前言
LightGBM建模~
一、Python调参
(1)建模前的准备
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
(2)LightGBM的调参策略
先复习一下参数,需要调整的参数有:
① learning_rate:一般先设定为0.1,最后再作调整,合适候选值为:[0.01, 0.015, 0.025, 0.05, 0.1];
② max_depth:树的最大深度,默认值为-1,表示不做限制,合理的设置可以防止过拟合;
③ num_leaves:叶子的个数,默认值为31,此参数的数值应该小于2^max_depth;
④ min_data_in_leaf /min_child_samples:设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合,默认值20;
⑤ min_split_gain:默认值为0,设置的值越大,模型就越保守,推荐的候选值为:[0, 0.05 ~ 0.1, 0.3, 0.5, 0.7, 0.9, 1];
⑥ subsample:选择小于1的比例可以防止过拟合,但会增加样本拟合的偏差,推荐的候选值为:[0.6, 0.7, 0.8, 0.9, 1];
⑦ colsample_bytree:特征随机采样的比例,默认值为1,推荐的候选值为:[0.6, 0.7, 0.8, 0.9, 1];
⑧ reg_alpha:推荐的候选值为:[0, 0.01~0.1, 1];
⑨ reg_lambda:推荐的候选值为:[0, 0.1, 0.5, 1];
参考大佬的调参策略:
① learning_rate设置为0.1;
② 调参:max_depth, num_leaves, min_data_in_leaf, min_split_gain, subsample, colsample_bytree;
③ 调参:reg_lambda , reg_alpha;
④ 降低学习率,继续调整参数,学习率合适候选值为:[0.01, 0.015, 0.025, 0.05, 0.1];
(3)LightGBM调参演示
(A)先默认参数走一波:
import lightgbm as lgb
classifier = lgb.LGBMClassifier(boosting='gbdt', objective='binary', metric='auc')
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
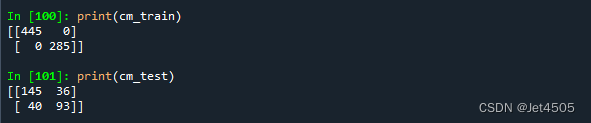
print(cm_train)
print(cm_test)
看结果,妥妥的继续过拟合:
(B)调整max_depth, num_leaves, min_data_in_leaf, min_split_gain, subsample, colsample_bytree:
(a)learning_rate设置为0.1,然后先来max_depth, num_leaves和min_data_in_leaf:
param_grid=[{
'max_depth': [5, 10, 15, 20, 25, 30, 35],
'num_leaves': range(5, 100, 5),
'min_data_in_leaf': range(5,200,10),
},
]
boost = lgb.LGBMClassifier(boosting='gbdt', objective='binary', metric='auc', learning_rate=0.1)
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
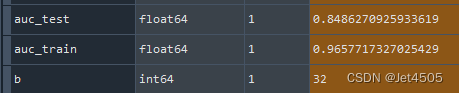
print(cm_train)
print(cm_test)
最优参数:max_depth=10, min_data_in_leaf=95, num_leaves=10
看下性能,有点意思:

(b)再来min_split_gain, subsample和colsample_bytree:
param_grid=[{
'min_split_gain': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
'subsample': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
'colsample_bytree': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
},
]
boost = lgb.LGBMClassifier(boosting='gbdt', objective='binary', metric='auc', learning_rate=0.1, max_depth=10,min_data_in_leaf=95, num_leaves=10)
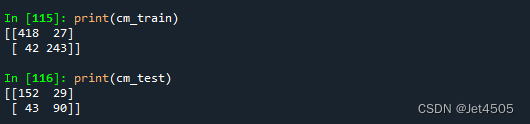
最优参数:colsample_bytree=0.8, min_split_gain=0.6, subsample=0.1。
看下性能,差不多:

(C)确定lambda_l1和lambda_l2:
param_grid=[{
'reg_alpha': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
'reg_lambda': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0],
},
]
boost = lgb.LGBMClassifier(boosting='gbdt', objective='binary', metric='auc', learning_rate=0.1, max_depth=10,min_data_in_leaf=95, num_leaves=10, colsample_bytree=0.8, min_split_gain=0.6, subsample=0.1)
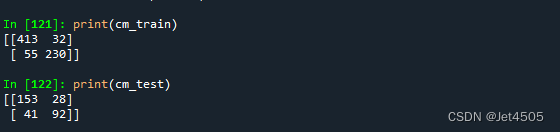
最优参数:reg_alpha=0.8, reg_lambda=0.3。
看下性能:
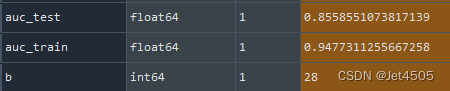
(D)确定learning_rate:
param_grid=[{
'learning_rate': [0.01, 0.015, 0.025, 0.05, 0.075, 0.1, 0.2, 0.3],
},
]
boost = lgb.LGBMClassifier(boosting='gbdt', objective='binary', metric='auc', max_depth=10,min_data_in_leaf=95, num_leaves=10,
colsample_bytree=0.8, min_split_gain=0.6, subsample=0.1, reg_alpha=0.8, reg_lambda=0.3)
没变,还是0.1那就不管了。
这回我就不做综合微调了哈,而且还有几个参数我也没有调(比如说eature_fraction、bagging_fraction、bagging_freq),大家可自行玩弄,现在直接看具体的性能:
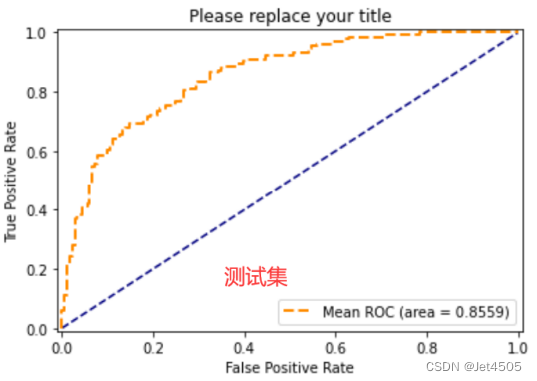
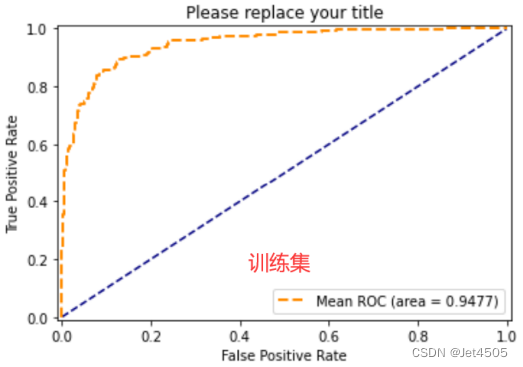
第二步:SPSSPRO调参(自己琢磨了哈)
总结
这LightGBM还是挺复杂的,我只是介绍一些皮毛而已,具体可以自己根据官方文档或者网络资源进行深入学习。