构建模型的步骤:
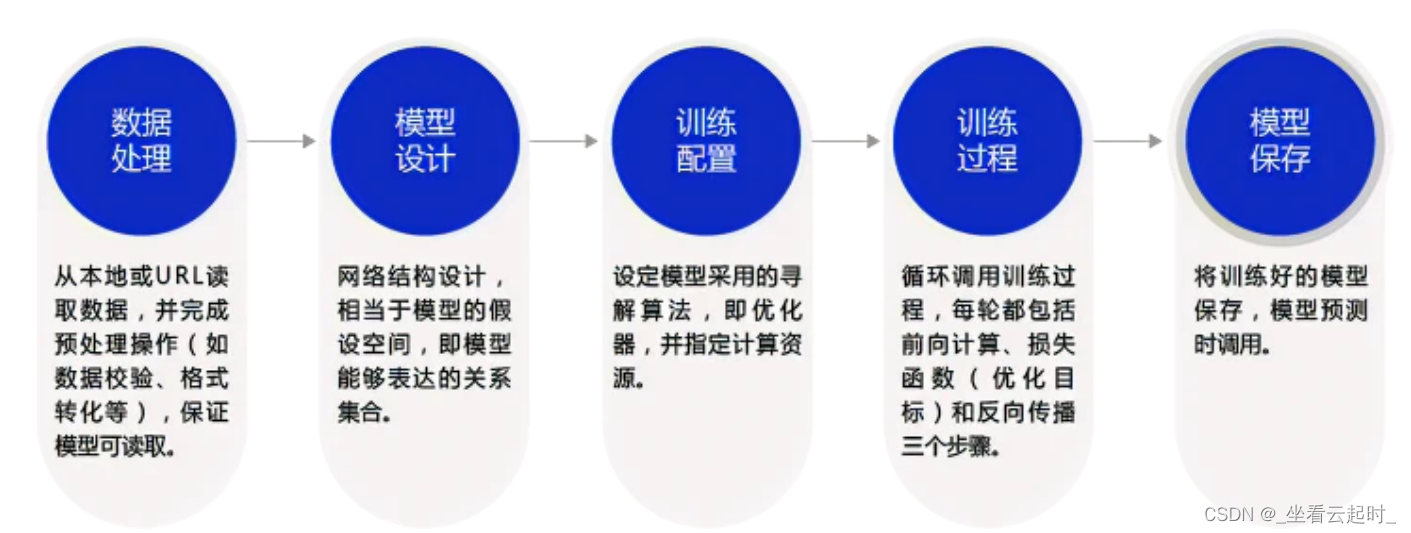
首先要进行数据处理,抽取简历文件中的数据。
首先要准备数据集,大赛提供的数据集中多为word文档,都为.docx格式,
docx文件是基于 XML 的,可以包含文本,对象,样式,格式和图像,所有文件都存储为单独的文件,最终压缩在单个 ZIP 压缩的docx文件中。比如在以zip格式打开一个.docx文件:
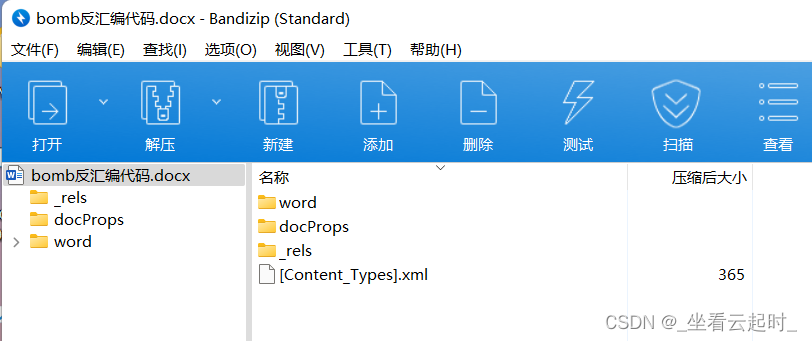
里面有几个文件夹,打开之后有xml格式的文件:

打开document.xml文件:
文档的正文,是以xml格式表示的。
提取word文档信息
项目选择的是用BeautifulSoup提取Word文档信息,源代码:
from zipfile import ZipFile
from bs4 import BeautifulSoup
from pprint import pprint
from paddlenlp import Taskflow
# 定义实体关系抽取的schema
schema = ['姓名', '出生日期', '电话']
ie = Taskflow('information_extraction', schema=schema)
document = ZipFile('D:\\DeskTop\\dataset_CV\\dataset_CV\\CV\\3.docx')
xml = document.read("word/document.xml")
wordObj = BeautifulSoup(xml.decode("utf-8"))
texts = wordObj.findAll("w:t")
paragraphs_text = ""
for text in texts:
# print(text.text)
paragraphs_text += text.text + "\n"
# print(paragraphs_text)
pprint(ie(paragraphs_text)Taskflow是一个信息抽取框架,提供文本及文档的通用信息抽取、评价观点抽取等能力,可抽取多种类型的信息,包括但不限于命名实体识别(如人名、地名、机构名等)、关系(如电影的导演、歌曲的发行时间等)、事件(如某路口发生车祸、某地发生地震等)、以及评价维度、观点词、情感倾向等信息。用户可以使用自然语言自定义抽取目标,无需训练即可统一抽取输入文本或文档中的对应信息。
定义了一个包含三个字段的schema变量,分别是姓名、出生日期和电话号码。然后,利用这个schema变量创建了一个信息抽取任务流程对象ie。
使用python标准库中的ZipFile模块打开一个Word文档,并读取其中的"word/document.xml"文件。然后,利用BeautifulSoup库将XML格式的文本解析为一个对象wordObj。接着,通过查找wordObj中所有的"w:t"标签,将文档中的所有文本内容读取到一个字符串变量paragraphs_text中。
参考文献:
[1]