编者按:本文探讨了语言模型为何会比视觉模型的参数数量大得多的原因,并详细介绍了传统ViT训练方法在扩展时出现不稳定性的问题。
为此,本文介绍了如何改进架构以实现扩展,并讨论了实现模型最优状态的方法。同时,如何在扩展模型时不产生“偏见”,也是本文重点关注的问题。
很可能,我们很快就可以看到更大型的ViT(单独或作为多模态模型的组成部分)出现。
以下是译文,Enjoy!
作者 | Salvatore Raieli
编译 | 岳扬
近年来,我们看到Transformers的参数数量快速增加。但仔细观察会发现,主要是语言模型(LLMs)的参数在不断增加,现在已经高达惊人的540亿参数[1]。为什么这种情况没有出现在视觉模型呢?
对于文本模型(text models),增加数据集大小、使用可随时延展的架构(scalable architectures)和新的训练方法都可能使参数数量增长。如此不仅提高了模型在完成特定任务(如分类等)时的性能,而且随着参数数量的增加,我们还看到了 “涌现” 的出现。
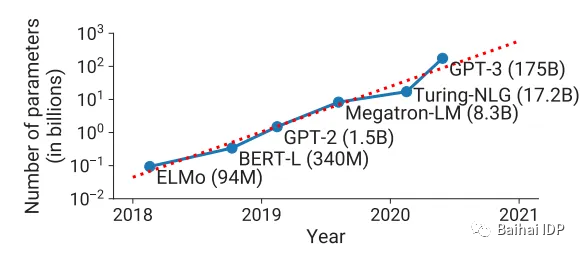
各阶段最先进NLP模型的参数大小随时间变化的趋势图。训练这些模型所需的浮点运算数量正以指数方式增长。 [2]
此外,由于大模型可作为迁移学习和微调的基础,因此人们对研发高性能模型的兴趣不断增长。虽已大模型成功应用于多种任务,但许多图像分析任务仍需要专门的模型。
Transformer的自注意力机制(self-attention) 其优势已经得到证明,成为2016年以来的首选模型架构。因此,一些团队已经训练了用于图像处理的Transformer模型(vision transformer, ViT)。目前,最强的ViT仅有150亿个参数。造成这一现象的原因是什么?
最近一项研究中,谷歌成功地训练了一个具有220亿参数的模型,并揭示了扩展ViT存在困难的原因。
内容提纲:1.解释了为什么传统ViT训练方法在扩展时出现不稳定性的原因。 2.介绍了如何改进架构以实现扩展,以及模型达到最优状态的方法。 3.同时,还探讨了如何在扩展模型时提高公平性(fairness)。
01 什么是vision transformers?

Image from Wikipedia (https://en.wikipedia.org/wiki/Vision_transformer)
Transformers本质上是不变的,但不能处理网格结构(grid-structured)数据(只能处理序列数据)。因此,为了使用Transformer处理图像,我们需要将图像转换成序列数据。 具体如何实现呢?
第一步是将图像转换成一系列片段(patches) ,称为图像块(image patches)。这些图像块基本上是我们需要的tokens(类似于经典Transformer中的words)。然后,这些图像被“压平”(flatten)并转换为低维度嵌入(这样可以保留信息但减少维度)。此外,像原始Transformer一样,我们使用位置编码(positional encoding),以便模型知道图像块在图像中的位置。
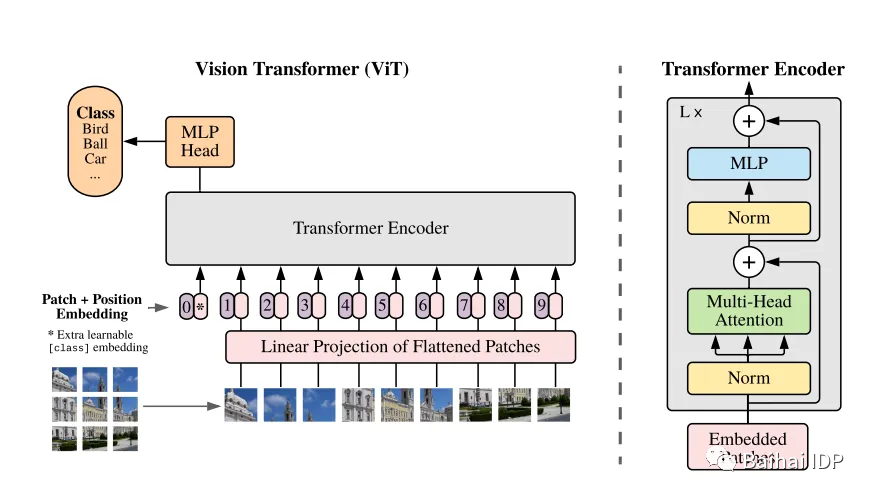
提出ViT的论文这样描述ViT (https://arxiv.org/pdf/2010.11929.pdf)
该模型随后将进行监督学习的训练(利用带有图像标签的大型数据集),并可以用于下游任务。
02 为什么难以扩展ViT,如何解决这个问题?
在引入ViTs之前,卷积网络(convolutional networks)一直是完成计算机视觉任务的标准。在《A ConvNet for the 2020s》[3]一文中,作者指出有效扩展模型规模这一问题仍未解决。
另一方面,我们仍尚未扩大ViTs的规模。因为在Transformers中,模型的规模扩大会导致出现无法预知的行为,这是一个严重的问题。
作者指出,超过8B参数后,训练过程中会出现不稳定性,在训练数千steps后出现了不收敛的训练损失。 这是由于attention logits中的极大值造成的,导致(几乎是独热编码(one-hot))的注意力权重接近于零熵(near-zero entropy)。为了解决这个问题,作者在点积计算(dot-product)之前给Queries和Keys添加了层归一化(layer-normalization)。
在下面这幅图中,展示了用这一方法如何改善训练效果。
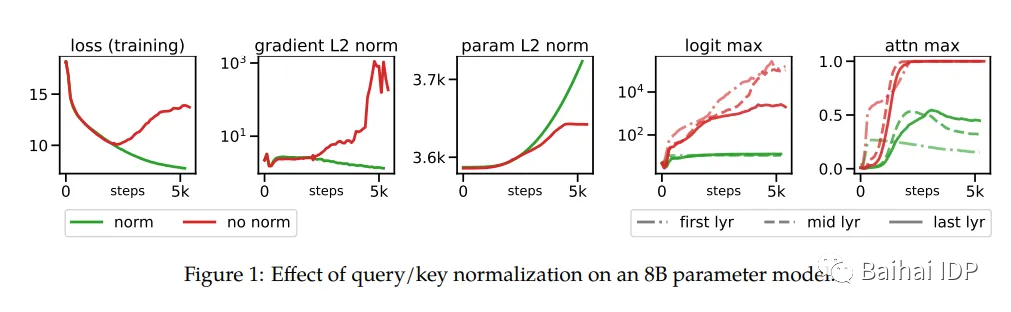
(source: https://arxiv.org/pdf/2302.05442.pdf)
第二种方法是通过修改架构。在传统的Transformer中,在经过自注意力(self-attention)之后输出的是一个多层感知机(multi-layer-perceptron, MLP[4])。相反,这里的自注意模块(self-attention blocks)与MLP并行处理,这种操作不会降低性能,甚至可以将训练速度提升15%(如谷歌的另一个大型模型PaLM所示,这个操作基本上是将矩阵乘法(matrix multiplications)合并为单个运算)。
此外,在注意力机制的投影操作中不再使用偏置项(bias term)(如此也不会降低性能但可以缩短训练时间)。
在图中展示了实施这些措施后的新注意力模块:
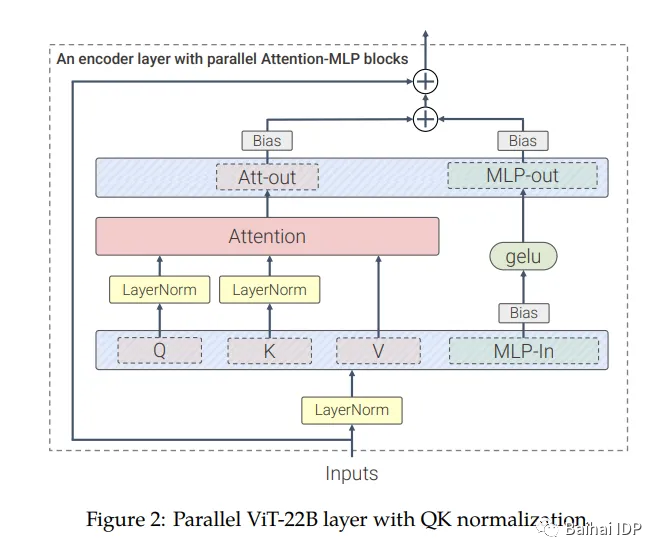
(source: https://arxiv.org/pdf/2302.05442.pdf)
下面这张表格对Google的模型(ViT-22)和之前最大的ViT模型——ViT-G和ViT-e进行比较。
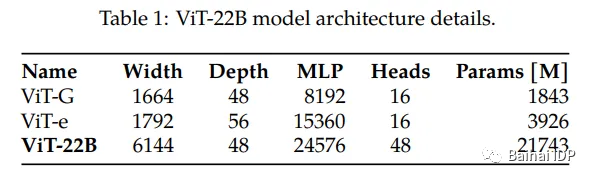
(source: https://arxiv.org/pdf/2302.05442.pdf)
针对训练过程也进行了优化。谷歌采用了JAX[5](其已成为谷歌的重点项目,相比之下,TensorFlow则不太受关注)。他们还使用了一些技巧(异步并行线性操作(asynchronous parallel linear operations)、模型参数切片(parameter sharding) )来确保使得模型针对TPU(张量处理单元)进行了优化。
作者使用了一个约40亿张图像组成的数据集,这些图像被半自动地划分为30,000个类别。有一点需要注意,在ViT中,图像被划分成多个部分(称为“patches”),然后与位置(位置编码)一起转换为序列(sequence)。每张图像(224 x 224)被划分成14 x 14个patches,因此一张图像最终由256个tokens表示。
03 对ViT进行扩展是否值得?
模型训练好后,在ImageNet数据集(一百万张图片和一千个类别)上进行了测试,主要是为了测试其分类能力。结果表明:相比其他模型,这个frozen model(即无需进行微调的模型)的性能相当。
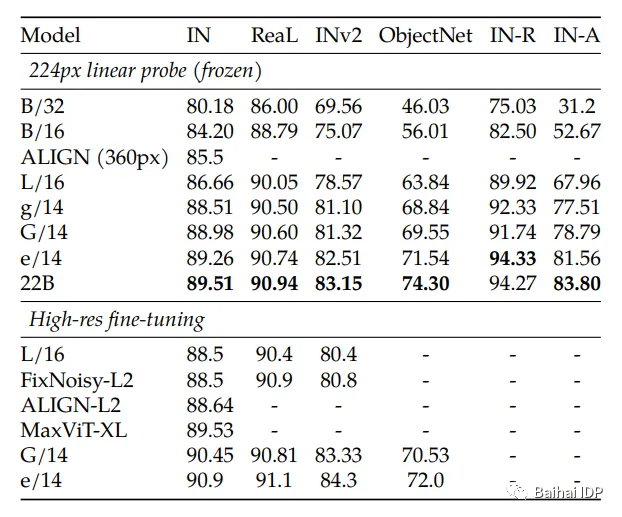
(source: https://arxiv.org/pdf/2302.05442.pdf)
此外,该模型已在另一个使用不同图像分辨率的数据集上进行了测试。当input size较小时,ViT-22B可以显著提高准确率。
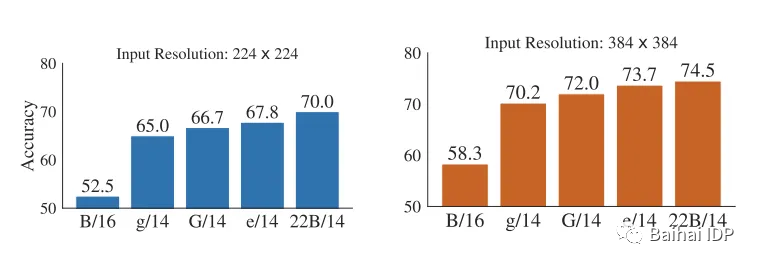
(source: https://arxiv.org/pdf/2302.05442.pdf)
另一方面,大模型最常见的用途之一就是进行迁移学习(transfer learning)。毕竟,人们通常使用小数据集对大模型进行微调,以完成不同于训练任务的任务。按照作者的说法:
密集预测(dense prediction)的迁移学习尤为重要,因为进行像素级标注可能代价高昂。在本节中,作者调查了ViT-22B模型(使用图像级分类目标(image-level classification objective)进行训练)在语义分割(semantic segmentation)和单目深度估计(monocular depth estimation)任务上获取几何和空间信息的质量。(来源:https://arxiv.org/pdf/2302.05442.pdf)
为测试该模型,作者使用了三个语义分割基准数据集(ADEK20k、Pascal Context、Pascal VOC)。此外,他们还测试了使用有限数据进行迁移学习时的情况。
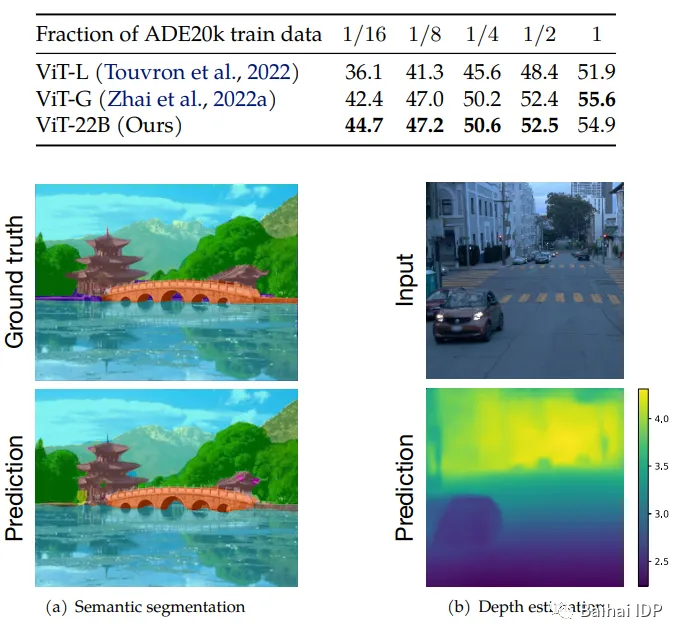
在ADE20k数据集上进行小样本(Fewshot)语义分割,仅利用训练集的一小部分。本研究还给出在验证集上进行语义分割的交并比(IoU)(source: https://arxiv.org/pdf/2302.05442.pdf)
ViT-22在数据量较少时表现最佳,这非常有用,因为通常获取图像及其分割掩码(segmentation mask)的代价非常昂贵,因此相较于其他模型,该模型需要的示例数量要更少。
此外,该模型在Waymo Open数据集上展示了卓越的单眼深度估计(monocular depth estimation)能力。
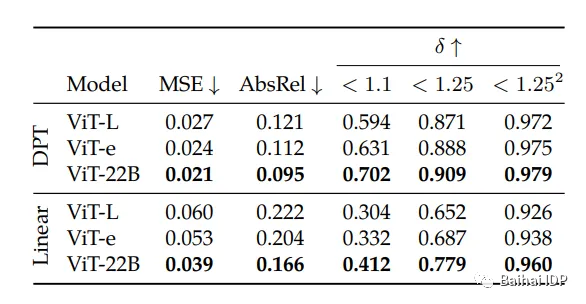
在进行Waymo Open数据集上使用不同解码器对冻结的ViT特征进行单目深度估计
(source: https://arxiv.org/pdf/2302.05442.pdf)
此外,通过重新设计模型(但保留预训练的 ViT-22),可以将其用于视频分类任务。这表明了利用该模型具有可塑性,可能能够进行多种其他的任务。
另外,作者还展示了微调该模型能够提高其性能的案例:
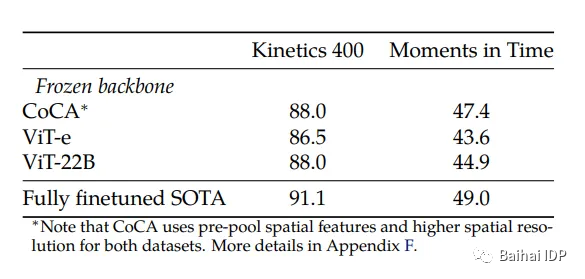
视频分类结果。我们通过冻结骨干网络,并训练一个小型Transformer来汇聚冻结的每一帧表征(representations.)来评估 ViT-22B 的表现。ViT-22B 胜过了之前包含 40 亿参数的最大视觉骨干网络 ViT-e。(source: https://arxiv.org/pdf/2302.05442.pdf)
04 这个模型的公平性如何?
AI模型容易受到偏见的影响。许多偏见存在于训练数据集中,导致模型放大、学习了虚假相关性和不一致误差(spurious correlation and error disparities) 。由于预训练模型会用于其他任务,错误的偏见会一直延续。
作者认为,对模型进行扩展可以减少这些偏见,并通过使用“群体均等(demographic parity ) ”(DP)作为公平性的度量标准来进行测试。
作者解释了他们的方法:
我们使用CelebA(Liu等人,2015)数据集,选取二元的性别(仅有男和女)作为敏感属性(sensitive attribute),而目标是“有吸引力(attractive)”或“微笑(smiling)”。需要注意这些实验仅用于验证技术要求,不应被认为其支持这类与视觉相关的任务。我们选择这些属性(性别)是因为这个模型展现了与性别相关的偏见,如图15所示。(source:https://arxiv.org/pdf/2302.05442.pdf)
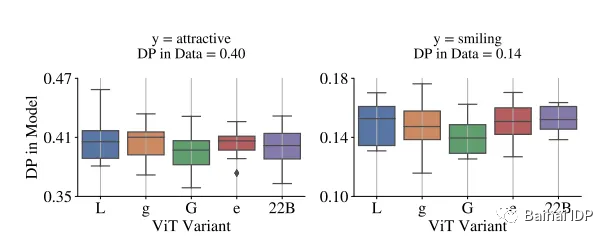
“在没有偏见减少的情况下,模型中的DP通常反映了数据中的DP。在这个图中,二元的性别是敏感属性,使用预训练特征在CelebA数据集上训练linear heads来预测其他属性。”
(source: https://arxiv.org/pdf/2302.05442.pdf)
如文献所述,扩大模型的规模提供了一个更有利的权衡,即“在任何指定偏差约束(bias constraint)下,性能随模型规模的增加而提升”。其次,所有子组(subgroups)受益于这种改进,而扩大模型的规模可以减少不同子组(subgroups)间性能上的差异。
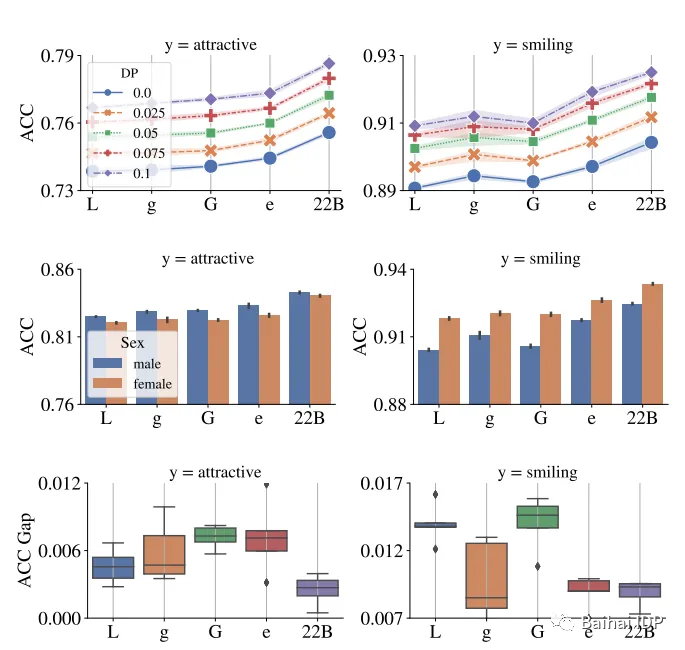
“顶部图:每个DP级别的ViT变体在消除偏见后的ACC。中部图:CelebA中的每个子组在去除偏见之前的ACC。底部图:y轴为女性和男性两个子组之间性能差异的绝对值。与较小的ViT架构相比,ViT-22B拥有更公平的表现。”
(source: https://arxiv.org/pdf/2302.05442.pdf)
05模型看到了什么?
计算机视觉模型主要关注纹理,而人类更多地依赖形状。
人类在看一个物体时,具有96%的形状偏好和4%的纹理偏好。相比之下,ViT-22B-384的形状偏好达到了87%,这是前所未有的,而纹理偏好仅为13%。这一结果非常有趣,因为大多数模型都具有20-30%的形状偏好(shape bias)和70-80%的纹理偏好(texture bias)。同时,这种偏好也是为什么通过改变图像的纹理,即使形状是可识别的,模型也会被欺骗,从而误判图像并错误地标记它的原因之一。
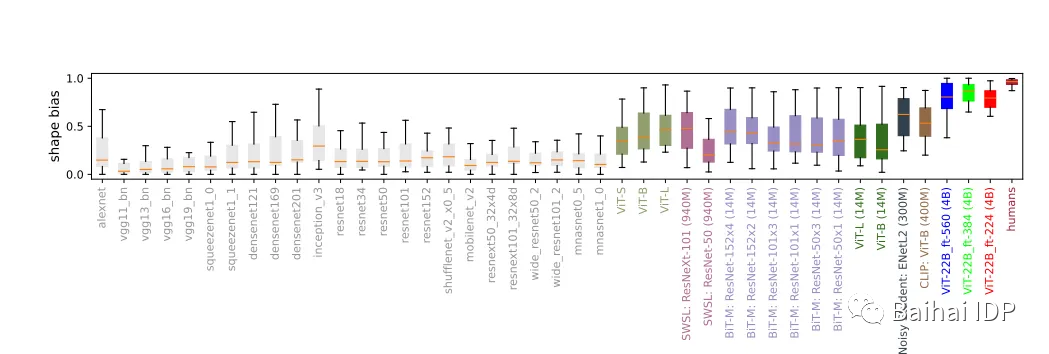
形状偏好:许多视觉模型具有较低的形状偏好和较高的纹理偏好,而在ImageNet上微调的ViT-22B(图中的红色、绿色、蓝色均使用4B张图像进行训练(如模型名称后方的括号所示)),具有迄今为止在机器学习模型中记录的最高形状偏好数值,使其更接近于人类的形状偏好。(source: https://arxiv.org/pdf/2302.05442.pdf)
此外,理解模型看到了什么的另一种方法是获得显著图(saliency maps)(基于梯度的特征归因方法) 。

模型冷却前后的显著性
(source:https://arxiv.org/pdf/2302.05442.pdf)
06 总结 Conclusions
Google发布了一款比之前的ViTs模型大5倍以上的模型。
我们推出了ViT-22B,这是目前最大的视觉Transformer模型,其参数量达到了220亿。通过对原始结构进行小但关键的修改,我们可以实现较好的硬件利用率(hardware utilization)和训练稳定性(training stability),从而得到在多个基准测试中领先的模型。(source:https://arxiv.org/pdf/2302.05442.pdf)
除了模型的规模和基准测试结果外,该模型还是更大型模型的基础。事实上,在此之前要成功扩展ViT模型是非常困难的, 因为在训练过程中会出现不稳定性。不过据作者说,通过修改架构可以解决这些问题。
大型模型可以作为不同任务的预训练脚手架(pre-trained scaffolds)(计算机视觉模型可以用于许多生活中的任务)。此外,还出现了一些意想不到的行为[6](这些行为在小型模型中不存在,并且不能通过模型规模来预测其规律)。此外,这些模型可以集成到多模态模型中(并可能影响其中的“涌现(emergent)”行为[7])。
此外,ViT-22B展示了模型扩展在公平性(fairness)方面已经得到了改善。该模型也更加具有鲁棒性(robust) ,更符合人类视觉(即不太依赖纹理,而更多地依赖形状) 。
很可能,我们很快将看到更大型的ViT(单独或作为多模态模型的组成部分)出现。
END
参考资料
1.https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
2.https://arxiv.org/abs/2104.04473
3.https://arxiv.org/abs/2201.03545
4.https://en.wikipedia.org/wiki/Multilayer_perceptron
5.https://www.businessinsider.com/facebook-pytorch-beat-google-tensorflow-jax-meta-ai-2022-6
6.https://arxiv.org/pdf/2206.07682.pdf
7.https://twitter.com/YiTayML/status/1625205983239880704?s=20&t=_W_AqpJHeJgJ_Af32Av5Jw
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接: