1. Sigmoid激活函数:
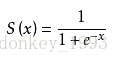

Sigmoid激活函数的缺陷:当 x 取很大的值之后他们对应的 y 值区别不会很大,就会出现梯度消失的问题。因此现在一般都不使用Sigmoid函数,而是使用ReLu激活函数。
2. ReLu激活函数:

ReLu激活函数:当x为负值之后y取0,x为正数之后,y随x的值得增大而增大,这样就可以解决梯度消失问题。现在一般都是用ReLu激活函数。
什么是梯度消失:


假设 inputer layer 和 hidden layer1 之间的参数为w1 ,layer1和layer2之间的参数为w2,layer2和output layer之间的参数为w3. 对于深度学习来说我们需要做一个求导的操作(反向传播),需要求w3,w2,w1分别对loss做的了多少贡献。w1计算对loss的贡献时需要累乘前面w2和w3的导数,w2就需要累乘w3的导数。假设我们用的是sigmoid激活函数,假设我们的取值比较大的时候w3,w2,w1的取值在sigmoid函数上面的斜率就趋近于0,这样当w3,w2, w1相乘就更加趋近于0了就出现了梯度消失的问题。