【论文介绍】
提出了一种混合神经网络,由内容流和边缘流组成。提出了一个空间变体RNNs。利用感知损失和对抗性损失对网络进行训练。
【题目】:Low-Light Image Enhancement via a Deep Hybrid Network
【DOI】:10.1109/TIP.2019.2910412
【会议】:2019-TIP
【作者】:Wenqi Ren, Sifei Liu, Lin Ma, Qianqian Xu, Xiangyu Xu, Xiaochun Cao, Junping Du, Ming-Hsuan Yang
【论文链接】:https://drive.google.com/file/d/1YAUtlVpTmr-sPXGoD6m6twdDD8CdwdOa/view
【代码链接】:未公开【提出问题】
该论文仅仅是从原问题出发——微光图像增强,并未对其它论文中出现的问题进行讨论。
【解决方案】
所提出的网络由两个不同的流组成,以在统一的网络中同时学习清晰图像的全局内容和显著结构。
更具体地,内容流通过编码器-解码器网络估计低光输入的全局内容。然而,内容流中的编码器往往会丢失一些结构细节。为了弥补这一点,提出了一种新颖的空间变化递归神经网络(RNNs)作为边缘流,在另一个自动编码器的指导下,对边缘细节进行建模。
【创新点】
- 提出了一种混合神经网络,其中内容流用于预测输入的场景信息,而边缘流用于边缘细节学习。
- 通过引入两个独立的权重图作为RNN的输入特征和隐藏状态,提出了一个空间变体RNNs。RNNs对图像的内部结构 (例如边缘) 进行建模,这在弱光图像增强中起着重要作用。
- 除了MSE损失,还通过感知和对抗性损失来训练混合网络。
【网络结构】
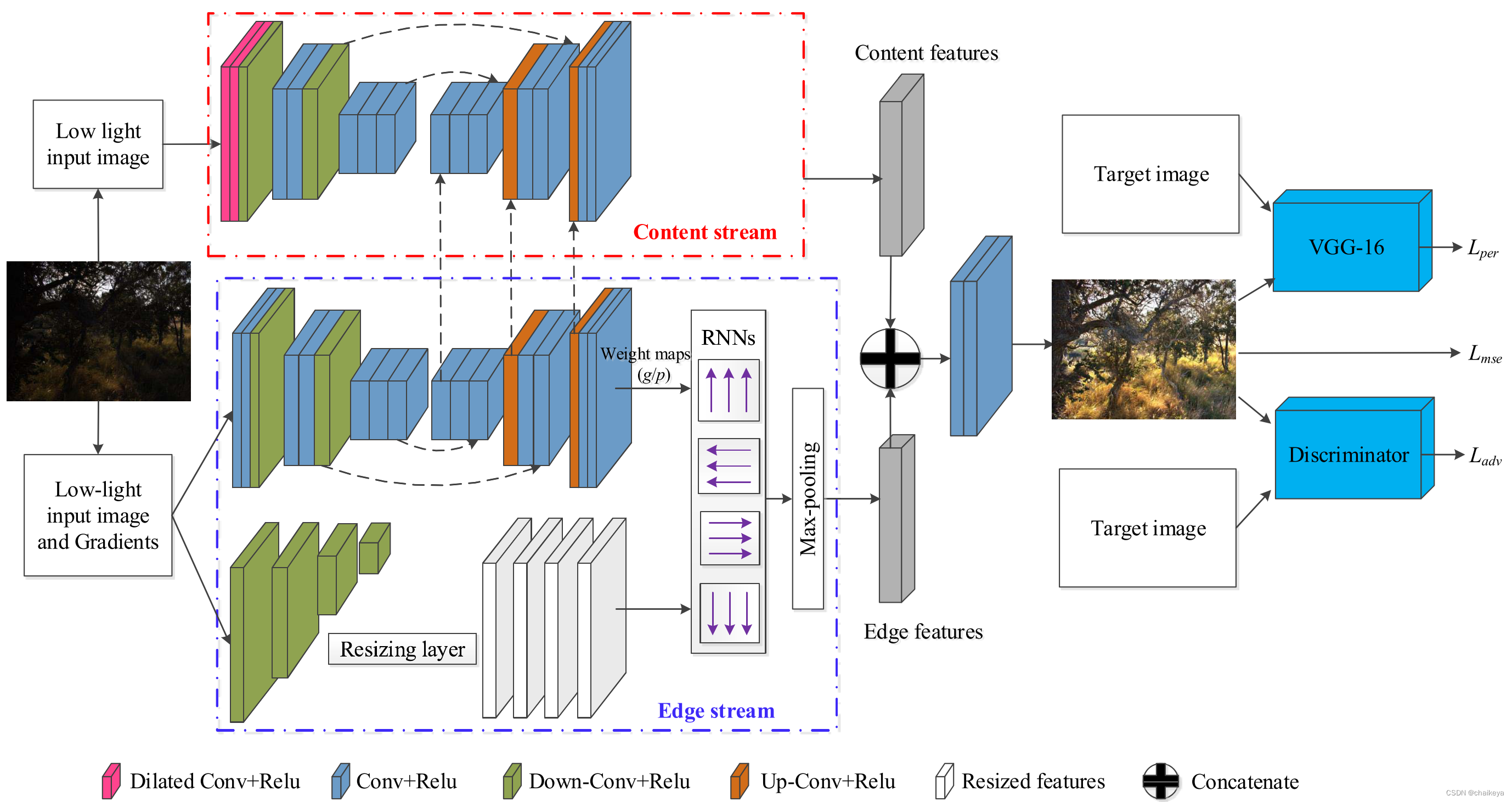
提出了一种新颖的混合网络结构来执行低光图像增强。使用内容流对RGB空间中的输入执行大部分推理(图2,顶部)。此外,显著边缘流(图2,底部)适用于RGB和梯度空间,这种流具有捕捉高频效应和保留显著结构的关键作用,还引入了一种新的空间变量RNN。最后,融合这两条路径以产生最终结果。
内容流 Content Stream
- 基于残差编码器-解码器体系结构构造内容分支,类似于U-Net。
- 编码器中的前两个卷积层改为Dilated Convolution,以扩大感受野。
- 将边缘流中的反卷积模块的功能串联在一起,以在上采样阶段获得更多细节。(因为特征表示具有相似的比例)
- 残差编码器-解码器网络具有三个卷积模块,每个模块由几个卷积层,remu和skip链路组成。
来自第一、第二和第三卷积的特征分别具有输入图像大小的1/2、1/4、1/8的大小。相应的解码器引入上采样操作以放大特征图。
边缘流 Edge Stream (空间变体RNN模型 RNNs)
RNN模型
引用具有空间可变的RNN的边缘流,以学习输入图像和和相应梯度为条件的权重图。例如,在 [26] 中提出了一个空间 RNN,它将先前的隐藏状态 h[k-1] 转移到当前状态 h[k],输入图像像素 x[k] 在位置 k。具体来说,一维(1D)中的空间循环关系可以建模为:
其中 p[k] 是平衡 x[k] 和 h[k] 之间的贡献的加权因子。
深度CNN依赖于使用图像内容来学习相应的权重图P。然而,EQ.2是归一化滤波器,其在某一指定频率处具有单位增益。例如,低通滤波器通常具有单位增益,这意味着其离散脉冲响应总和应为1。因此,该方法不能直接应用于低光图像增强任务,因为低光图像和日光图像的整体能量具有显著差异。
图4:由于空间 RNN [26] 等效于归一化滤波器,因此在给定低光输入 (a) 的情况下,RNN 的输出仍然是暗图像 (b)。 相比之下,本文改进的空间变体 RNN 学习显著边缘相关特征,如 (c) 所示。
[26] “Learning recursive filters for low-level vision via a hybrid neural network,”

空间变体RNNs模型
本文提出了一种边缘流(改进的空间变体RNNs模型)来弥补低光图像的结构信息损失:
![]()
h为所求结构,g、p为权重参数,x 为图像元素,k 表示位置;总体上来说,h[k] 上包含有图像在 k 位置 x[k] 的信息,还包含有上一个位置的边缘信息 h[k-1],这两者的所占程度受 g[k] 和 p[k] 控制;而g、p是未知的,或者说本应有人为给定,但是人为又难以给定,因此作者采用可学习的g、p来协助提取边缘信息。
edge stream部分是整篇论文的主要说明部分,也是其亮点之处:
- edge stream也包含一个Encode-Deconde结构,该结构旨在求解出g、h。
- 而下方的结构为下采样+conv和 resize 的操作,把input image分别下采样到1/2,1/4,1/8,然后进行一次卷积操作,然后再将1/2,1/4,1/8大小的map resize到和原来的大小一致。
- 然后分别从左->右,右->左,上->下,下->上四个方向根据上面提到的公式来得出各方向上的 h。
- 最后用每个k位置的四个方向的h[k]的最大值来作为k位置的边缘隐藏信息(即图中的Max-pooling)。
图3为从左->右的示意图:深度 CNN 生成指导 RNN 传播的权重图,

在混合网络学习内容和边缘相关特征之后,两个额外的卷积层,融合这些特征。
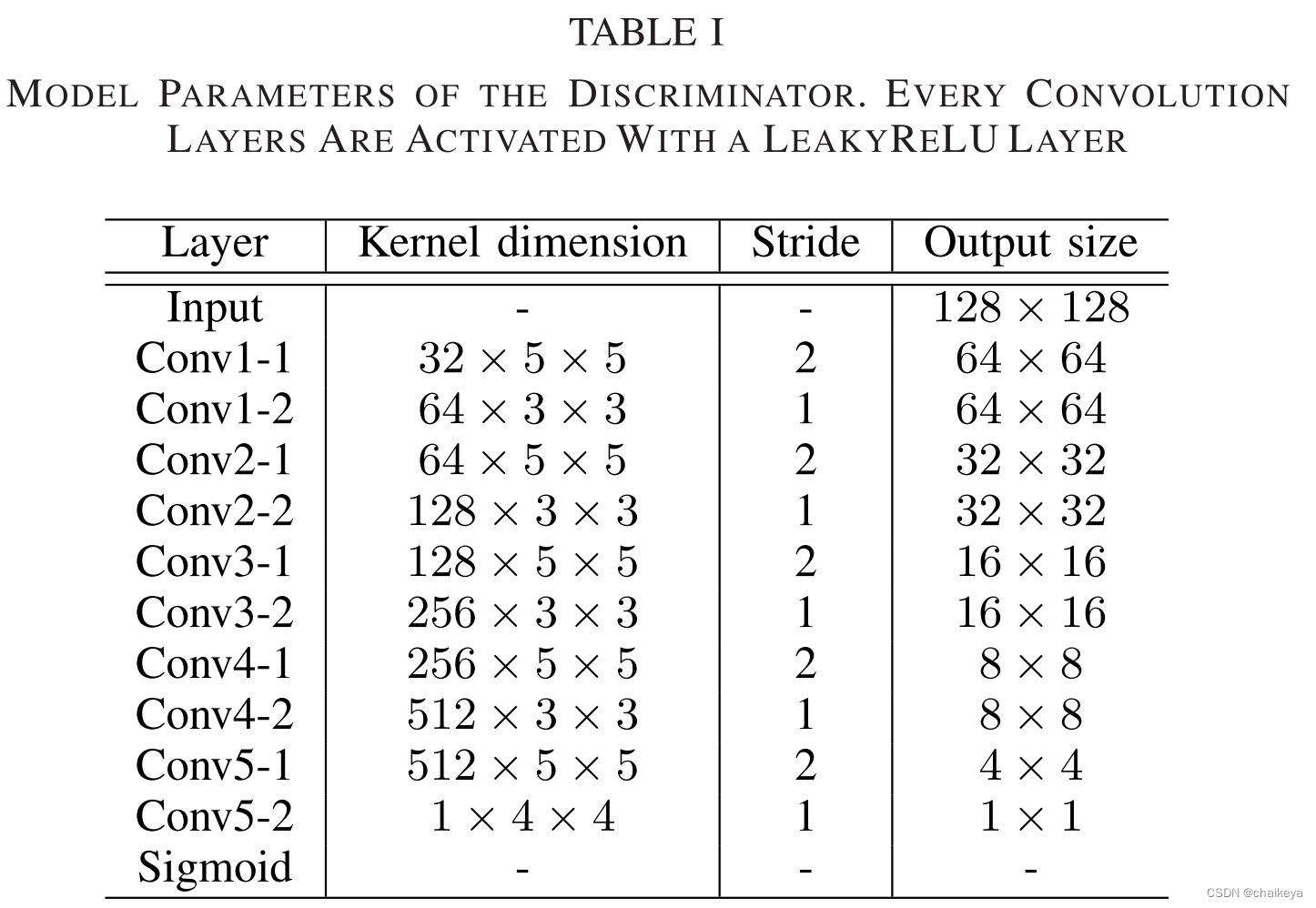
判别器 Discrimination
判别器 D 由十个卷积层组成,每个卷积层后跟一个 LeakyReLU 非线性。 第一、三、五、七、九卷积层的核大小为5×5,步长为2。其他卷积层的大小为3×3,步长为1。Sigmoidal激活函数应用于最后一个卷积层的输出,并产生输入图像与ground truth相同的概率。
【损失函数】
![]()
均方误差损失 MSE Loss
该损失度量增强后的图像 I 与 groud-truth 之间的内容差异,使用输出图像与目标图像之间的欧几里德距离,表达式如下:

其中N表示每个进程中的图像数量。
感知损失 Perceptual Loss
反映 groud-truth 与生成的图 I 在一个预训练的VGG-16下提取的特征的差距:

其中 ϕj 表示由VGG16网络通过第 j 次卷积得到的特征图。
对抗损失 Adversarial Loss
引入了一个鉴别器与原网络构成一个对抗网络:
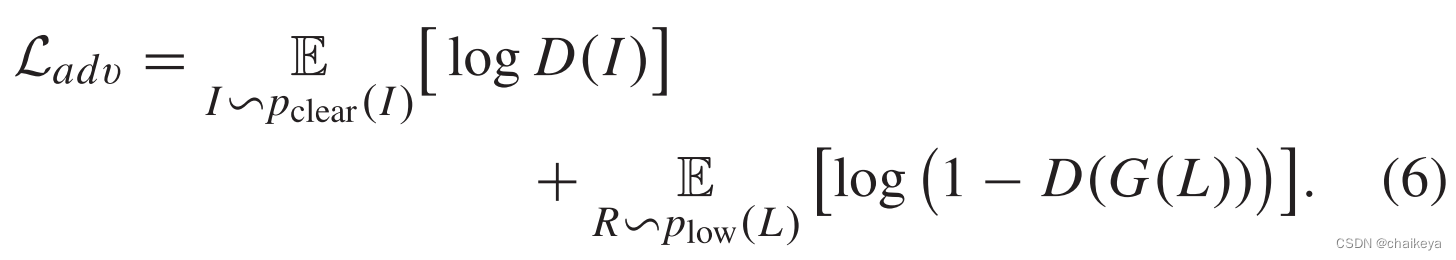
【数据集】
从Adobe Fivek数据集[41]中仔细选择了336个符合我们要求的输入和输出对。所选照片涵盖了广泛的场景和主题。我们在图5中展示了一些示例。由于训练图像的数量相对较少,我们通过使用旋转、翻转、裁剪、噪声和小程度的伽玛校正(即γ∈(2,4))来进一步增强数据集,以进一步加深图像。
【实验结果】
定量结果
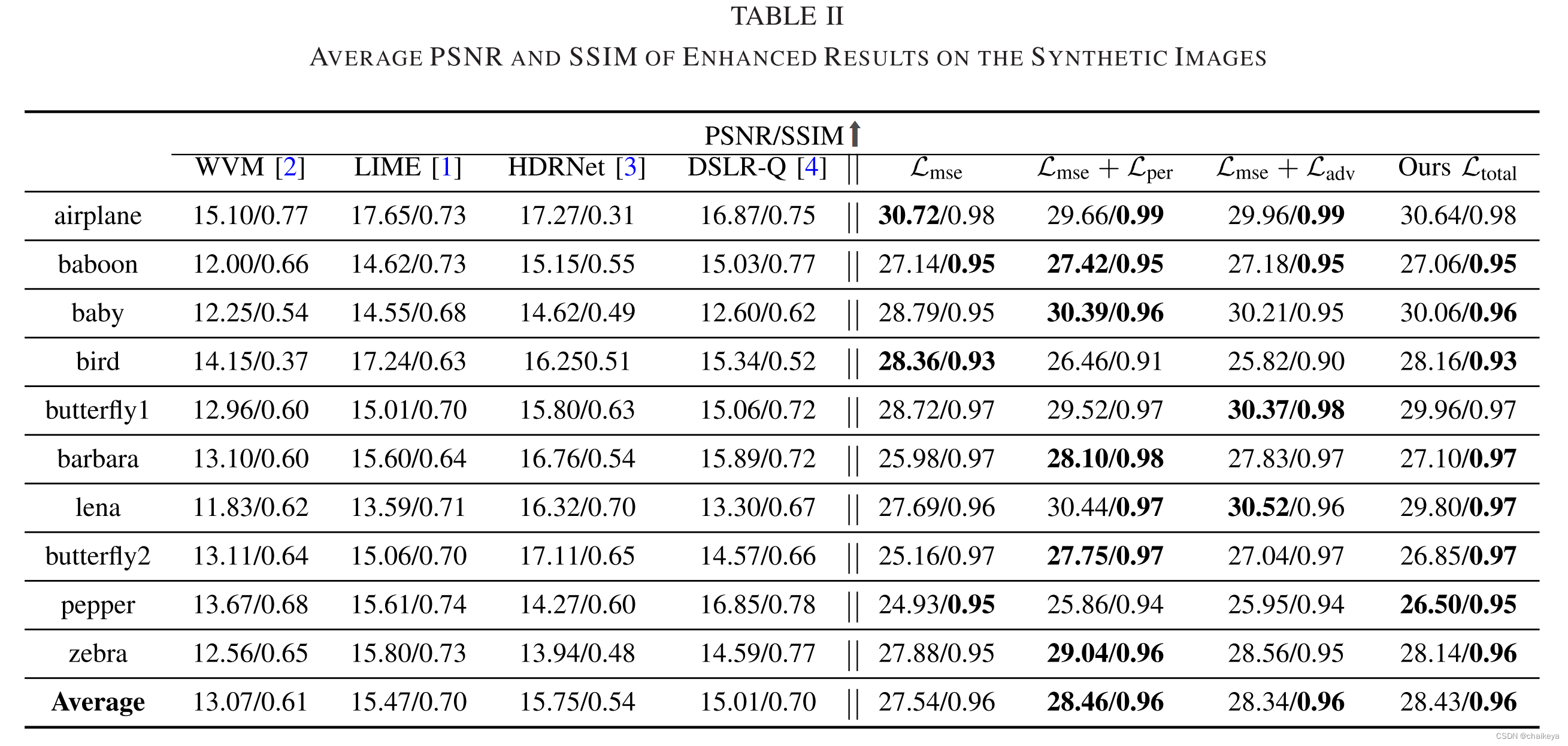
10个定量评估的测试图像

基本增强效果:粗体为较好结果,最后一行是平均值,本文提出的方法比以往方法效果好。
颜色恒定性:除了增强低光图像外,即使我们最小化 RGB 空间,所提出的模型也能恢复真实的颜色。
图 8 提供了一个示例。有的偏暗有的偏亮,而本文的增强图像更类似于ground truth。
如表 III 所示,为了评估不同算法的性能,在 10 个测试图像上计算了ground truth和 HSV 域中恢复结果之间的 MSE 误差。( H 和 S 通道仅在 0 到 1 的范围内表示,而 V 通道的强度在 0 到 255 之间)因此,V 通道 (MSEv) 中的误差主导 HSV (MSEhsv) 颜色空间中的误差。

DPED数据集上的泛化效果:
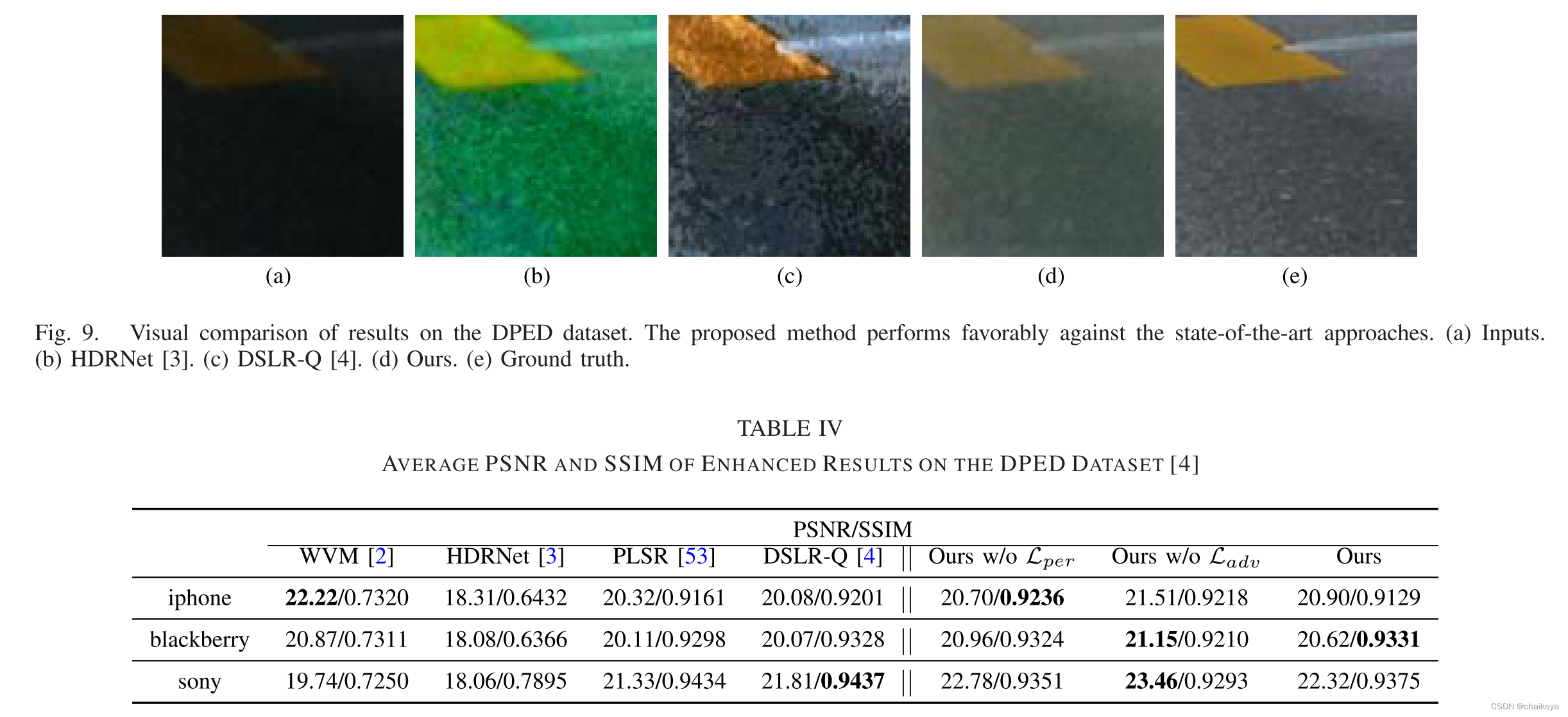
图9:HDRNet [3] 的结果往往会有一些颜色失真,而 DSLR-Q [4] 的结果仍然有一些暗区。
表4:增加感知损失往往会增加 PSNR,而对抗性损失会提高 SSIM 值,有助于改善视觉效果。
定性评估
图10使用五个具有挑战性的真实图像与其他方法进行对比。WVM [2] 和DSLR-Q [4] 恢复的亮度仍然有些暗淡,并且无法有效地提取,如图10(b) 和 (d) 所示的黑暗区域中的信息。HDRNet [3] 的方法可以增强 (c) 中的图像细节并增强图像可见性,但是这种方法倾向于过度增强生成的图像中的颜色,并导致某些颜色失真,例如,在 (c) 的第一行中,水的颜色从灰色变为绿色。相反,本文所提出的算法在黑暗区域中恢复的结果在视觉上更加令人愉悦,而没有颜色失真或伪影。

运行时间
我们为在同一台机器上运行的所有方法选择40个图像。表V总结了一些代表性方法在不同图像分辨率上的平均运行时间。WVM[2]和LIME[1]运行在英特尔酷睿i7 CPU。HDRNet[3]和DSLR-Q[4]在NVIDIA K80 GPU上运行。此外,我们在CPU和GPU上运行我们提出的模型,以进行公平的比较。如表V所示,所提出的方法在运行时间方面优于其他最先进的方法。

怎么能睁眼说瞎话呢,明明本文的时间比较长,他还说自己好?