目录
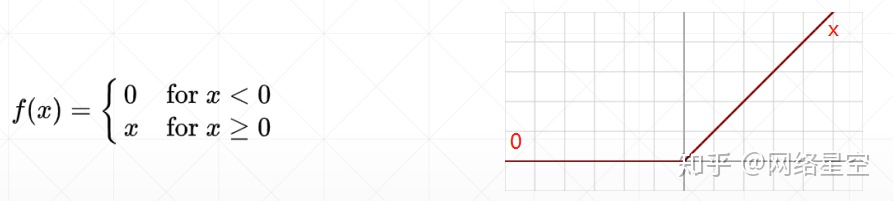
3)relu(Rectified Liner Unit,调整的线性流单元)
* 被大量的实验证明,relu函数很适合做deep learning。
* 注意w.norm(),w.grad(),w.grad().norm()的区别:
一、梯度
1、导数、偏微分、梯度的区别:
1)导数:是标量,是在某一方向上变化的效率
2)偏微分,partial derivate:特殊的导数,也是标量。函数的自变量的方向,函数的自变量越多,偏微分就越多。

3)梯度,gradient:把所有的偏微分集合成向量,是向量。

梯度向量的长度代表函数在当前点变化的速率。
2、梯度的作用:
1)作用通过梯度来找到函数的极小值
2)如何找到极小值,通过以下公式:

学习步长就是学习率。
不断更新自变量,当偏导(梯度)趋近于0的时候,函数值也就趋近于极小值。
3)举例:

3、梯度的优化方法:

不同的优化方法具有不同的效率、准确率。有的快,有的准确率高。主要通过以下几个方向优化:
1)初始化数据(initialization)
初始状态的不同,对结果的影响可能有很大区别
如果不清楚的话,就使用目前主流的初始化方法。
2)学习率(learning rate)
过大会导致数据不收敛,过小会导致计算量的增加。
3)动量(monument)
给数据一个惯性,当惯性达到一定程度后,可以减少数据陷入局部极小值的情况。
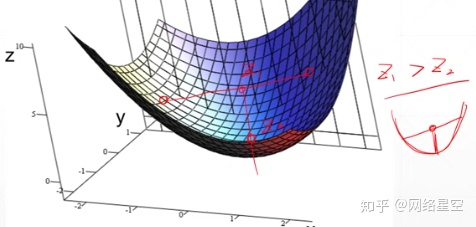
4、凸函数(convex function):
向一个碗一样,两点中点处,均值大于实际值,如下图所示
5、局部极小值(local minima):

局部极小值较多的情况的解决办法:

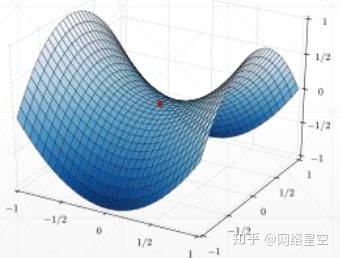
6、鞍点(saddle point):
一个点,在某一方向上是极小值,在另一方向上又是极大值。如下图中红点所示:
二、激活函数
1、激活函数的点
1)作用
当函数值达到某一阈值后,激活函数将函数值设置为特定值(根据激活函数公式而定),从而达到激活的目的

2)激活函数均不可导
2、常用激活函数
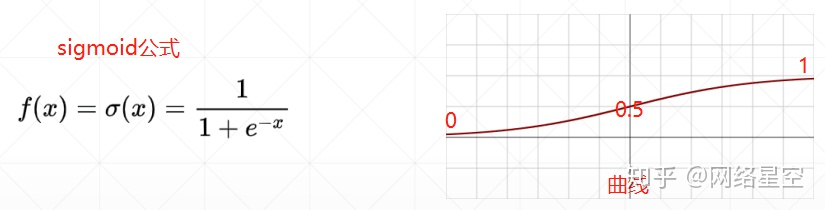
1)sigmoid
* sigmoid导数(derivative):

* sigmoid用处:
a)因为sigmoid输出的值是在0~1之间,所以适用于概率问题;也适用于图像的RGB问题,因为RGB值是0~255之间
b)sigmoid的缺点:因为sigmoid函数在处于+∞和-∞时候,导数趋近于0,会使得数据处于更新非常缓慢(长时间loss保持不变的情况),即:梯度弥散问题。
* sigmoid函数的pytorch实现

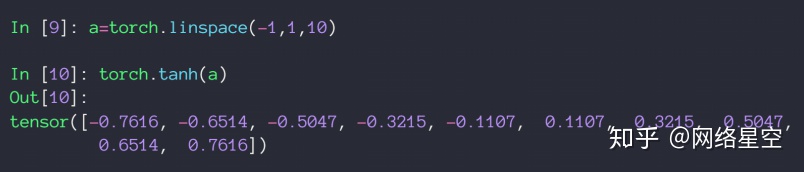
2)tanh

输出值在[-1, 1]之间
在RNN里面用得比较多
* tanh的求导推导过程
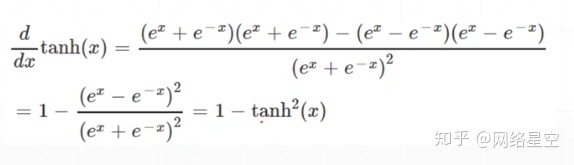
* tanh在pytorch中的实现
3)relu(Rectified Liner Unit,调整的线性流单元)
* 被大量的实验证明,relu函数很适合做deep learning。
因为:z<0时,梯度是0,z>0时,梯度是1。因为在向后传播时候,因为梯度是1,所以对于搜索最优解,梯度计算时候非常方便,也不会被放大和缩小,很难出现梯度弥散和梯度爆炸的情况。所以在神经网络中优先使用此函数。
* relu在pytorch中的实现

三、Loss以及Loss的梯度
1、MSE(mean square error):均方差

pytorch中mse的求解方法:torch.norm().pow(2) # 要记得平方
* MSE求导

* 使用pytorch自动求导
1)法一:
使用torch.autograd.grad()

2)法二:
使用mse.backward()

* 注意w.norm(),w.grad(),w.grad().norm()的区别:
w.norm()是均方差的平方根
w.grad()是导数
w.grad().norm()是导数的均方差的平方根
2、Cross Entropy Loss:

Softmax:
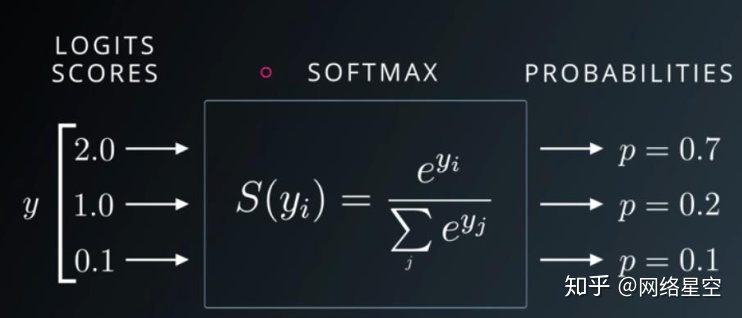
* softmax特点:
1)输出的所有值的范围是0~1
2)所有概率之和等于1。(注:sigmoid函数,所有概率的和一般是不等于1的)
输出概率最大值的 索引。
3)会将原有值之间的差距拉大。
* softmax求导:


1)当i=j时

2)当i ≠ j时

3)综合

* softmax在pytorch中的实现

上图中最后4行,分别表示:δp1/δai ,δp2/δai (i∈[0, 2])求偏导