总体介绍
- 本文描述了利用强化学习原理为离散和连续系统设计反馈控制器,该控制器结合了自适应控制和最优控制的特点。自适应控制和最优控制代表了设计反馈控制器的不同思路。
- 最优控制器通常通过使用系统动力学的完整知识求解Hamilton–Jacobi–Bellman(HJB)方程(例如Riccati方程)来离线设计。非线性系统最优控制策略的确定需要离线求解非线性HJB方程,这通常很难或不可能求解。
- 相比之下,自适应控制器在线学习,使用沿系统轨迹实时测量的数据来控制未知系统。自适应控制器通常不被设计为在最小化用户规定的性能函数的意义上是最优的。间接自适应控制器使用系统识别技术首先识别系统参数,然后使用所获得的模型来求解最优设计方程[1]。自适应控制器可以满足某些逆最优性条件
- 本文表明,强化学习可以用来设计一类具有actor-critic结构的自适应控制器,该控制器通过在线、实时地求解HJB设计方程来学习最优控制解,而不需要知道整个系统模型。在线性二次型情况下,这些方法在线确定代数Riccati方程的解,而无需专门求解Riccati方程式,也无需知道系统状态矩阵A。因此,这些控制器可以被视为最优自适应控制器。
强化学习
- 强化学习是计算机科学和工程计算智能界发展起来的一种机器学习。它与最优控制和自适应控制都有着密切的联系。
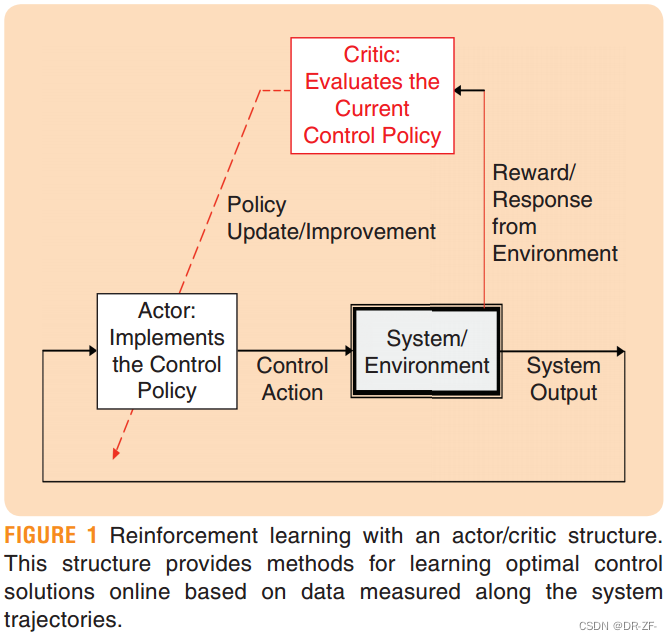
- 解释:更具体地说,强化学习是指一类能够设计自适应控制器的方法,这些控制器在线实时学习用户规定的最优控制问题的解决方案。该方法涉及一个agent,该agent与environment交互,并根据响应其动作而接收的刺激来修改其actions或control policies。强化学习受到自然学习机制的启发,动物根据从环境中获得的reward和punishment刺激来调整自己的行为。
- 历史:19世纪60年代,伊万·巴甫洛夫使用强化学习方法来训练他的狗。在机器学习中,强化学习是一种解决优化问题的方法。其他强化学习机制在人脑中发挥作用,基底神经节中的多巴胺神经递质充当强化信息信号,有利于神经元水平的学习。
- 思想:强化学习意味着action与reward或punishment之间的因果关系。它意味着目标导向的行为。强化学习算法是基于这样一种思想构建的,即必须通过强化信号记住有效的控制决策,从而使它们更有可能被第二次使用。强化学习是基于来自环境的实时评估信息,可以称为action-based learning。从理论角度来看,强化学习与自适应控制和最优控制方法都有联系。
二级目录
三级目录
来源:Lewis F L, Vrabie D, Vamvoudakis K G. Reinforcement learning and feedback control: Using natural decision methods to design optimal adaptive controllers[J]. IEEE Control Systems Magazine, 2012, 32(6): 76-105.