DynamoDB有2种类型的索引:本地二级索引和全局二级索引,那么本地二级索引是什么,它有什么作用呢?今天我们就来一起聊聊DynamoDB的本地二级索引
概念
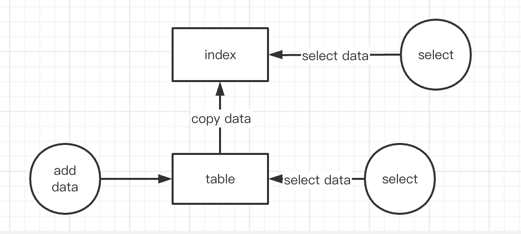
本地二级索引本质上是一种数据结构(类同于mysql中的索引的概念)。每个本地二级索引必须和一个表关联,这个表称为索引的基表,级索引可以包含基表中的某些或者全部属性。
如下图,可以把索引看作和表一样的数据结构,这样我们就能可以使用Query或者Scan从索引中检索数据。
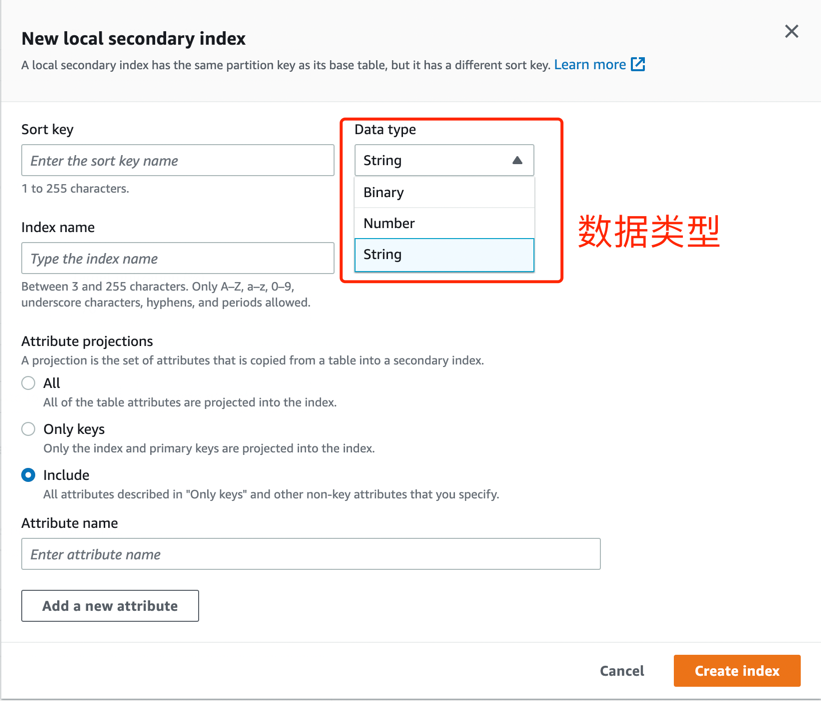
创建二级索引时,从基表投影或复制到索引中的属性,一般包含三种模式:
- 所有字段模式:基础表的所有属性都投影到索引中
- 只有keys模式:只有索引和主键被投影到索引中
- 包含模式:索引和主键以及额外指定的其他非键属性
为什么需要本地二级索引
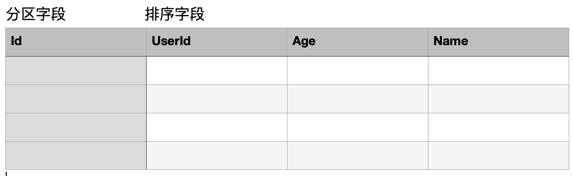
比如下面的一张User表,Partition key为Id,Sort key为UserId,当我们需要根据非属性字段Age查询所有30岁的用户时,我们就不得不全表扫描表,当表的数据达到千万甚至更大时,
这将会消耗大量的时间,因此我们会想,能不能像mysql一样,给Age字段增加一个索引。Nice,思路相当OK,为非属性字段创建索引,这就是DynamoDB的二级索引。
本地二级索引的创建
创建本地二级索引的方式有多种,这里提供两种常见的方式
控制台可视化创建
操作可以参考下图:
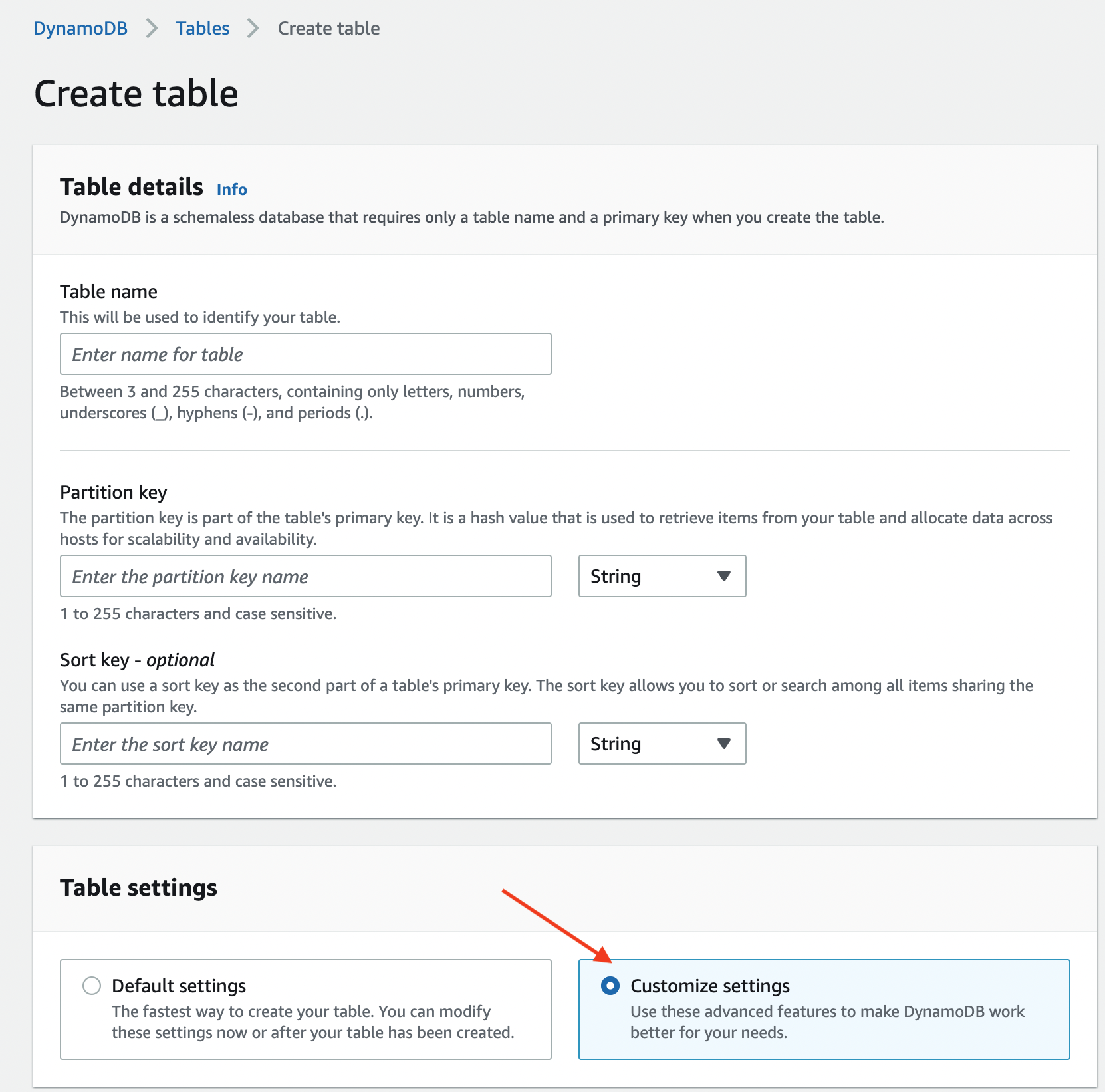
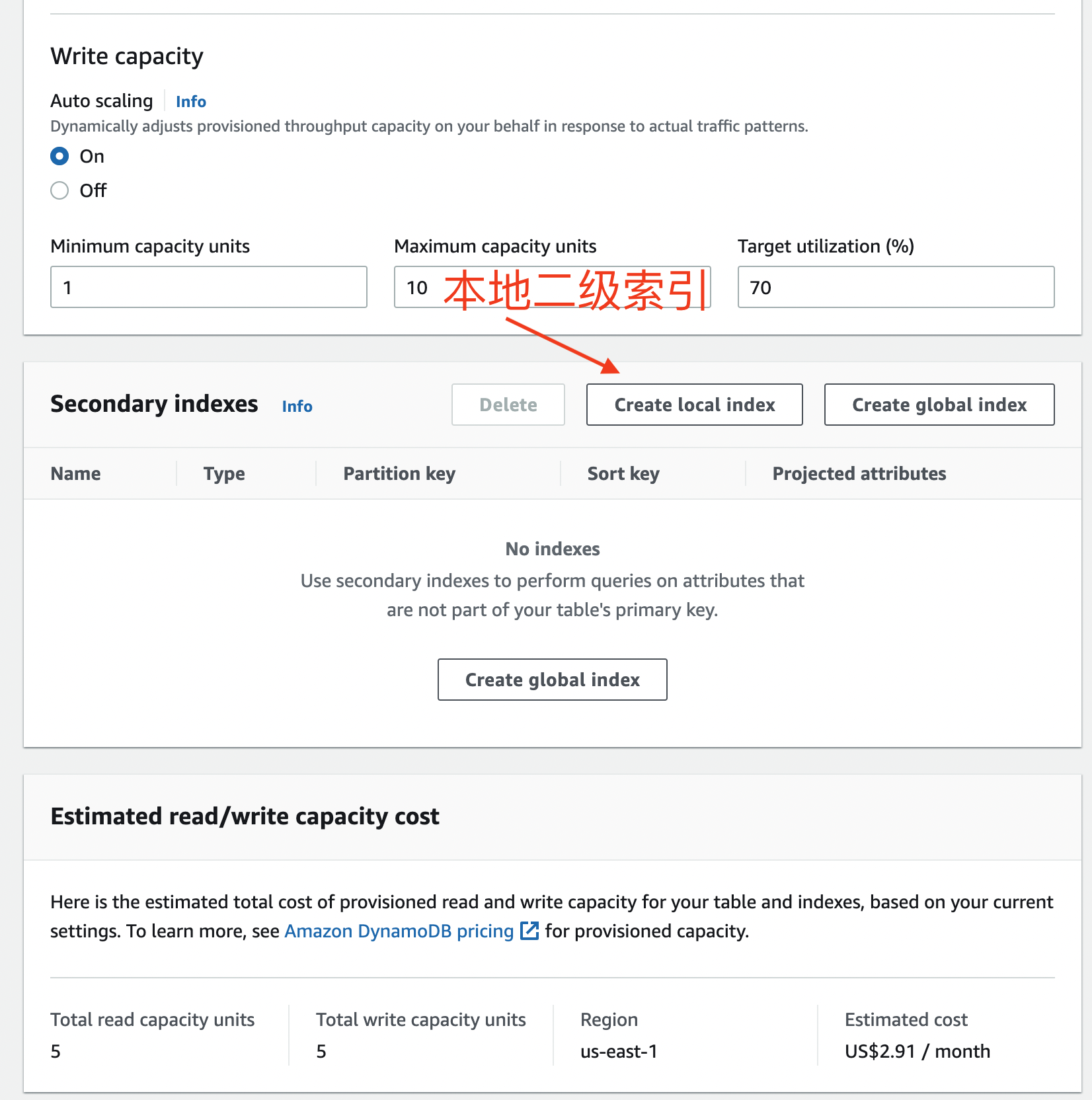
注意:在创建表的时候 Table settings 一定要选择 Customize settings(自定义),这样才能够创建本地二级索引。
点击 Create local index 按钮,弹出如下图的界面:
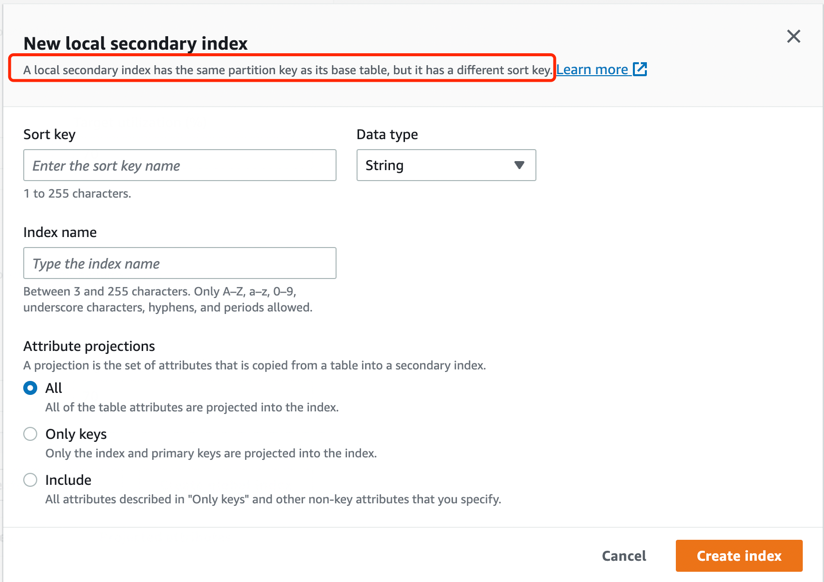
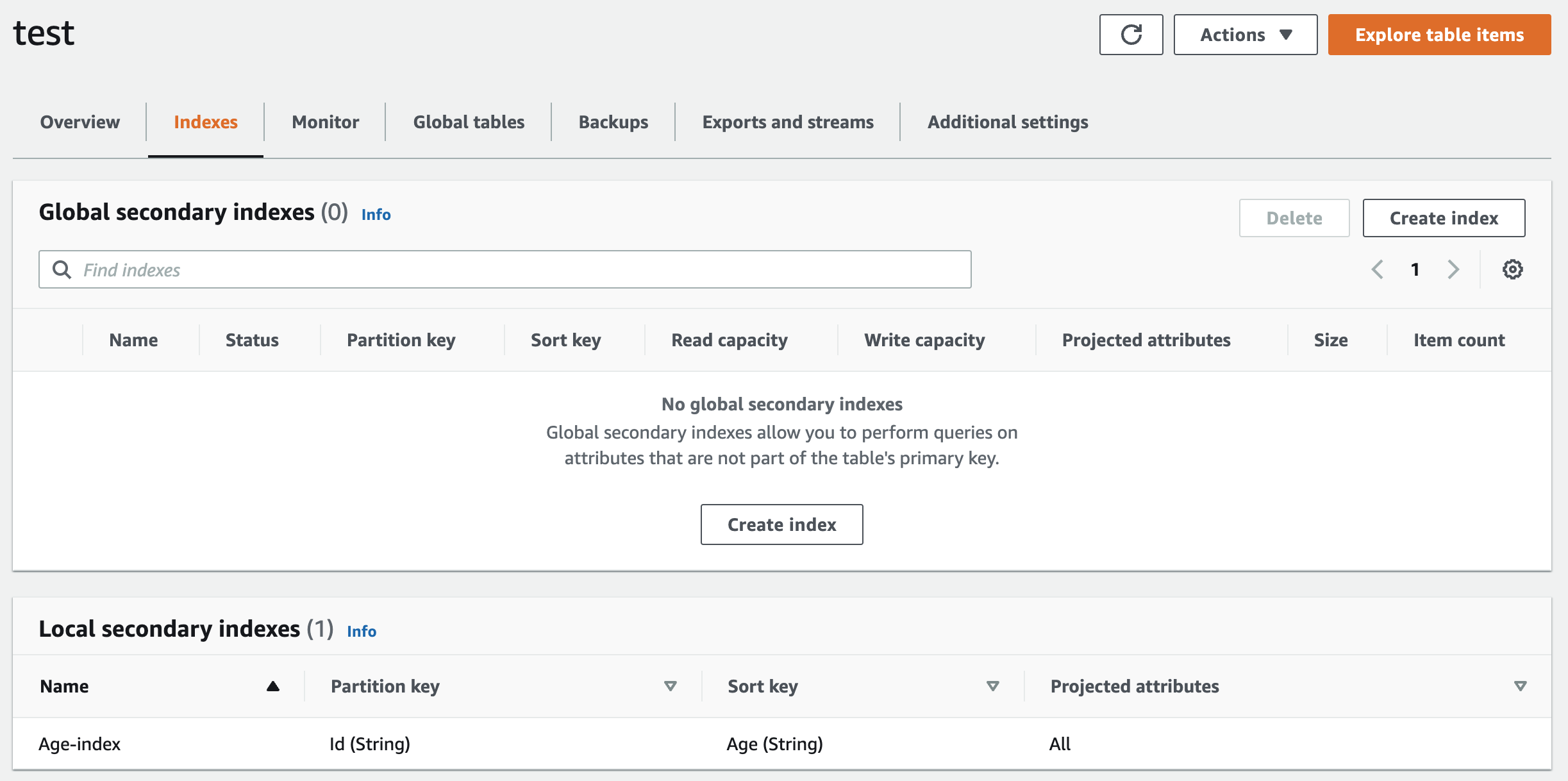
这里的Sort key和我们上面符合索引中的Partition key和Sort key不一样就ok了,比如:我这里填写的是Age, 点击Create table按钮,最后表创建完成,在表的索引列里面可以看到我们创建的本地二级索引:
当我们再创建表的时候,只填写Partition key,不填写Sort key,然后创建本地索引时,会报错,如下图:
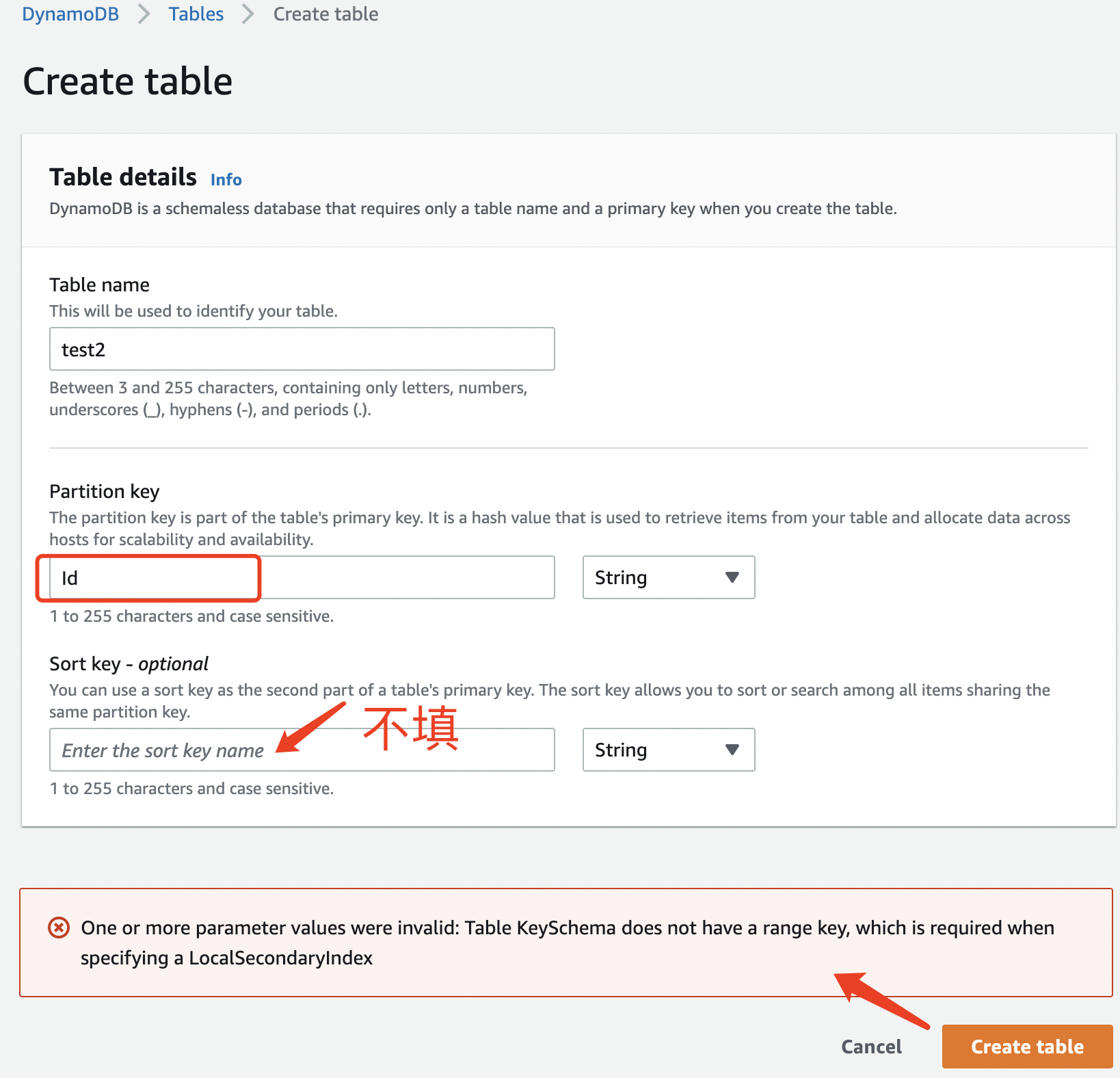
图中错误的意思就是创建本地二级索引时,需要指定一个range key,这样就证明是 本地二级只能在具有复合主键的表上添加,而且必须是在创建表的时候创建。
aws指令创建
aws指令是亚马逊提供的一套本地操作产品的指令,有点类似mysql的client指令,我们可以参考官方文档进行安装
$ aws dynamodb create-table \
--table-name test \
--attribute-definitions '[
{
"AttributeName": "Id",
"AttributeType": "S"
},
{
"AttributeName": "Age",
"AttributeType": "N"
},
{
"AttributeName": "Name",
"AttributeType": "S"
}
]' \
--key-schema '[
{
"AttributeName": "Id",
"KeyType": "HASH"
},
{
"AttributeName": "Age",
"KeyType": "RANGE"
}
]' \
--local-secondary-indexes '[
{
"IndexName": "Age-index",
"KeySchema": [
{
"AttributeName": "Id",
"KeyType": "HASH"
},
{
"AttributeName": "Age",
"KeyType": "RANGE"
}
],
"Projection": {
"ProjectionType": "KEYS_ONLY"
}
}
]' \
--provisioned-throughput '{
"ReadCapacityUnits": 1,
"WriteCapacityUnits": 1
}' \
本地二级索引的使用
在上文中我们创建了一个本地二级索引 Age-index,我们需要使用该本地二级索引从test表中查询age=30的用户,java代码例子如下:

public class Test {
public static void main(String[] args) {
String tableName = "Test";
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable(tableName);
Index index = table.getIndex("Age-index");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Age = :age")
.withValueMap(new ValueMap().withInt(":age", 30));
// index.query(), 把index作为一个数据载体作为查询,是不是很类同有table.query()?
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> itemsIter = items.iterator();
while (itemsIter.hasNext()) {
Item item = itemsIter.next();
}
}
}
注意事项
- 本地二级索引与基表拥有相同的Hash键(Partition key),不同的Range键(Sort key);
- 本地二级索引只能在具有复合主键的表上添加并且是创建基表时创建,不能在现有的表上去添加;
- 对于任何本地二级索引,每个不同的分区键值(Partition key)最多可以存储10GB的数据,此数字包括基表中的所有Item,以及索引中具有相同分区键值的所有Item;
- 每个本地二级索引都会自动包含其基表中的分区键和排序键;
- DynamoDB会自动维护本地二级索引,当表中有增、删、改操作时,DynamoDB 会自动把数据的变动维护到索引中;
吞吐量和成本权衡
亚马逊把DynamoDB封装得如此开箱即用也不是没有目的,那就是商业付费,因此我们在使用本地二级索引时需要根据自己的使用场景来权衡吞吐量和成本,主要有如下的场景
-
尽可能低的延迟访问少数属性,可以考虑仅将这些属性投影到本地二级索引中。索引越小,存储成本就越低,写入成本也就越低。
-
经常访问一些非关键属性,可以考虑将这些属性投影到本地二级索引中。本地二级索引的额外存储成本抵消了执行频繁表扫描的成本。
-
频繁访问大多数非键属性,可以考虑将这些属性(甚至整个基表)投影到本地二级索引中。这种方式提供了最大的灵活性和最低的预置吞吐量消耗,因为不需要提取。但是,因为投影了所有属性,存储成本会增加。
-
写入或更新频繁,查询较少,可以考虑KEYS_ONLY模式投影到本地二级索引中。本地二级索引将具有最小大小,但在查询活动需要时仍然可用。
本地二级索引适用范围
本地二级索引限制了必须和基表拥有相同的Partition key,而Sort key可以灵活变更,因此 本地二级索引其实就是扩展了基表复合主键的Sort key。