开始填坑之旅。
首先,之前提过,random_state这个参数,它的功能是确保每次随机抽样所得到的数据都是一样的,有利于数据的复现。比如,我们这十个ML模型,用的参数都是random_state=666,这样作比较才有可比性,因为训练集和验证集都是一样的,大家的起跑线一样,公平竞争。
我之前也也给大家示范过,random_state选取不同的数值,模型的性能是有差别的,这也可以解释,毕竟我们演示的数据集样本量也就1000多,属于小样本,而且数据内部肯定存在异质性,因此,不同抽样的数据所得出来的模型性能,自然不同。
举个不太恰当的例子:东部沿海的教育资源比西部地区要好,同一个人,受教育的地区不同,其学习成绩大概率也会不同。但是呢,从另一个角度来说,所谓是金子总会发光,考察一个人厉不厉害,是不是得把他放到不同地区考察一下,综合判断,毕竟有些人顺风英雄,逆风狗熊,有些人反过来。
所以,我觉得要综合判断一个模型好不好,一次随机抽样是不行的,得多次抽样建模,看看整体的性能如何才行(特别是对于这种小训练集)。
所以我的思路是,随机抽取训练集和验证集2000次(随你),然后构建2000个ML模型(譬如2000个朴素贝叶斯),得出2000批性能参数。那怎么实现呢,还不就是random_state,下面上代码,以朴素贝叶斯为例:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
empty = np.array([[0],[0],[0],[0],[0],[0],[0]])
n=1
while n < 2001:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = n)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_updatapred = classifier.predict(X_train)
from sklearn.metrics import confusion_matrix, roc_auc_score
cm = confusion_matrix(y_test, y_pred)
cm_updata = confusion_matrix(y_train, y_updatapred)
auc = roc_auc_score(y_test, y_pred)
auc_updata = roc_auc_score(y_train, y_updatapred)
a = cm[0,0]
b = cm[0,1]
c = cm[1,0]
d = cm[1,1]
sen = d/(d+c)
sep = a/(a+b)
a_updata = cm_updata[0,0]
b_updata = cm_updata[0,1]
c_updata = cm_updata[1,0]
d_updata = cm_updata[1,1]
sen_updata = d_updata/(d_updata + c_updata)
sep_updata = a_updata/(a_updata + b_updata)
first = np.array([[n],[sen],[sep],[auc],[sen_updata],[sep_updata],[auc_updata]])
second = np.hstack((empty,first))
empty = second
n = n + 1
print(n)
final_par = np.delete(second,0,axis=1)
print (final_par)
final_parT = final_par.T
np.savetxt('jet_NB_par',final_parT,delimiter=',')简单解说:
1.其实就是一个循环语句,while n < 2001,2000次就是2001,你要是想运行10000次,就改成10001;
2.运行以后呢,可以看到模型在迭代,显示的是运行到第几个模型了:

3. 然后,2000次模型参数的结果,存在一个叫final_parT的表格中,可以点击打开看看:


一共七列,分别表示,验证集或者测试集的灵敏度、特异度、AUC,训练集的灵敏度、特异度、AUC。
4. 用代码np.savetxt('jet_NB_par',final_parT,delimiter=',')输出成excel查看,输出地址就是你的工作路径,E:\ML\100-Days-Of-ML-Code-master\datasets(比如我的)
5. 打开工作路径,可以发现jet_NB_par这个文件是白色的:
我们只需要给他加一个后缀,“.csv”就可以打开了:

6. 打开文件,是科学计数法,调整一下格式,添加一个列名:

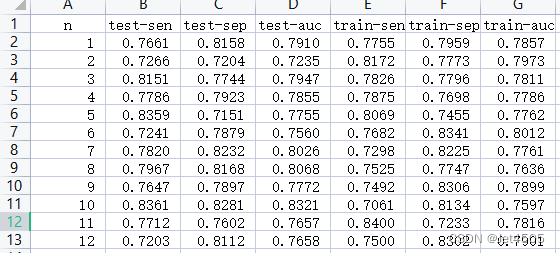
7. 然后可以操作了,比如test-sen排个序,看看最好的有多好;比如看看2000次的平均值和标准差:AUC平均值0.77-0.78左右。剩下的自己玩了,不说那么多了,发挥你们的妄想空间。