
从书中前面的介绍中可以看到,G通过加入一个控制变量,来达到降低方法的效果。虽然后面不知道怎么在推导正式公式的时后没有看到1-ρ的身影。。。(这里如果有知道的小伙伴,请留下您的意见)。

对于后面的这个公式来说,我的理解是:
第一:Gt+1:h也是个递归,还没展开。
第二:这个最终结果就类似树回溯算法,只不过这里用的是ρ。
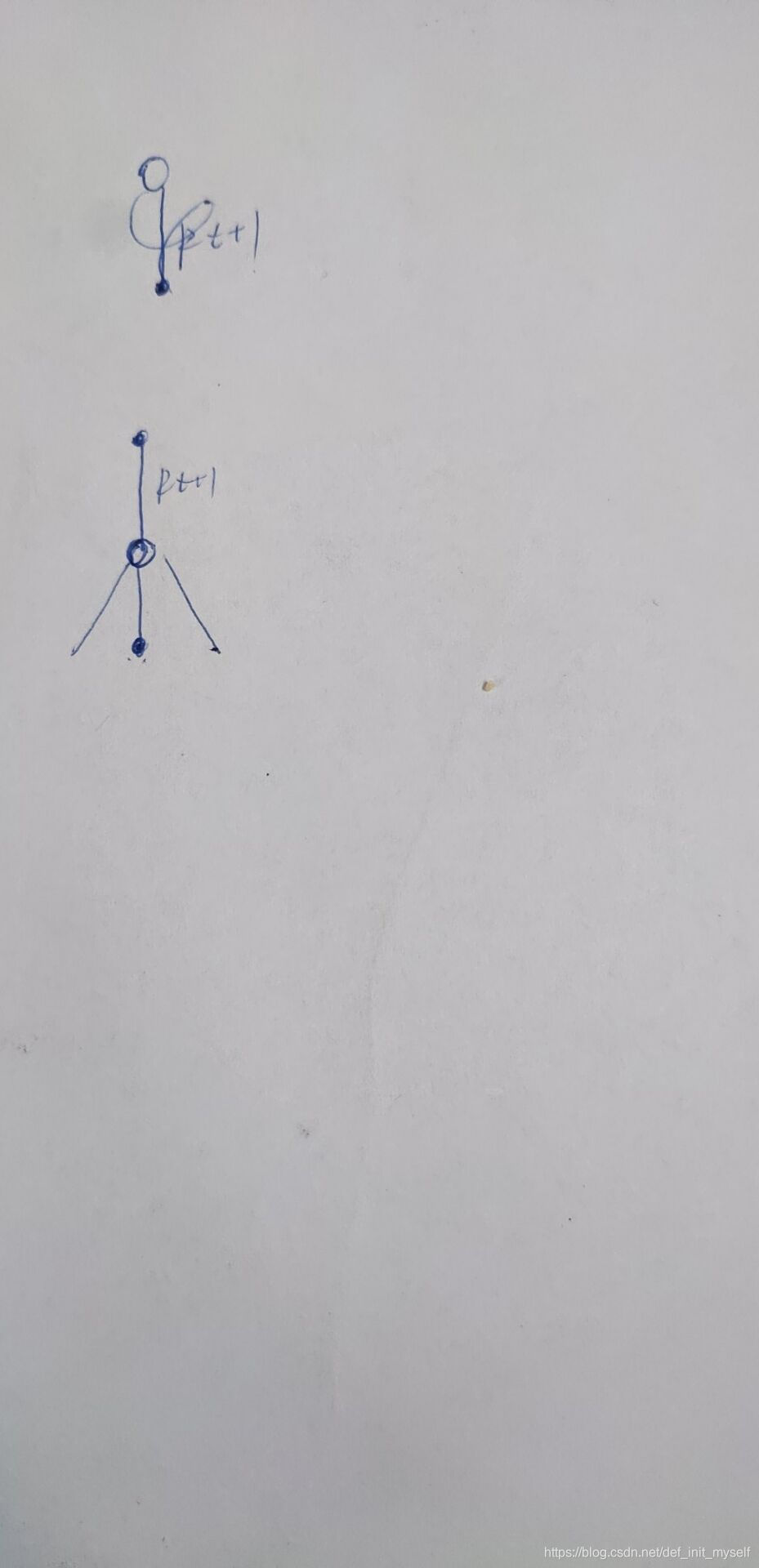
这个地方稍微画以下就可以看出。
不知理解是否到位,还请不吝指教!
——————————————————————4.15 14:46————————————————————————
又仔细看了下,发现了这样几个发现:
第一,上面那个是V的离轨策略,下面是Q的离轨策略。
第二,在Q的离轨策略里我们是R+γ(),注意括号里是V,但是虽然是V,但是由于这是关于Q的,因此我们的V是用Q的求和表示的,所以是期望的形式。然后用Q更新V的值。
即可以理解为用下一步的V更新这一步的Q
