1、设计思想
索引的思想依然是倒排索引的思想,即将需要查询的列作为索引数据的Rokwey,查询列所在记录的Rowkey作为索引数据的value。
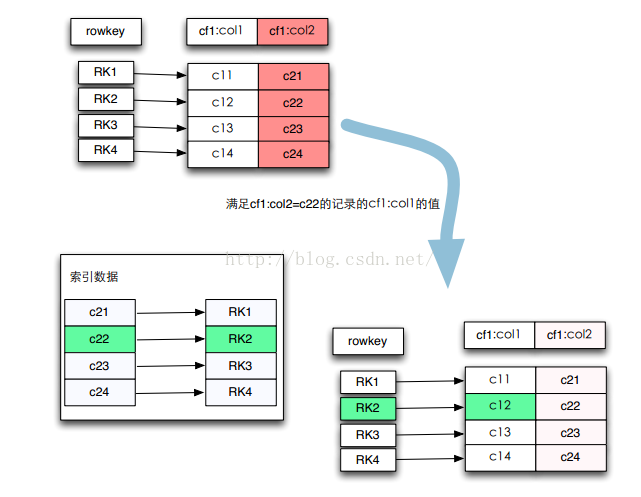
2、索引设计
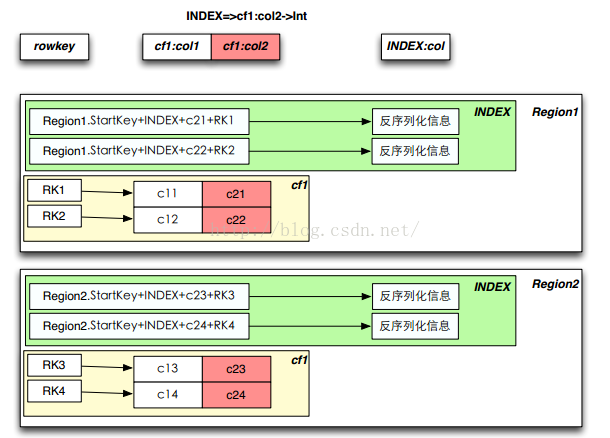
该方案是将索引与数据放在了同一个Region的不同family里。索引的Rowkey首字段是Region的startKey,它保证了索引和数据在同一个Region里,接下来是索引的类型INDEX,然后是建索引的列,最后是该列所在的记录的RowKey,索引的value是用来解析索引RowKey的反序列化信息。
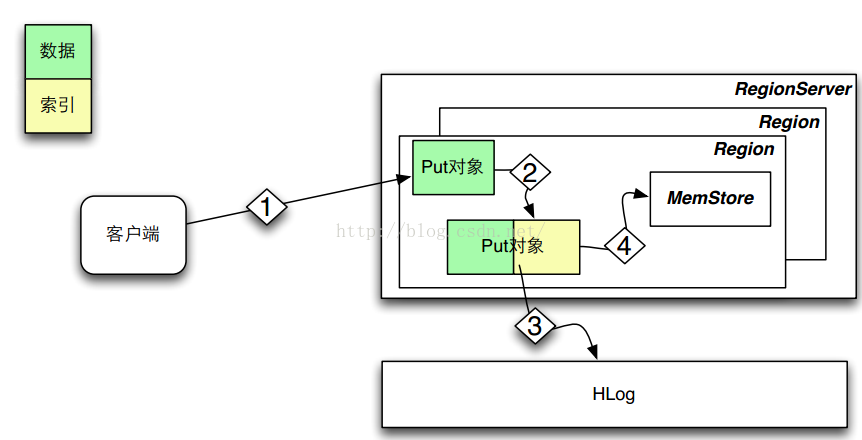
3、写路径
几乎没变化。写数据时,先看索引说明里,看哪些列需要建索引,然后给这些列建立索引,将索引和数据都放在同一个put对象中。
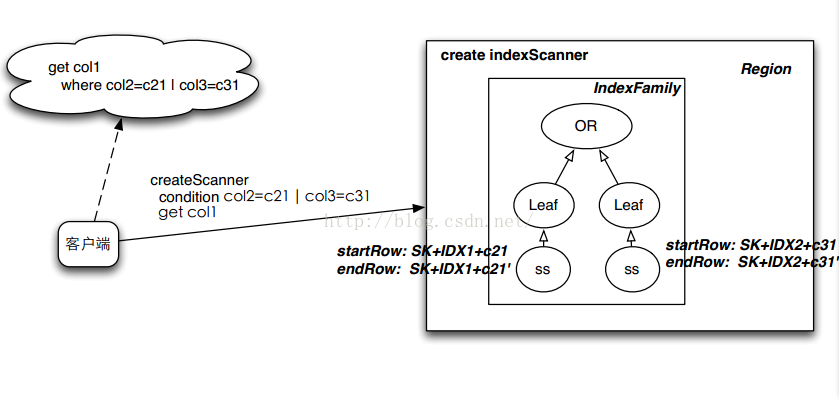
4、读路径
先需要创建一个scanner,这里扩展了scanner对象,下面的一个框图代表一个Region。查询时先通过查询条件建立一棵检索树,然后通过检索树去找RowKey,最后通过RowKey去原表seek数据。

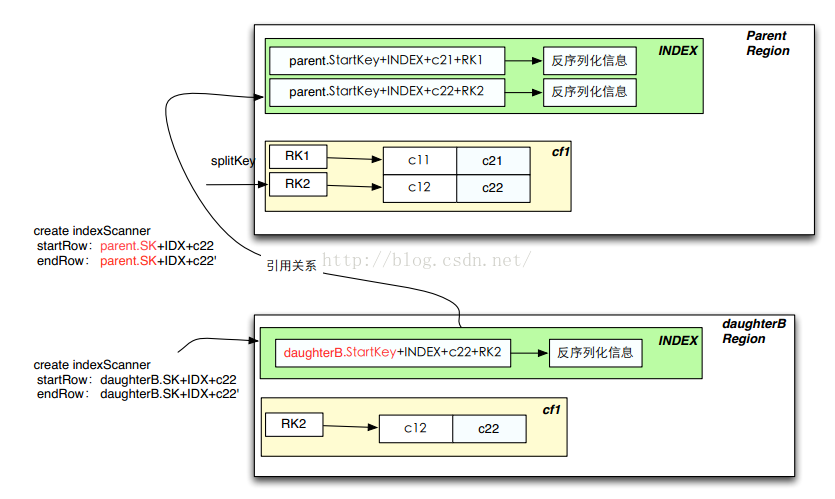
5、分裂
针对索引,产生一次分裂后,第一个daughter没有任何变化信息,第二个daughter的索引rowkey需要变更一下。
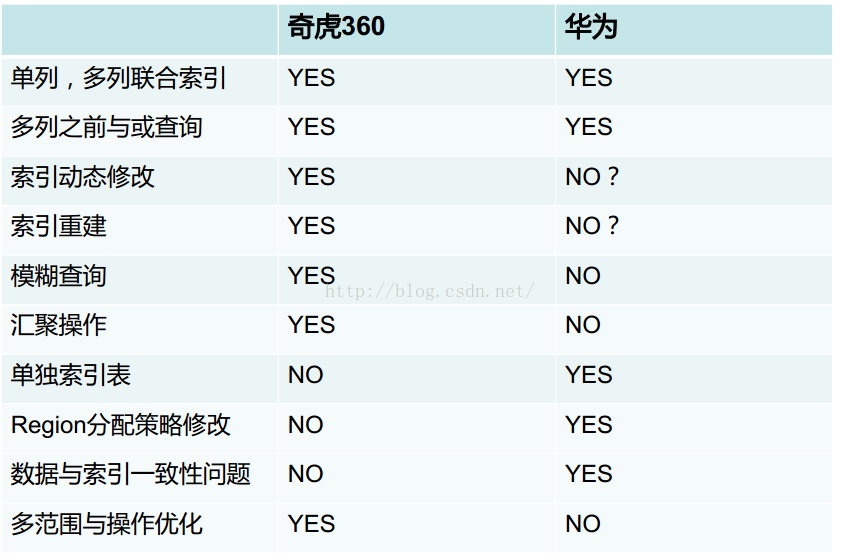
6、与华为Hbase二级索引方案的比较
7、性能
7.1 单并发写入性能
写代价的损失很小。

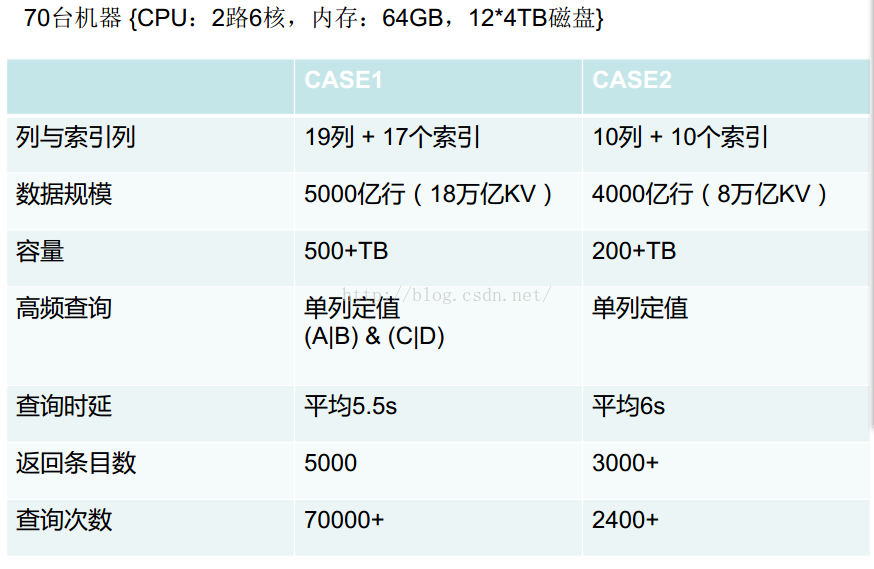
7.2 检索性能数据
收藏好文:https://blog.csdn.net/dhtx_wzgl/article/details/49069081