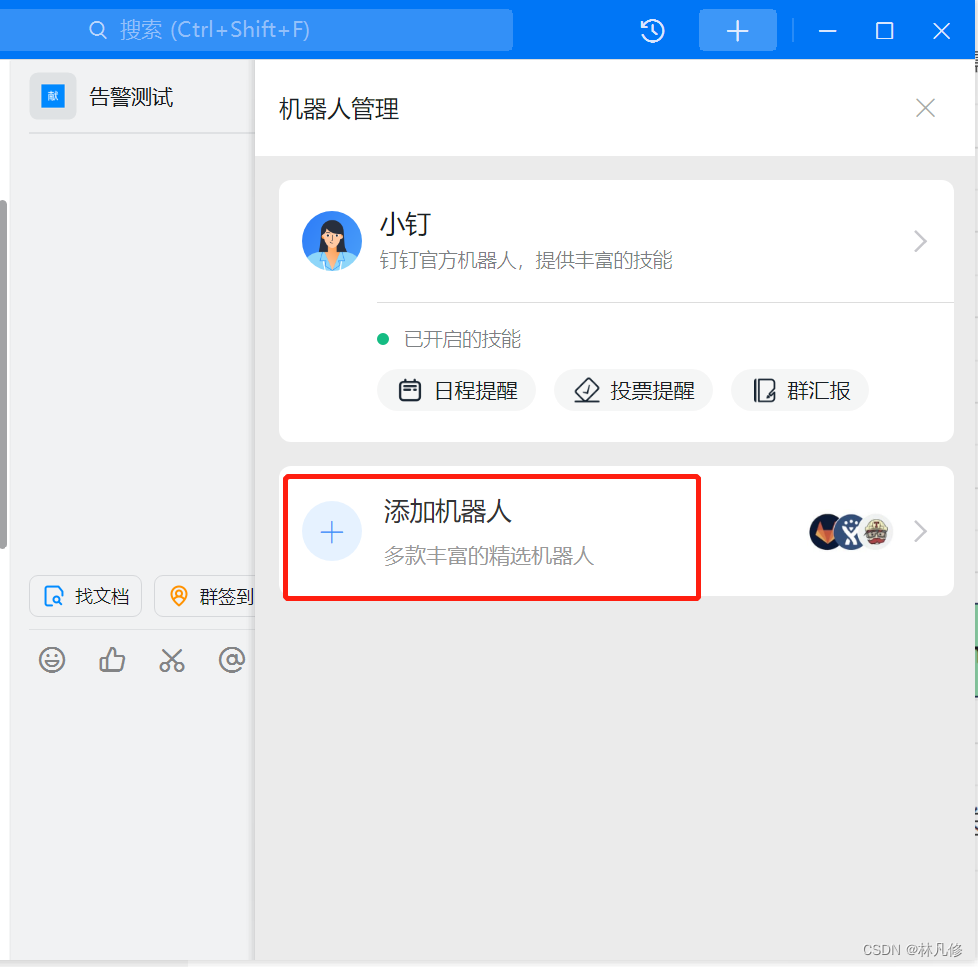
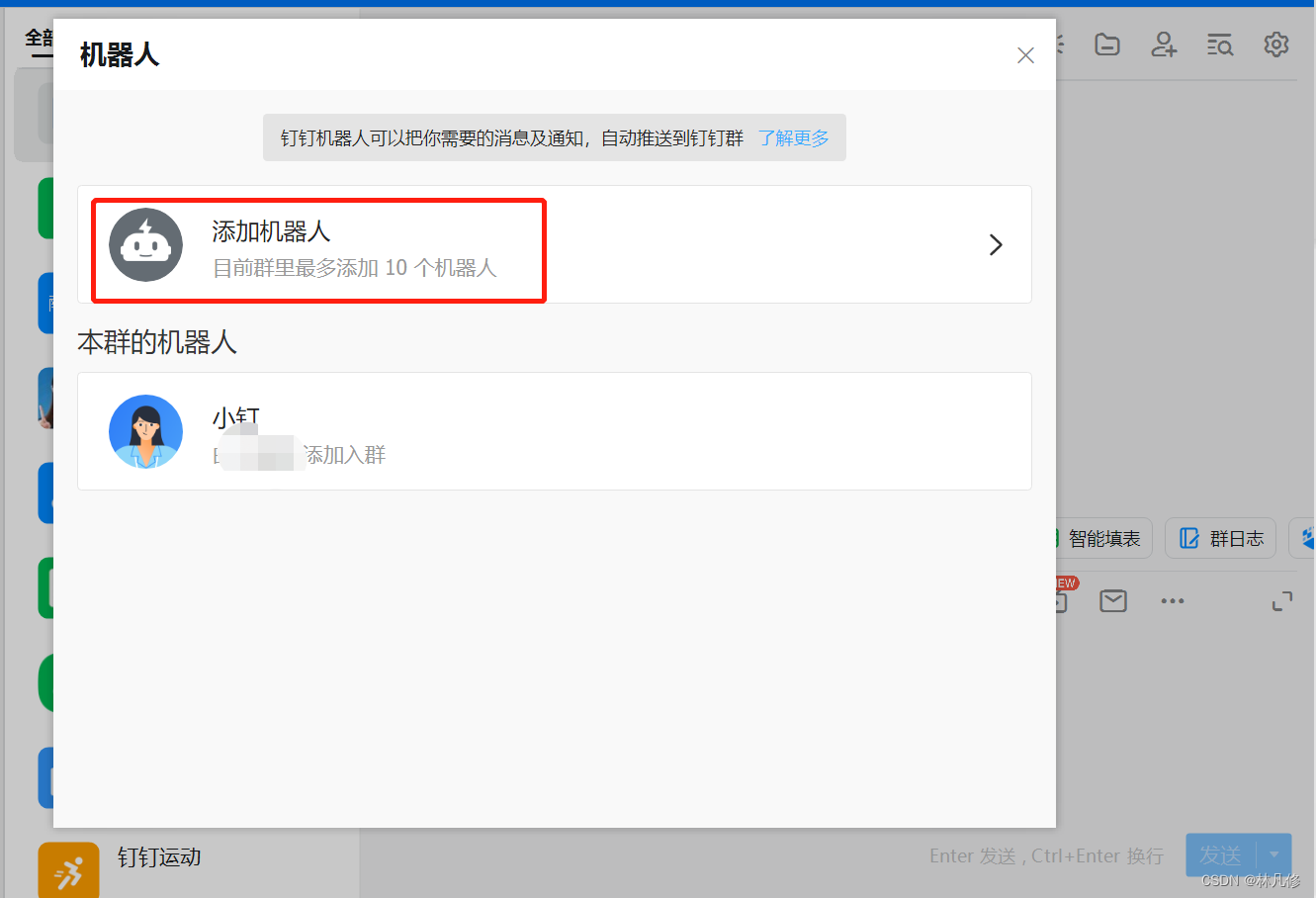


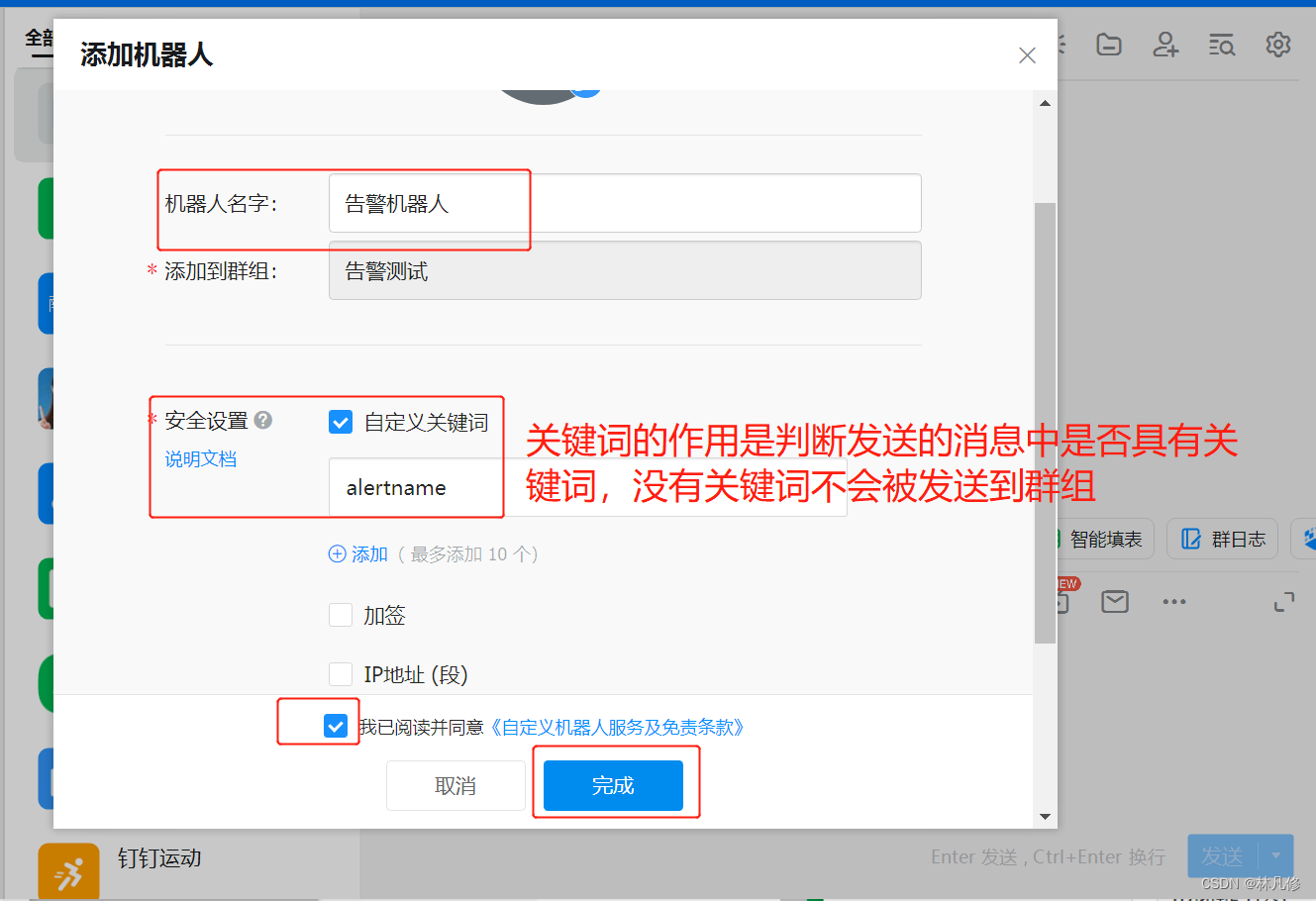
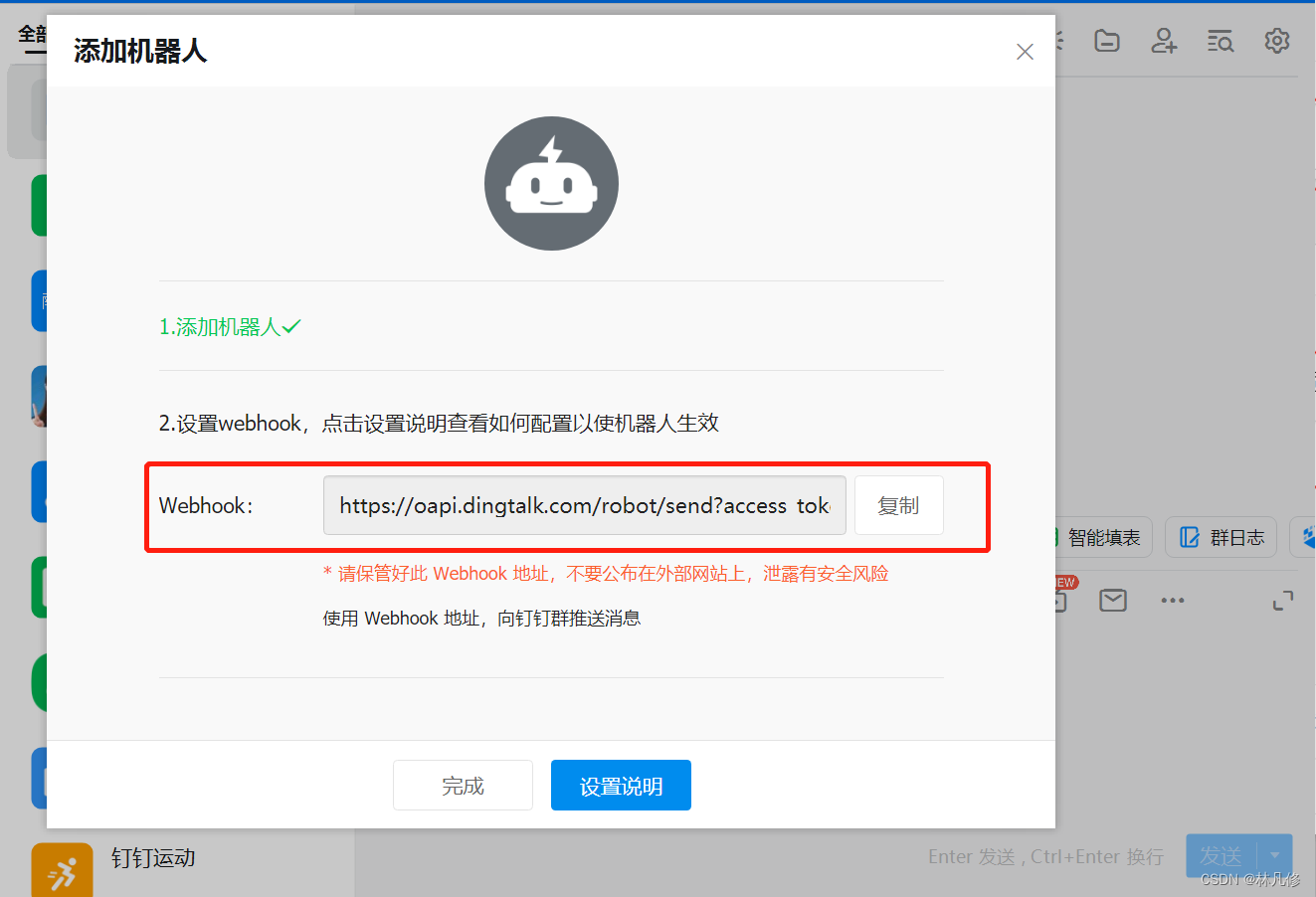
最后会得到一个webhook地址,包含access-token,请妥善保存,避免泄露之后别人利用此地址发送垃圾信息
部署webhook-dingtalk
webhook-dingtalk项目地址:https://github.com/timonwong/prometheus-webhook-dingtalk
下载安装包
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0/prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
tar xf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz -C /usr/local/
ln -sv /usr/local/prometheus-webhook-dingtalk-2.1.0.linux-amd64 /usr/local/prometheus-webhook-dingtalk
/usr/local/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk -h #查看帮助信息
准备service文件
root@prometheus-node-01:~# cat /lib/systemd/system/prometheus-webhook-dingtalk.service
[Unit]
Description=Prometheus Webhook Dingtalk
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --web.listen-address=":8060" --web.enable-ui --web.enable-lifecycle --config.file=/usr/local/prometheus-webhook-dingtalk/config.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
修改webhook-dingtalk配置文件
webhook-dingtalk安装包中默认提供了一个示例配置文件,根据此示例文件进行修改即可
cd /usr/local/prometheus-webhook-dingtalk
cp config.example.yml config.yml
配置文件内容如下,只定义了一个名为webhook1的钉钉接收人配置
targets:
#url是前面创建群组机器人得到的webhook地址
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxxxxxxxxx
配置修改后,启动webhook-dingtalk
systemctl daemon-reload
systemctl start prometheus-webhook-dingtalk.service
systemctl status prometheus-webhook-dingtalk.service
systemctl enable prometheus-webhook-dingtalk.service
确保服务处于正常启动状态,无报错

配置Alertmanager
修改Alertmanager配置,添加一个告警接收者
global:
resolve_timeout: 5m
smtp_from: "[email protected]"
smtp_smarthost: "smtp.qq.com:465"
smtp_auth_username: "[email protected]"
smtp_auth_password: "gzykyatpfkaifhbb"
smtp_require_tls: false
smtp_hello: "qq.com"
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receiver: 'dingtalk-webhook' #将默认接收者也修改为dingtalk-webhook
receivers:
- name: email-receiver
email_configs:
- send_resolved: true
to: [email protected]
# 添加dingtalk-webhook接收者
- name: 'dingtalk-webhook'
webhook_configs:
#url中webhook1对应上边webhook-dingtalk配置中定义的webhook1
- url: 'http://192.168.122.22:8060/dingtalk/webhook1/send'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
修改完成后,重启Alertmanager
systemctl restart alertmanager
验证
重启Prometheus,让其重新构建node内存告警发送到Alertmanager,用来验证钉钉告警通知配置是否生效
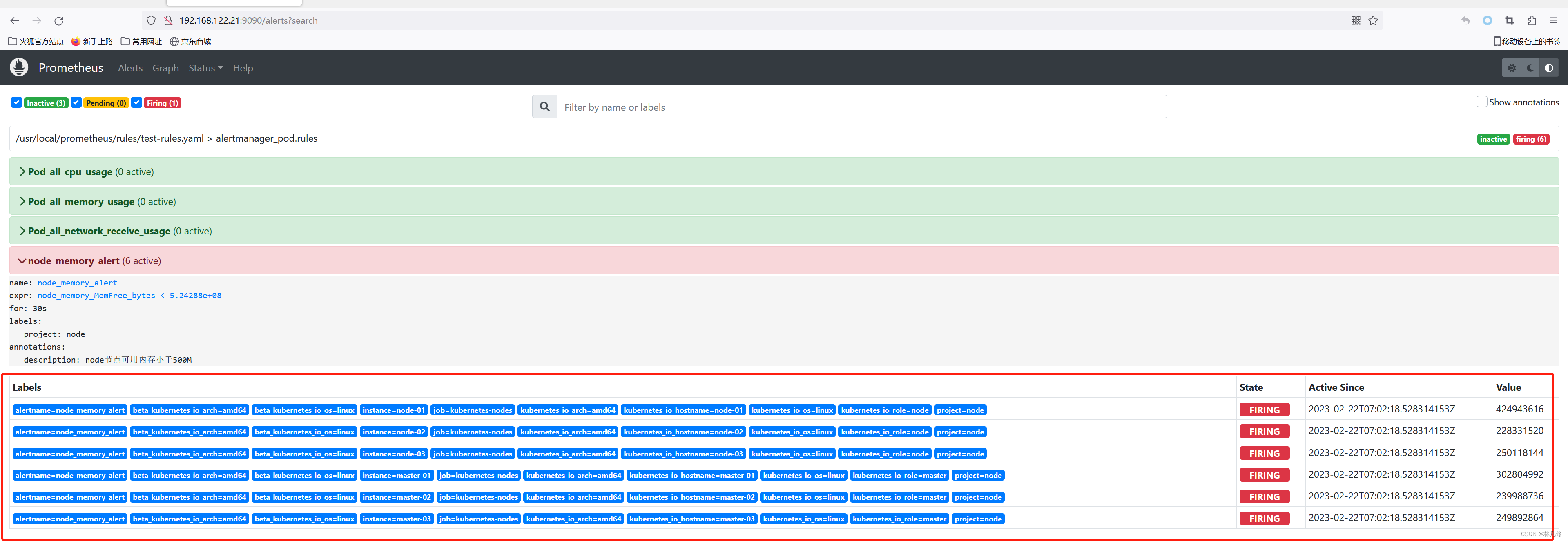
Alertmanager界面上查看
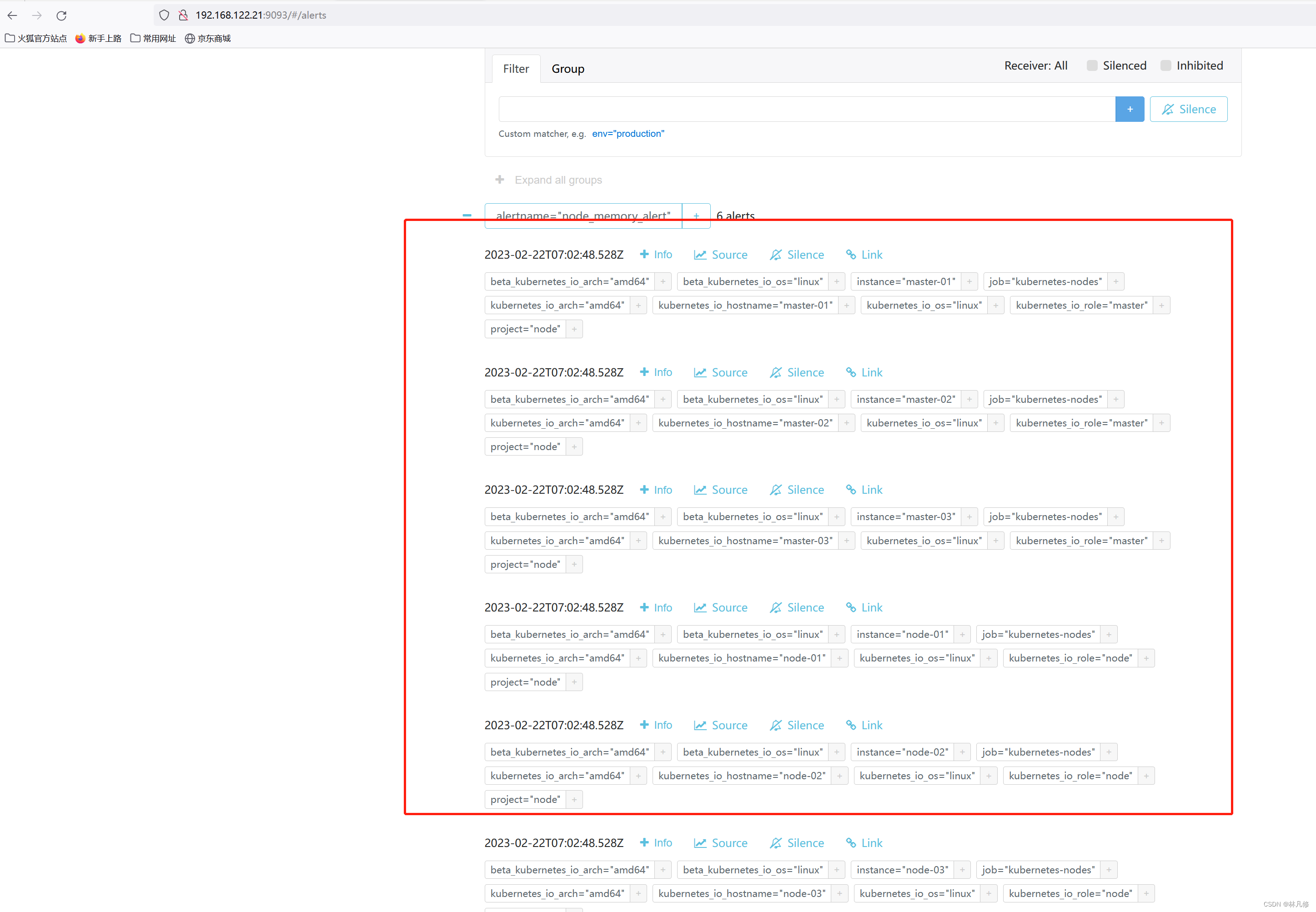
钉钉群组也收到了对应的告警通知
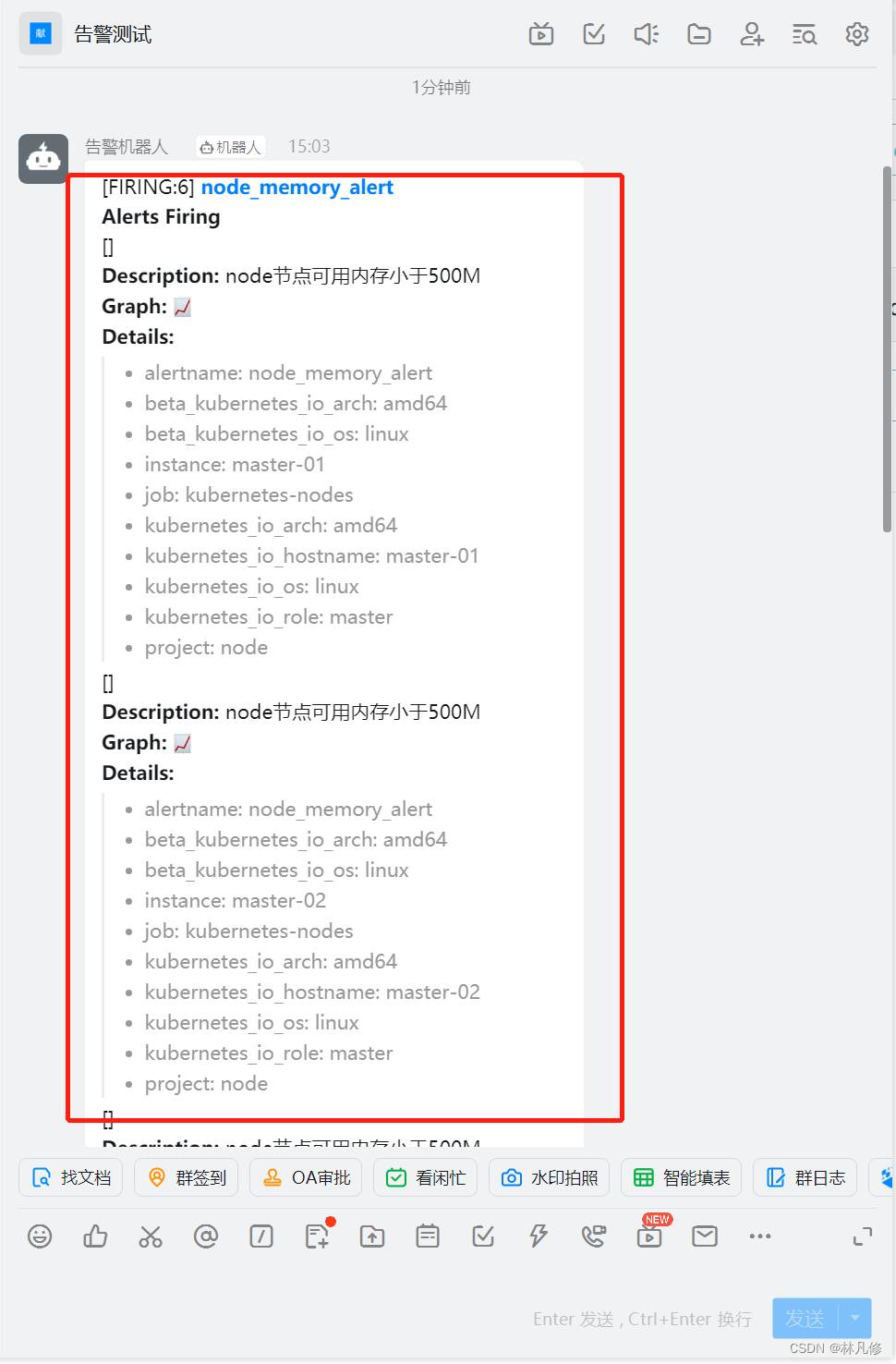
企业微信告警
企业微信配置
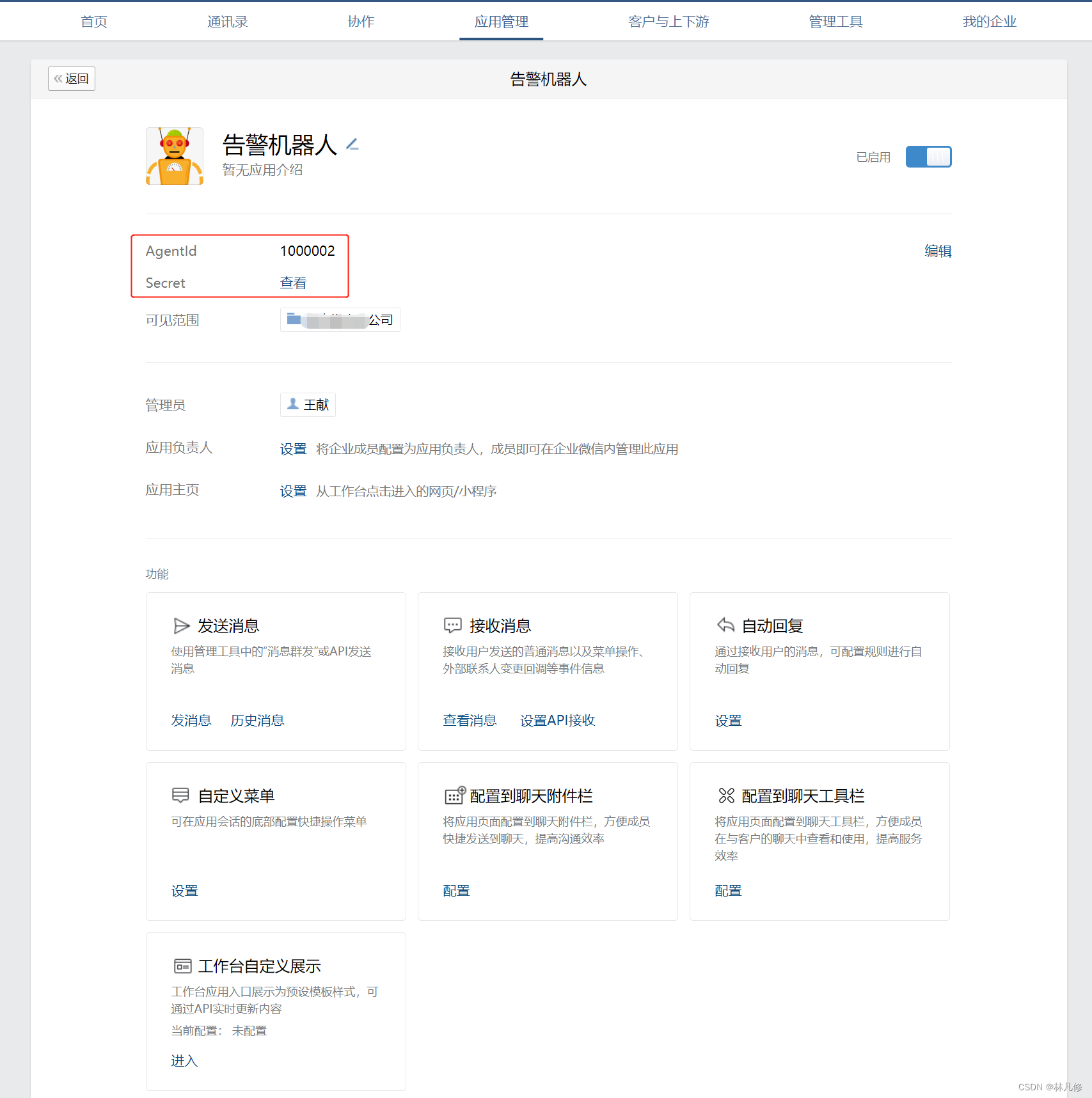
在企业微信管理后台中选择应用管理–>创建应用

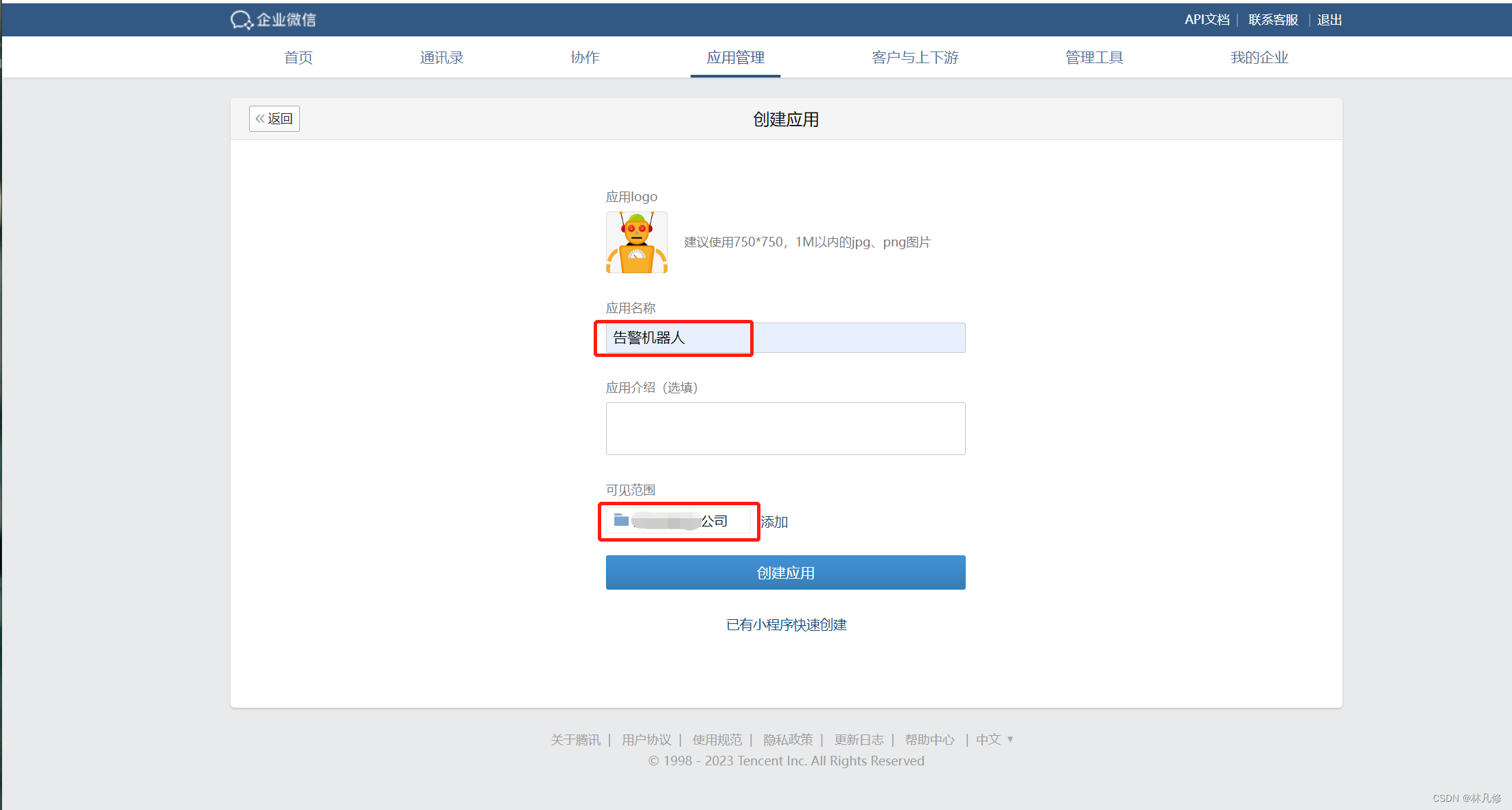
创建完成后,在应用详情界面可以获得一个AgentId和Secret(Secret点击查看会发送到企业微信),请妥善保存
配置Alertmanager
修改Alertmanager配置,添加企业微信接收者
global:
resolve_timeout: 5m
smtp_from: "[email protected]"
smtp_smarthost: "smtp.qq.com:465"
smtp_auth_username: "[email protected]"
smtp_auth_password: "gzykyatpfkaifhbb"
smtp_require_tls: false
smtp_hello: "qq.com"
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receiver: 'wechat' #默认接收者修改为wechat
receivers:
- name: email-receiver
email_configs:
- send_resolved: true
to: [email protected]
- name: 'dingtalk-webhook'
webhook_configs:
- url: 'http://192.168.122.22:8060/dingtalk/webhook1/send'
#添加微信接受者
- name: "wechat"
wechat_configs:
- send_resolved: true
api_secret: xxxxxxxxxxxxxxxxxxxxxxxxxxx #上面在企业微信创建应用之后获取的Secret
corp_id: ww4cc53bff288sdbff #企业微信公司id,可以在企业微信管理后台获得
agent_id: 1000002 #上面在企业微信创建应用之后获取的AgentId
# to_user: '@all' #如果需要发送给指定用户可以使用to_user,@all表示所有人
to_party: 2 #发送给指定的部门,2代表部门ID,部门ID可以在企业微信管理后台获得
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
配置修改完成后重启Alertmanager
systemctl restart alertmanager
验证
重启Prometheus让其重新构建node内存告警发送到Alertmanager,用来验证企业微信告警通知配置是否生效
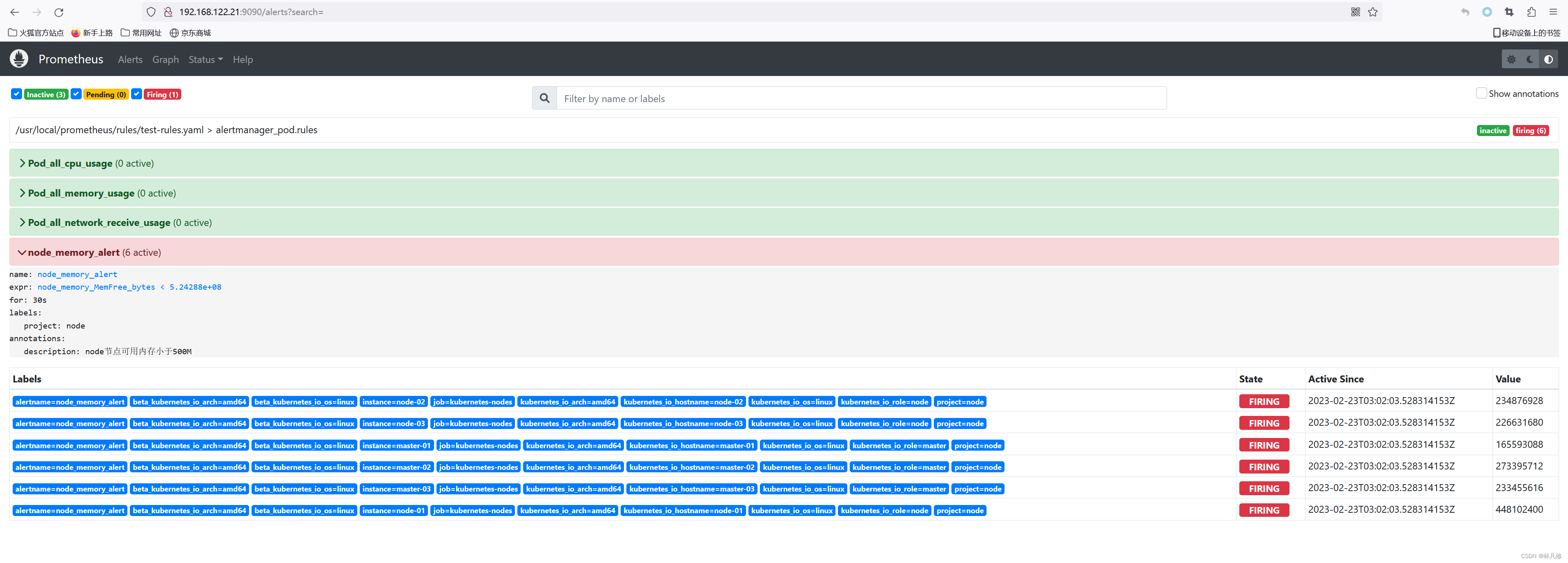
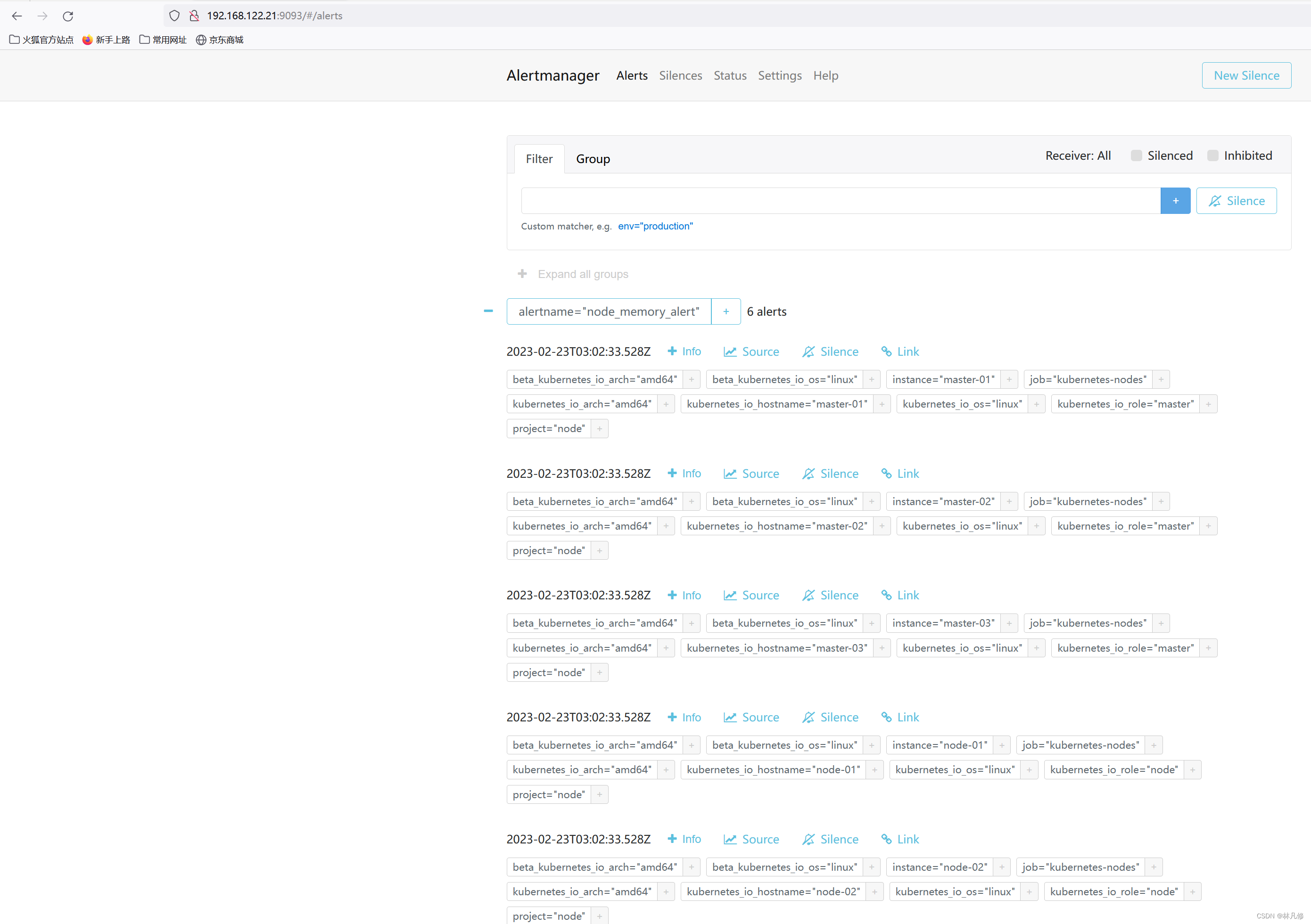
Alertmanager界面上查看
由于企业微信增加了对IP的限制,我所使用的IP不在可信IP之内,所以这里没有在企业微信收到告警信息。Alertmanager报错信息如下:
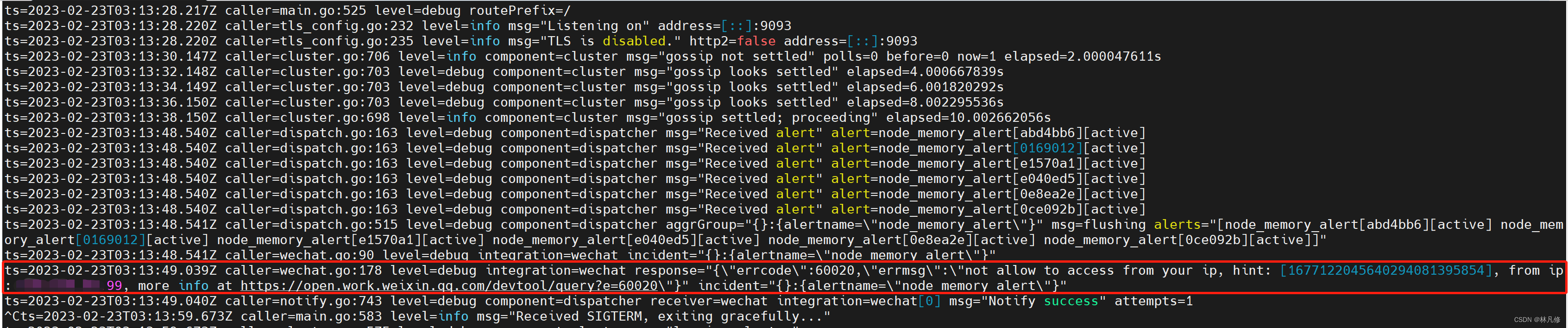
可以在之前创建的企业微信应用详情界面下选择添加可信IP解决此问题。但是由于我没有公司对应的域名进行校验,所以此处不在演示。
告警分类发送
告警分类发送就是利用Alertmanager配置文件中定义的告警路由规则匹配不同的告警然后发送给不同的接收者
groups:
- name: alertmanager_pod.rules
rules:
- alert: Pod_all_cpu_usage
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{
image!=""}[5m]))*100) > 10
for: 2m
labels:
severity: critical
type: pods
annotations:
description: 容器 {
{
$labels.name }} CPU 资源利用率大于 10% , (current value is {
{
$value }})
summary: Dev CPU 负载告警
- alert: Pod_all_memory_usage
#expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""}[5m]))*100) > 10 #内存大于10%
expr: sort_desc(avg by(name)(irate(node_memory_MemFree_bytes {
name!=""}[5m]))) > 2*1024*1024*1024 #内存大于2G
for: 2m
labels:
severity: critical
type: pods
annotations:
description: 容器 {
{
$labels.name }} Memory 资源利用率大于 2G , (current value is {
{
$value }})
summary: Dev Memory 负载告警
- alert: Pod_all_network_receive_usage
#expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 50*1024*1024
expr: sum by (name)(irate(container_network_receive_bytes_total{
namespace="default"}[1m])) > 300 #这里是为了便于触发告警才设置为大于300字节
for: 1m
labels:
severity: critical
type: pods
annotations:
description: 容器 {
{
$labels.name }} network_receive 资源利用率大于 50M , (current value is {
{
$value }})
- alert: node_memory_alert
expr: node_memory_MemFree_bytes < 524288000 #内存小于500兆
for: 1m
labels:
component: memory
type: nodes
annotations:
description: node节点可用内存小于500M
以上面的Prometheus rule文件为例,假如要实现将节点告警发送到钉钉,Pod告警发送至邮件。可以修改Alertmanager规则,添加如下告警路由规则实现:
global:
resolve_timeout: 5m
smtp_from: "[email protected]"
smtp_smarthost: "smtp.qq.com:465"
smtp_auth_username: "[email protected]"
smtp_auth_password: "gzykyatpfkaifhbb"
smtp_require_tls: false
smtp_hello: "qq.com"
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receiver: 'wechat'
#添加子路由规则设置
routes:
#子路由规则1,匹配告警中type标签,如果标签值为pods,将告警通知发送至dingtalk-webhook接收者
- matchers:
- type = pods
receiver: 'dingtalk-webhook'
#子路由规则2,匹配告警中type标签,如果标签值为nodes,将告警通知发送至email-receiver接收者
- matchers:
- type = nodes
receiver: 'email-receiver'
receivers:
- name: 'email-receiver'
email_configs:
- send_resolved: true
to: [email protected]
- name: 'dingtalk-webhook'
webhook_configs:
- url: 'http://192.168.122.22:8060/dingtalk/webhook1/send'
- name: "wechat"
wechat_configs:
- send_resolved: true
api_secret: xxxxxxxxxx
corp_id: xxxxxxxxxx
agent_id: 1000002
#to_user: '@all'
to_party: 2
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
将Prometheus rule文件应用到Prometheus,再修改Alertmanager配置,然后重启Prometheus和Alertmanager进行验证
在Prometheus上查看告警
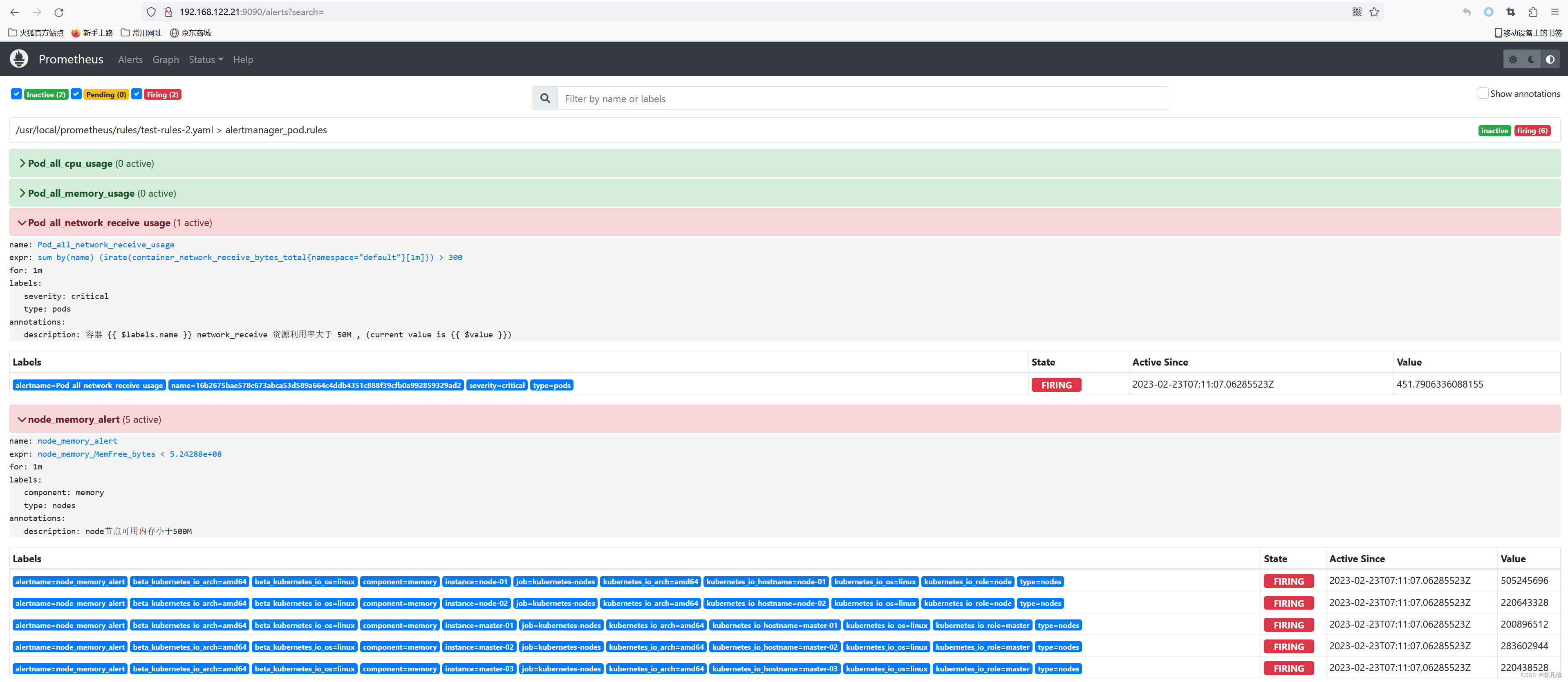
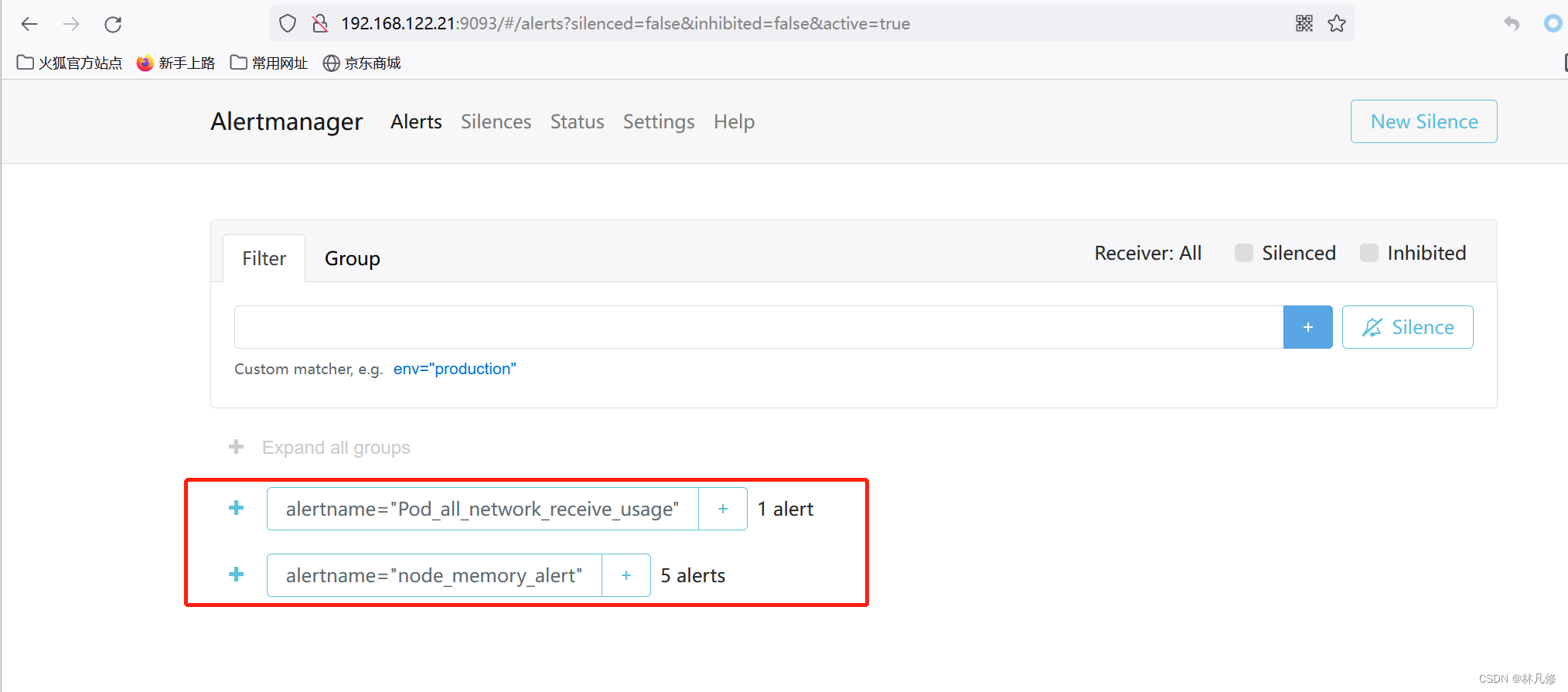
Alertmanager上查看
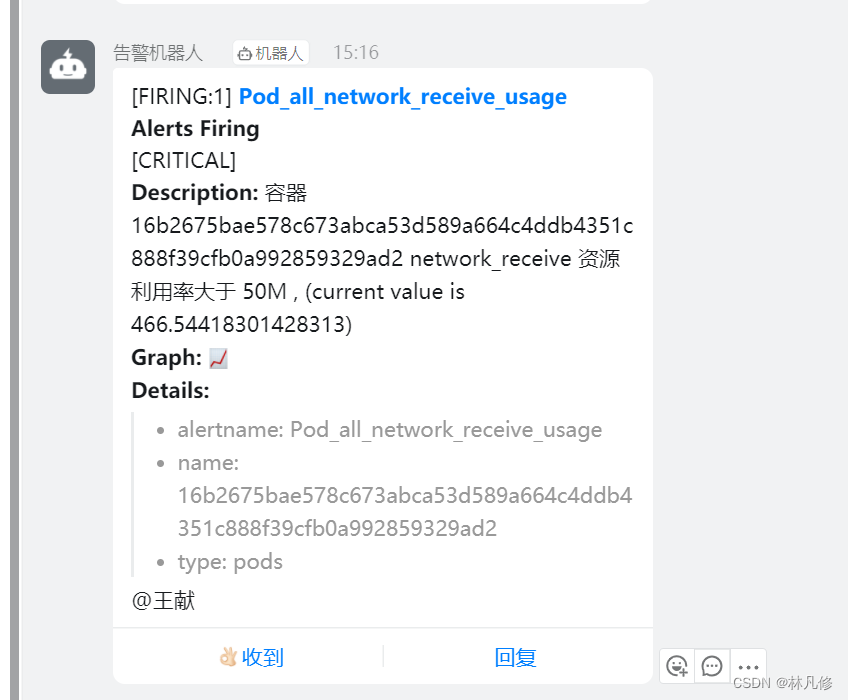
钉钉收到关于容器的告警
邮件收到关于节点的告警
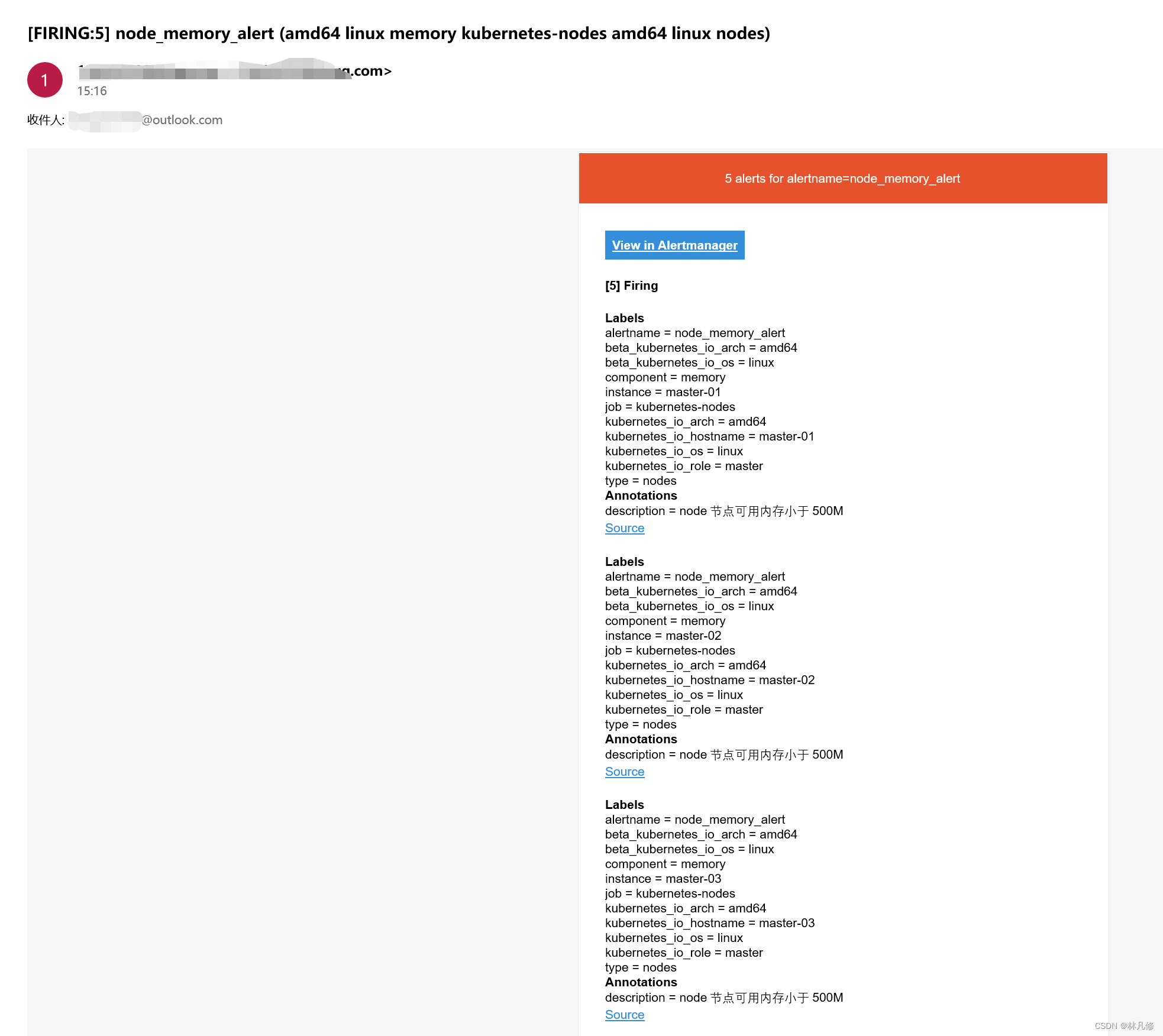
自定义消息模板
默认通知消息比较杂乱,可以定义模板,对其进行格式化,便于阅读
消息模板的官方文档:https://prometheus.io/docs/alerting/latest/notifications/ https://prometheus.io/docs/alerting/latest/notification_examples/
模板使用的是go text/template语法
以企业微信为例,消息模板文件可以定义为如下所示:
#定义一个名为wechat.user_defined.message的块
{
{
define wechat.user_defined.message }}
{
{
range $i, $alert :=.Alerts }}
===alertmanager监控报警===
告警状态: {
{
.Status }}
告警级别: {
{
$alert.Labels.severity }}
告警类型: {
{
$alert.Labels.alertname }}
告警应用: {
{
$alert.Annotations.summary }}
故障主机: {
{
$alert.Labels.instance }}
告警主题: {
{
$alert.Annotations.summary }}
触发阀值: {
{
$alert.Annotations.value }}
告警详情: {
{
$alert.Annotations.description }}
触发时间: {
{
$alert.StartsAt.Format "2006-01-02 15:04:05" }}
===========end============
{
{
end }}
{
{
end }}
修改Alertmanager配置,加载改模板文件,并引用wechat.user_defined.message
global:
resolve_timeout: 5m
smtp_from: "[email protected]"
smtp_smarthost: "smtp.qq.com:465"
smtp_auth_username: "[email protected]"
smtp_auth_password: "gzykyatpfkaifhbb"
smtp_require_tls: false
smtp_hello: "qq.com"
#配置加载指定的模板文件
templates:
- "/usr/local/alertmanager/templates/wechat-messsage-template.templ"
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receiver: 'wechat'
routes:
- matchers:
- type = pods
receiver: 'dingtalk-webhook'
- matchers:
- type = nodes
receiver: 'wechat'
receivers:
- name: 'email-receiver'
email_configs:
- send_resolved: true
to: [email protected]
- name: 'dingtalk-webhook'
webhook_configs:
- url: 'http://192.168.122.22:8060/dingtalk/webhook1/send'
- name: "wechat"
wechat_configs:
- send_resolved: true
api_secret: xxxxxxxxxxxxxx
corp_id: ww4cc53bff288asbff
agent_id: 1000002
#to_user: '@all'
to_party: 2
message: '{
{ template "wechat.user_defined.message" . }}' #指定发送消息时引用的模板
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
最后收到的消息大概如下图所示:
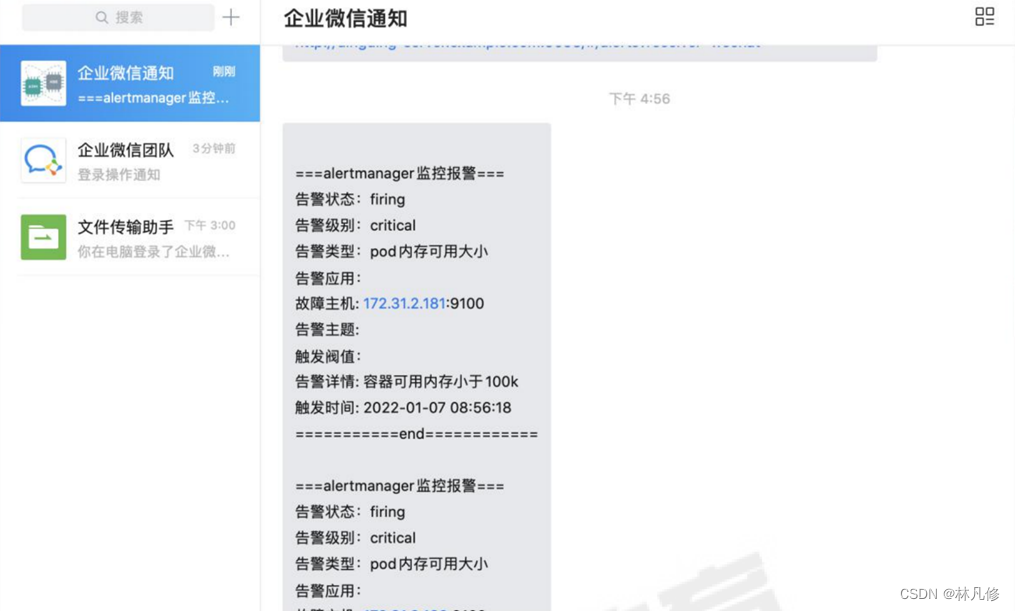
告警抑制
在Prometheus的rule文件中添加下面两条规则用于验证告警抑制:
#磁盘分区使用率超过%60告警规则
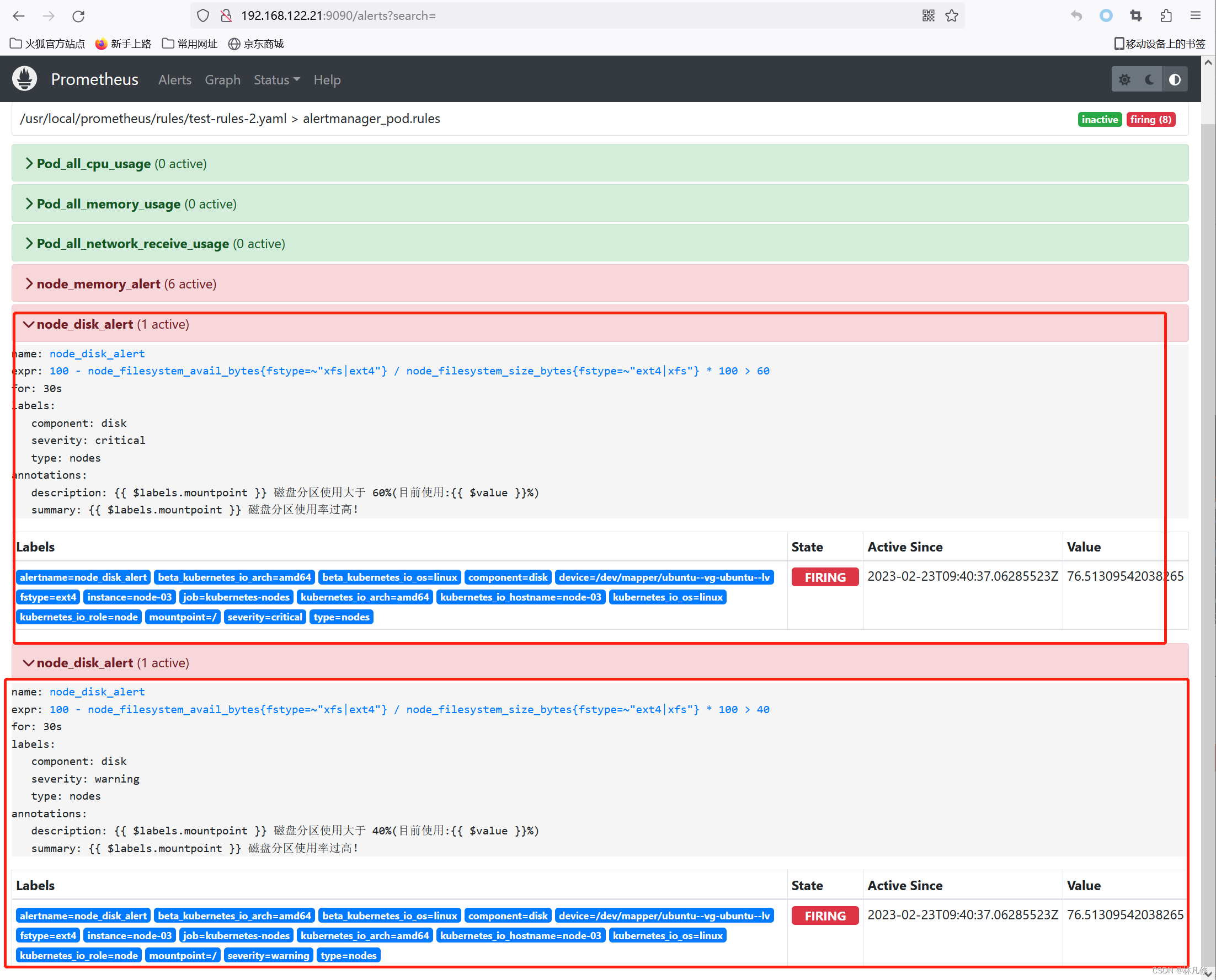
- alert: node_disk_alert
expr: 100 - node_filesystem_avail_bytes{
fstype=~"xfs|ext4"} / node_filesystem_size_bytes{
fstype=~"ext4|xfs"} * 100 > 60
for: 30s
labels:
type: nodes
component: disk
severity: critical
annotations:
summary: "{
{ $labels.mountpoint }} 磁盘分区使用率过高!"
description: "{
{ $labels.mountpoint }} 磁盘分区使用大于 60%(目前使用:{
{ $value }}%)"
#磁盘分区使用率超过%60告警规则
- alert: node_disk_alert
expr: 100 - node_filesystem_avail_bytes{
fstype=~"xfs|ext4"} / node_filesystem_size_bytes{
fstype=~"ext4|xfs"} * 100 > 40
for: 30s
labels:
type: nodes
component: disk
severity: warning
annotations:
summary: "{
{ $labels.mountpoint }} 磁盘分区使用率过高!"
description: "{
{ $labels.mountpoint }} 磁盘分区使用大于 40%(目前使用:{
{ $value }}%)"
重启Prometheus,应用rule文件
systemctl restart prometheus
然后修改Alertmanager配置,添加抑制规则
global:
.......
#告警抑制规则配置
inhibit_rules:
- source_match: #如果两条告警标签alertname、instance、mountpoint值相等的,只发送critical级别的告警,不发送warning级别的
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance', 'mountpoint']
修改完成后,重启Alertmanager
systemctl restart alertmanager
在一个节点上使用dd写一个大文件,让根分区使用率超过%60
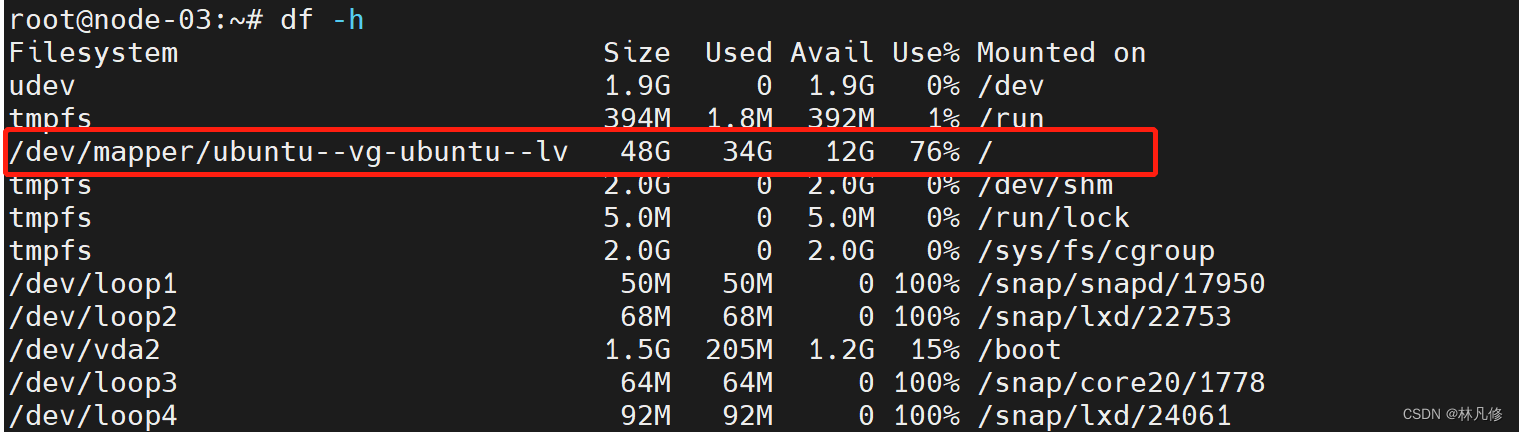
等待一段时间验证告警,
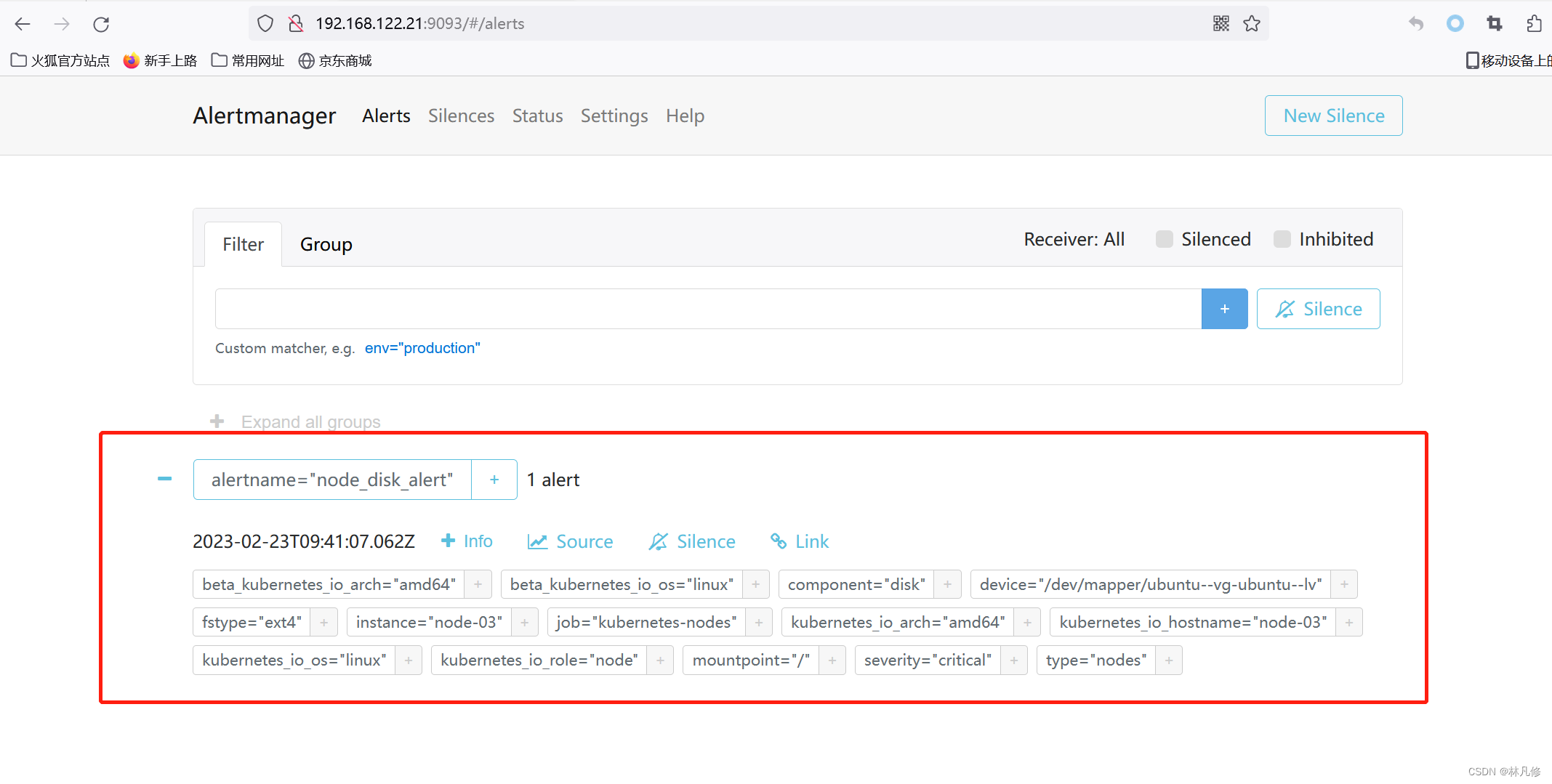
最后在邮箱中查看,可以看到只收到一条磁盘使用率超过%60的告警通知,没有%40的通知

告警静默
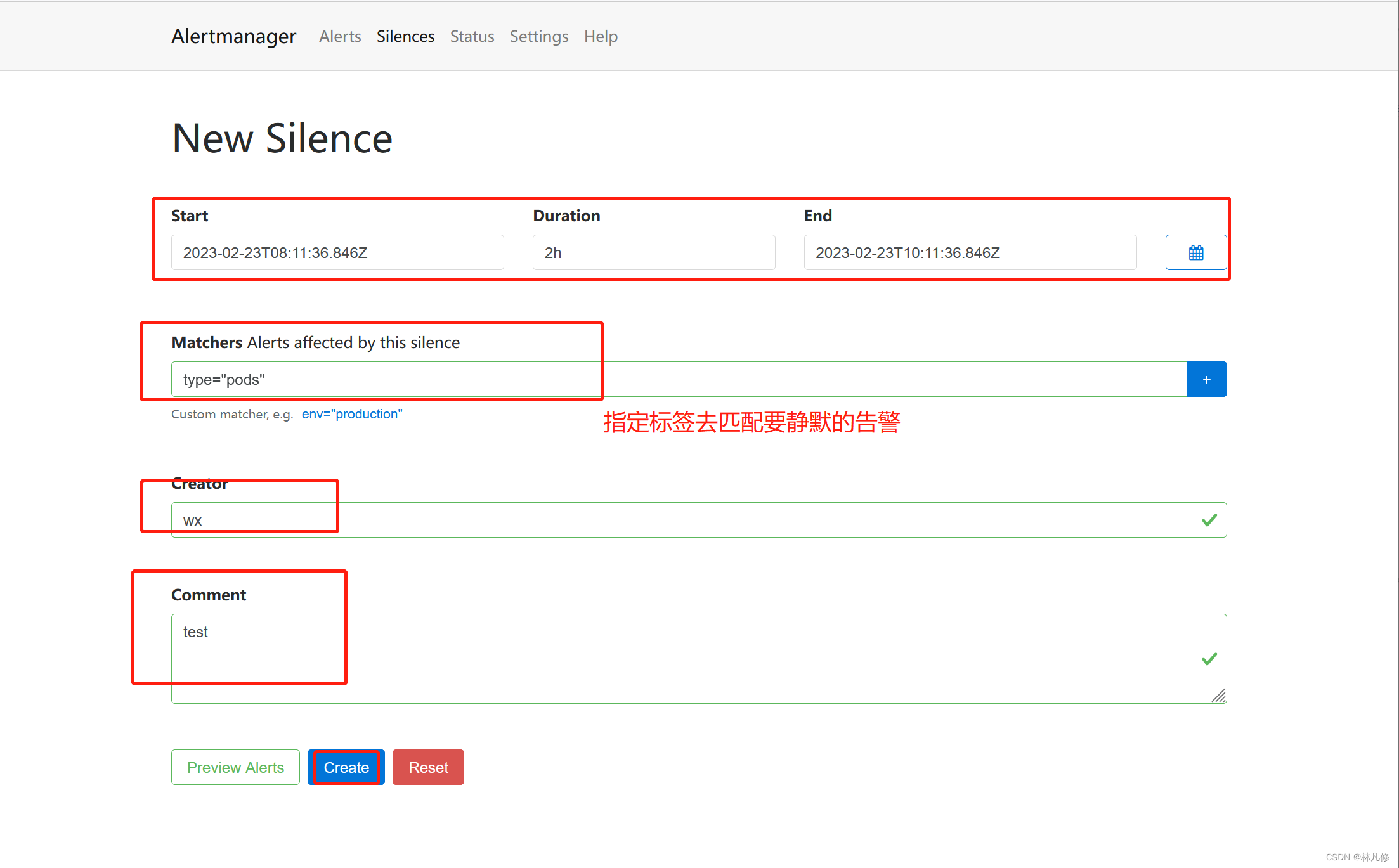
针对于在Alertmanager上已存在的告警,可以直接选择静默
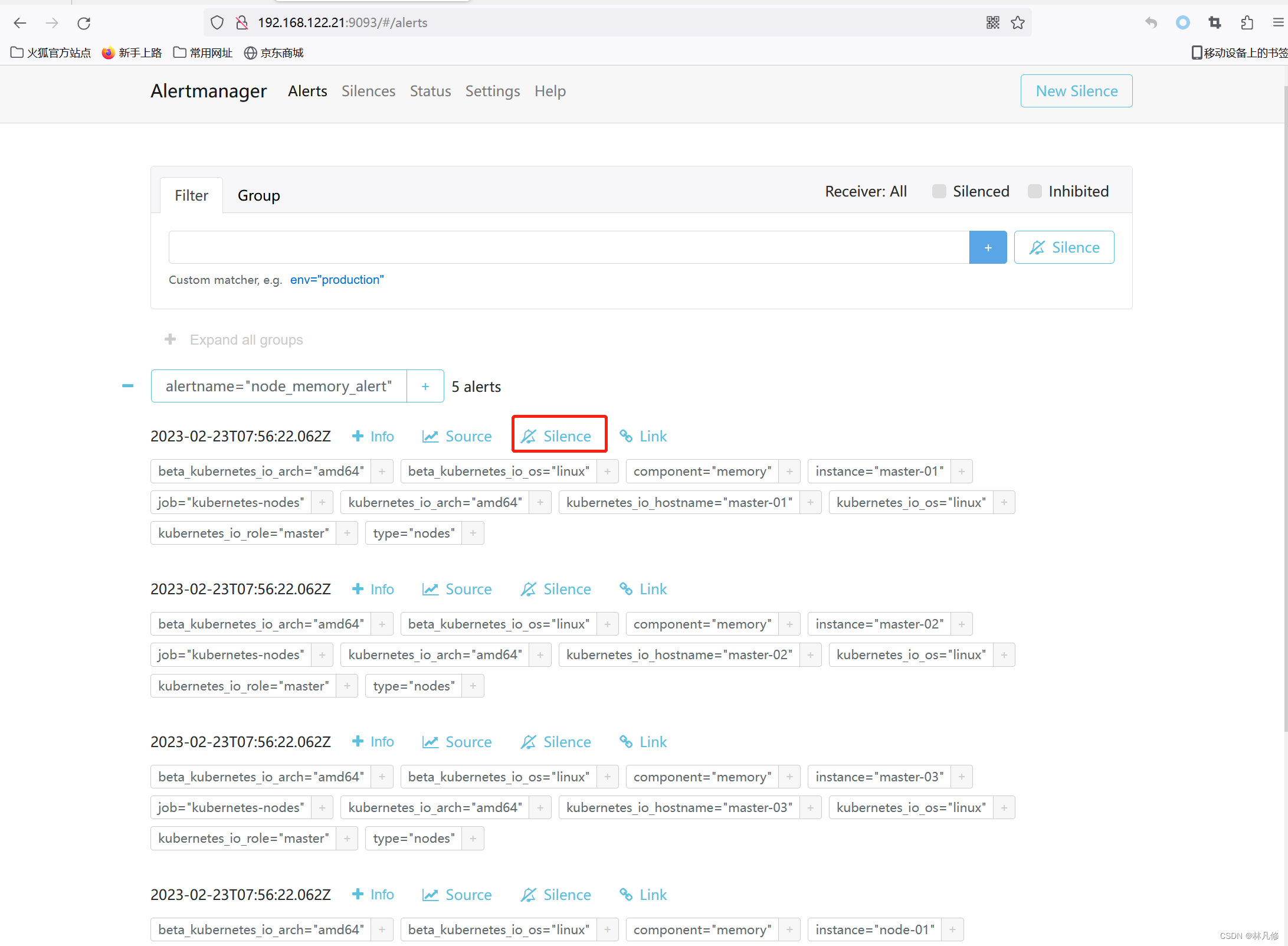
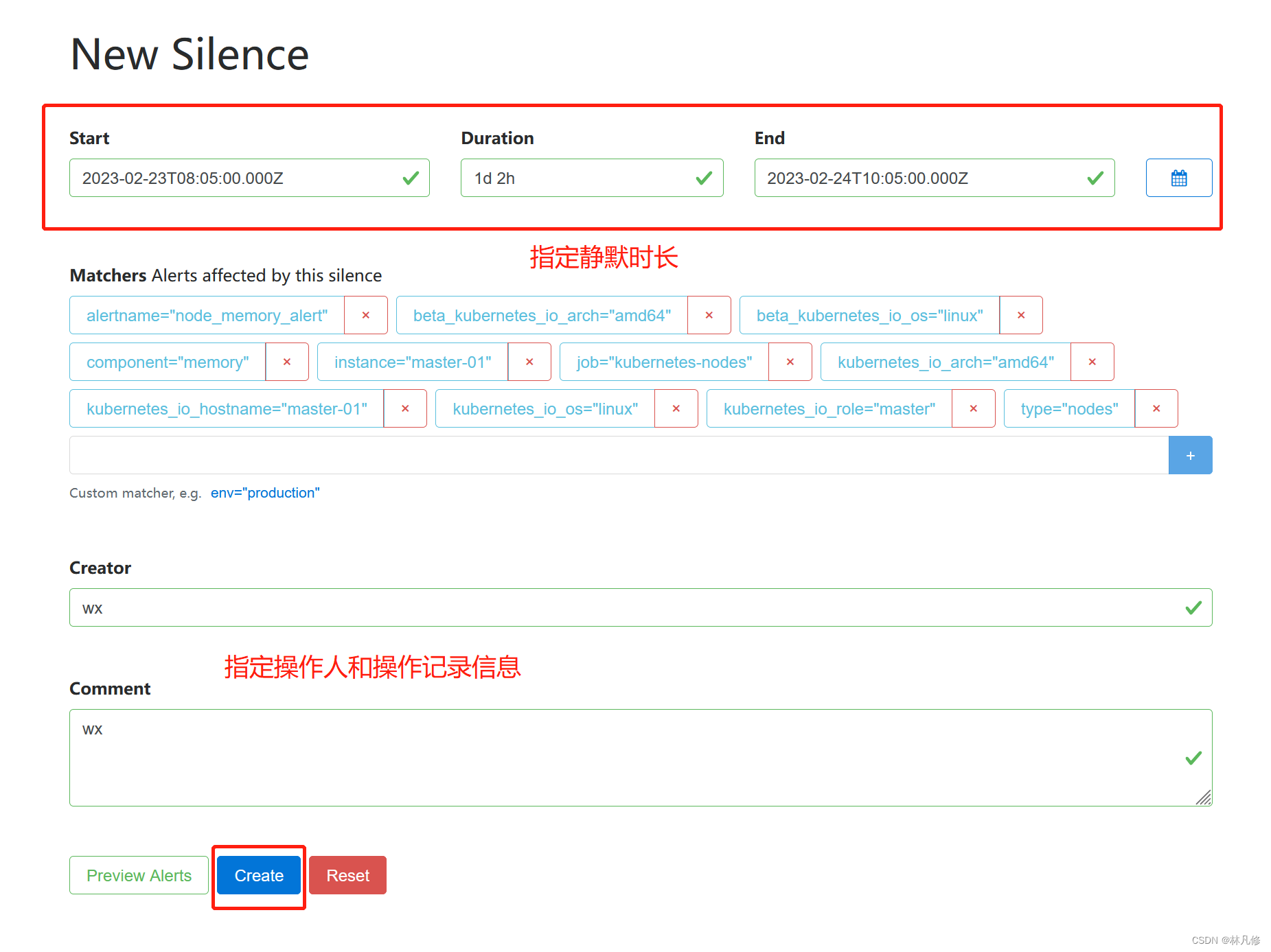
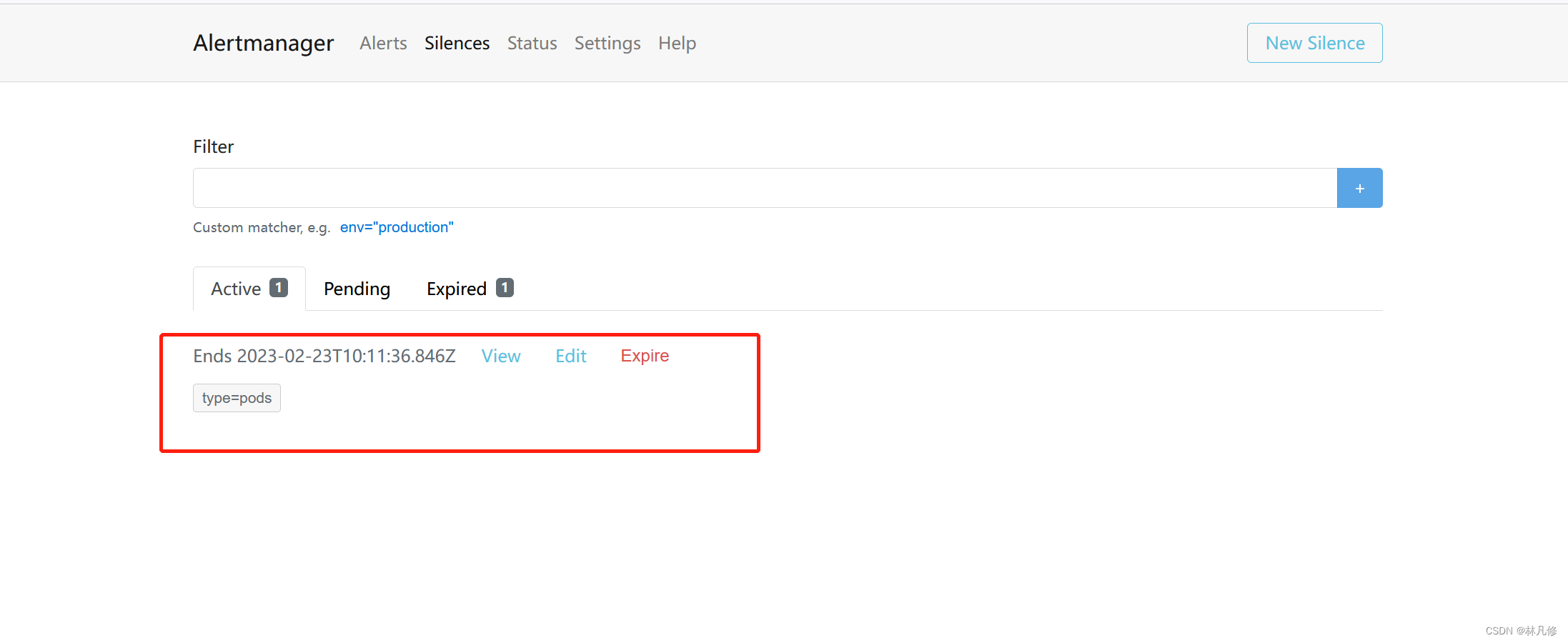
静默之后可以在Alertmanager界面查到对应的记录,如果需要提前结束静默可以可以点击Expire结束
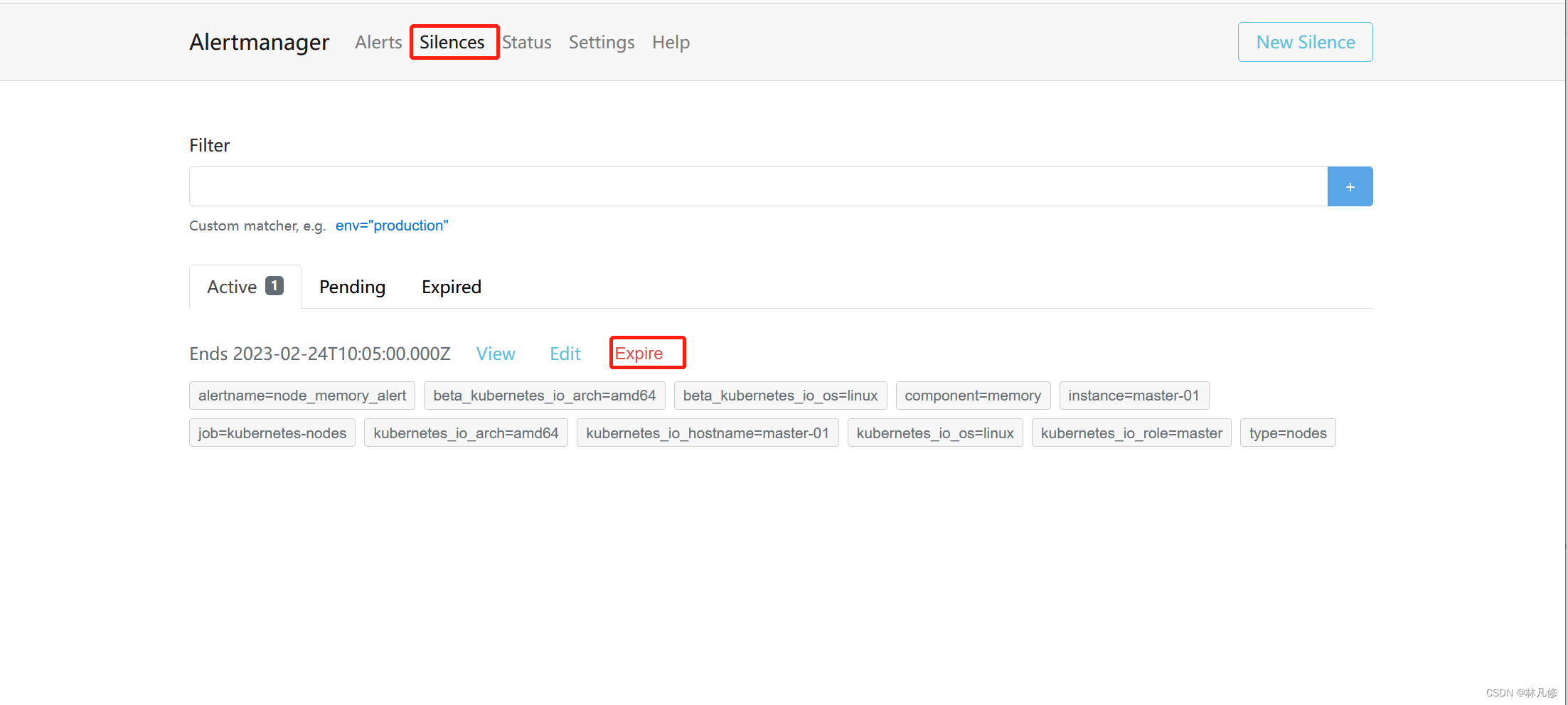
如果是针对还未触发过的告警进行静默,可以直接创建一个新的Silence记录,但需要手动添加标签来匹配告警