原文链接:https://www.techbeat.net/article-info?id=4629
作者:郑宇鹏
本文中,我们提出了STEPS,第一个自监督框架来联合学习图像增强和夜间深度估计的方法。它可以同时训练图像增强网络和深度估计网络,并利用了图像增强的中间量生成了一个像素级mask来抑制过曝和欠曝区域。通过大量的实验研究表明,我们的方法在这两种区域取得了更好的效果。此外,我们提出了一个增强到显示风格的仿真数据集CRALA-EPE,它以低成本、稠密的ground truth为室外场景的深度估计任务提供了更多的可能。

论文链接:
https://arxiv.org/abs/2302.01334
代码链接:
https://github.com/ucaszyp/STEPS
一、 简介
近年来,基于图像的自监督深度估计方法不仅所需的硬件成本低,而且不需要真值的标注,因此受到了广泛的关注。该类方法本质上依赖于相邻帧光度一致性的假设,通过合成图和目标图的光度误差进行模型的训练。
然而在夜间环境下,图像中包含了大量的欠曝和过曝区域,它们在相邻帧之间有较明显的差异,同时掩盖了对应区域的有效信息,如图1(a)的第一行所示。我们在nuScenes数据集的测试集上评测了基线方法RNW预测的深度值和真值的均方根误差值(RMSE),同时我们人工挑选了其中100多个过曝和欠曝的场景,做了如图1(b)所示的统计结果。可以看出,在这两种特殊场景下,RNW的表现要低于平均水平,可视化效果如图1(a)的第二行所示。
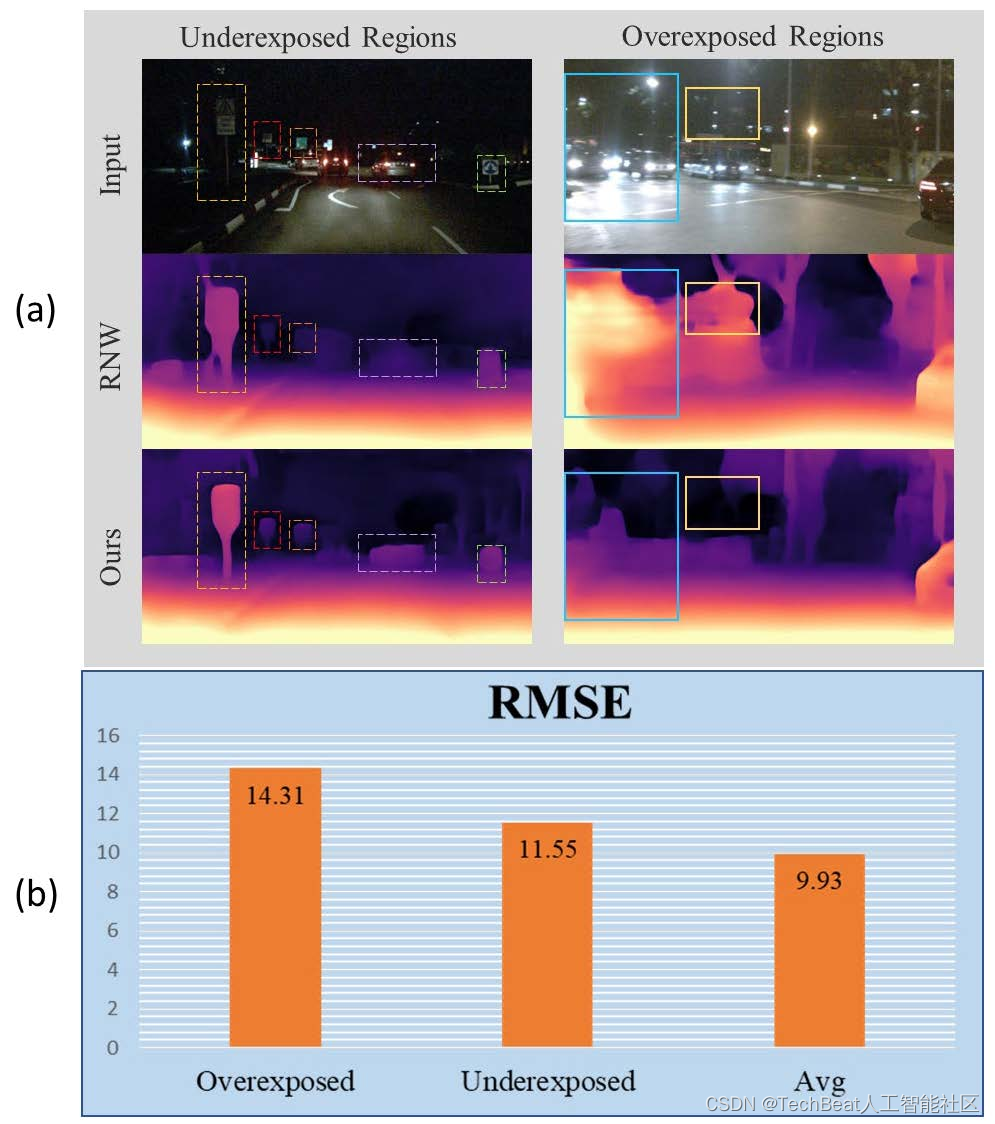
图1 夜间深度估计的挑战。(a)第一行,nuScenes数据集中过曝和欠曝的场景;第二行,RNW预测的深度图;第三行,STEPS预测的深度图。(b)过曝(Overexposed),欠曝(Underexposed)和测试集平均(Avg)的RMSE。
针对欠曝的区域,前人提出了先进行图像增强再做深度估计的方法。虽然他们提出了各种有监督的夜间图像增强方法,但在具有挑战性的驾驶场景中的泛化性能并不令人满意,而且需要一定量的人工标注。针对过曝区域对深度估计的影响的研究还较少。为此,我们提出了STEPS,第一个自监督联合学习夜间图像增强和深度估计的方法,同时不使用任何ground truth。
此外,针对欠曝和过曝区域,我们提出了不确定像素掩膜策略。它基于图像增强的中间产物来过滤影响深度估计的图像区域,从而将两个自监督任务紧密地结合在一起。对比图1(a)的第二行和第三行可以明显发现,受益于我们的框架和策略,STEPS在欠曝和过曝区域的表现要优于基线方法。最后,我们还提出了CARLA-EPE,一个基于CARLA仿真器的增强到现实风格的夜间数据集。它具有密集的深度图的标注,且更接近现实的图像风格,为深度估计任务带来更多的可能性。
二、方法
模型架构
如前所述,夜间图像增强可以提高输入图像的质量,以帮助进行深度估计。但是有监督的夜间图像增强在本质上受到数据集自身分布的限制。因此,我们提出了一个以自监督的方式联合训练深度估计和图像增强的框架,如图2所示。它包含自监督图像增强模块(SIE),夜间自监督深度估计模块,由目标帧( I t I_t It)经过SIE生成的光照图( x t x_t xt)将两个模块联系在一起。
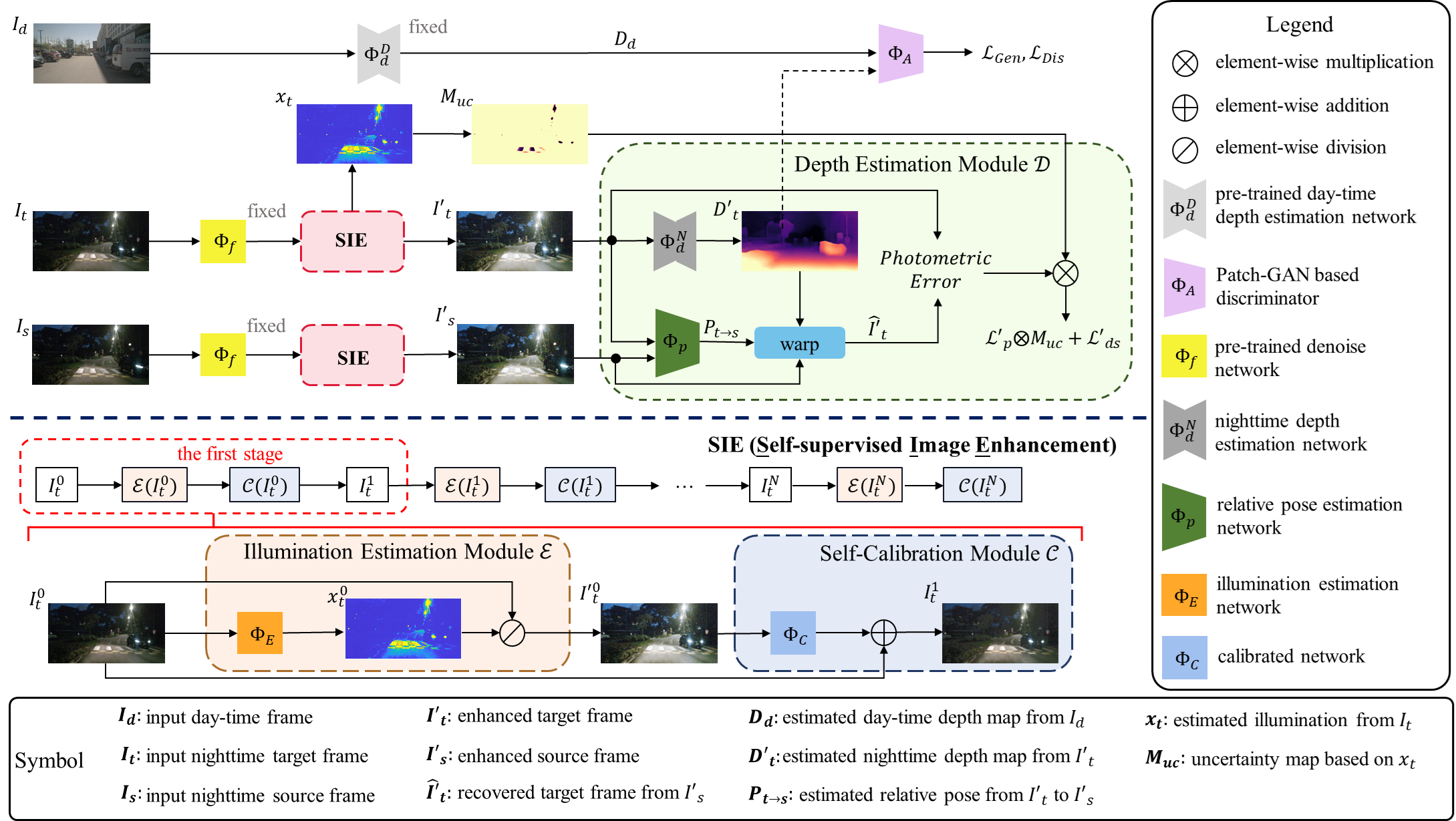
图2 整体模型架构
自监督图像增强模块
根据Retinex理论,给定一个低光图像 I I I ,可以通过
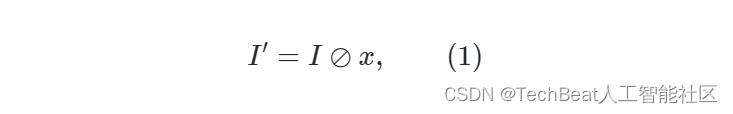
得到增强图像,其中 x x x 是光照图,图像增强最重要的部分, I ′ I' I′ 是反射图,也被认为是得到的增强图像。一个不准确的照明估计可能会导致过度增强的结果。为了提高性能稳定性和减少计算负担,我们采用SCI的自校准模块结构进行阶段级照明估计。
如图2底部所示,给定输入的图像,如 I t I_t It,增强过程可以表示为:
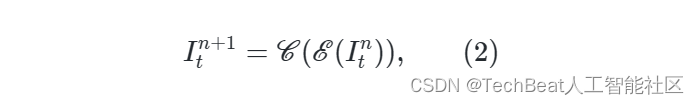
其中n(0<n<3)为级数, E \mathscr{E} E 和 C \mathscr{C} C 分别表示光照估计模块和校准模块。 对于第n级, E \mathscr{E} E 和 C \mathscr{C} C 是通过以下步骤实现的:
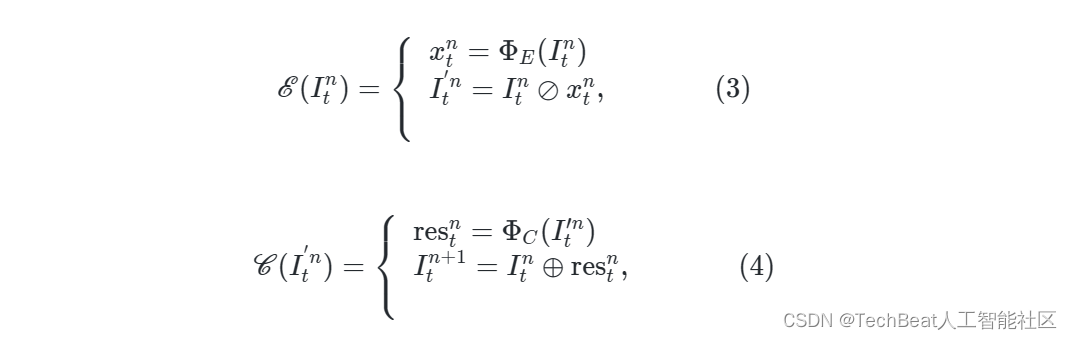
其中, Φ E \Phi_E ΦE 和 Φ C \Phi_C ΦC 是可训练网络,分别用于估计光照图 x n t x_n^t xnt 和生成校准残差图 r e s t n res^n_t restn。校正模块重新生成伪夜间图像,使SIE可以分几个级应用,经验校正带来更快的收敛速度和更好的增强效果。
训练时,我们使用与SCI相同的损失函数,即保真度损失和平滑损失。保真度损失的原理是对于夜间图像,光照分量在很大程度上与输入图像相似损失,它可以表示为:
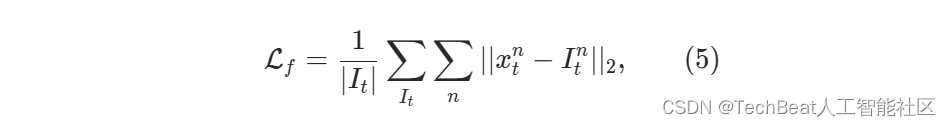
平滑度损失是一种一致性正则化损失,可以表示为:
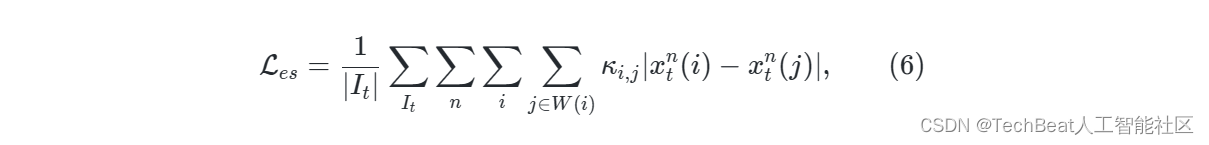
其中 κ i , j \kappa_{i,j} κi,j 高斯核的权重, W ( i ) {W}(i) W(i) 是以像素 i i i 为中心的 5 × 5 5 {\times} 5 5×5 大小的窗口, x ( i ) x(i) x(i) 表示光照图 x x x 在像素 i i i 处的值。
夜间自监督深度估计模块
自监督深度估计首先由Sfm-learner提出,它的关键思想是从给定源帧( I s I_s Is)根据几何约束重建目标帧( I t I_t It)。 具体来说,给定已知的摄像机内参矩阵 K K K、可训练网络 Φ d : R H × W × 3 → R H × W \Phi_{d}: \mathbb{R}^{H\times W\times 3} \rightarrow\mathbb{R}^{H\times W} Φd:RH×W×3→RH×W 预测 I t I_t It 的深度图 D t D_t Dt 和可训练网络 Φ p : R H × W × 6 → R 4 × 4 \Phi_{p}: \mathbb{R}^{H\times W\times 6} \rightarrow\mathbb{R}^{4\times4} Φp:RH×W×6→R4×4 预测的 I s I_s Is 与 I t I_t It 之间的相对位姿 P t → s ∈ R 4 × 4 P_{t \to s} \in\mathbb{R}^{4\times4} Pt→s∈R4×4 , I t I_t It 中的每一个点 p t p_t pt 都可以投影到 I s I_s Is 中的 p s p_s ps 上,投影公式表示为:
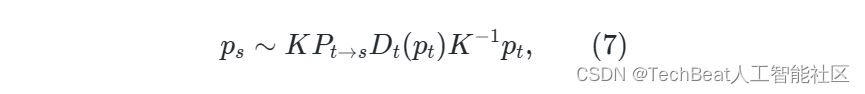
其中, ∼ \sim ∼ 表示齐次等价。此时,我们可以利用下面的公式从 I s I_s Is 中重建出目标帧,重建的目标帧记作 I t ^ \hat{I_t} It^
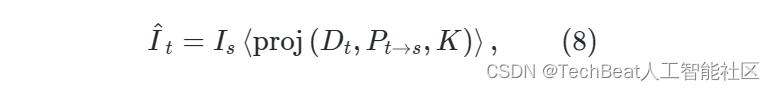
其中, < ⋅ > \big < \cdot \big > ⟨⋅⟩ 是STN提出的可微双线性插值, p r o j ( ⋅ , ⋅ , ⋅ ) \rm proj(\cdot,\cdot,\cdot) proj(⋅,⋅,⋅) 表示公式 ( 7 ) (7) (7)。
自监督训练的损失函数是 I t I_t It 与重建帧 I t ^ \hat{I_t} It^ 之间的光度误差。我们采用MonoDepth2的方法,将L1损失和SSIM损失函数合并为光度损失函数 L p \mathcal{L}_p Lp,其定义为:
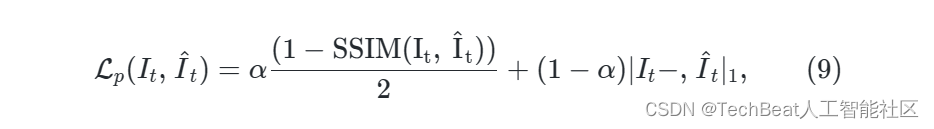
其中 α \alpha α 是超参数,通常设置为0.85。另外,我们遵循MonoDepth2,通过加强预测深度图的平滑性来避免深度歧义,即
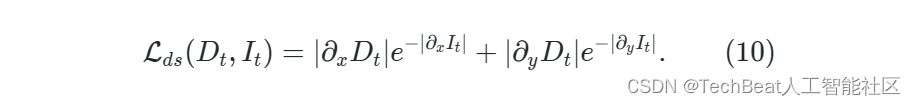
由于夜间图像质量较差,公式 ( 9 ) (9) (9) 的梯度带有从噪声。为了缓解这种情况,我们在RNW的基础上引入了一个预训练的白天深度估计模型 Φ d D \Phi^D_{d} ΦdD ,并通过一种对抗的方式指导夜间模型的训练。构造夜间深度估计网络 Φ d N \Phi^N_{d} ΦdN 作为生成器,通过训练使其预测值 D t D_t Dt 与 Φ d D \Phi^D_{d} ΦdD 的输出值 D d D_d Dd 不可区分。 基于Patch-GAN的鉴别器 Φ A \Phi_{A} ΦA 是一个可训练的网络,它来区分 D d D_d Dd 和 D t D_t Dt 。 Φ d N \Phi^N_{d} ΦdN 和 Φ A \Phi_{A} ΦA 是通过最小化对抗式损失函数来训练的,该函数表示为
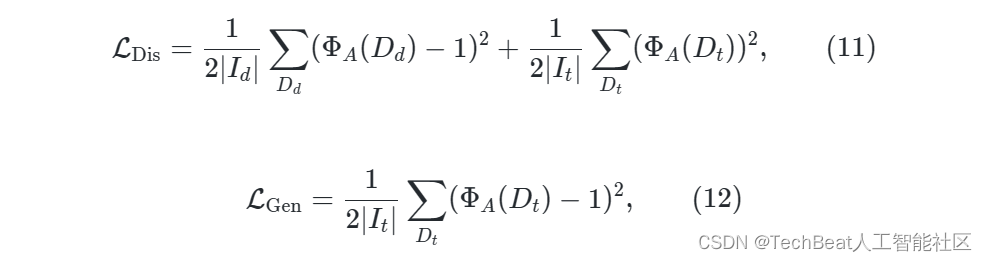
其中, ∣ I d ∣ |I_d| ∣Id∣ 和 ∣ I t ∣ |I_t| ∣It∣ 是白天和夜间训练图像的数量, D d = Φ d D ( I d ) D_d = \Phi^D_{d}(I_d) Dd=ΦdD(Id) , D t = Φ d N ( I t ) D_t = \Phi^N_{d}(I_t) Dt=ΦdN(It) 。
联合训练
两个模块联合训练的过程如图2所示,SIE的第一级的输出的增强结果 I t ′ I'_t It′ 和 I s ′ I'_s Is′ 作为深度估计模块的输入。公式 ( 8 ) (8) (8), ( 9 ) (9) (9), ( 10 ) (10) (10) 和 ( 11 ) (11) (11) 中,目标帧 I t I_t It 和重建帧 I t ^ \hat{I_t} It^ 分别被增强的目标帧 I t ′ I'_t It′ 和增强源帧 I s ′ I'_s Is′ 重建后图像 I t ′ ^ \hat{I'_t} It′^ 所取代。
基于统计的光照不确定性mask
如文章开头所描述,夜间图像通常包含欠曝和过曝的区域,这些区域会丢失重要的细节信息,导致估计的深度值不准确。而且,过曝区域往往与汽车的运动(如车灯)相关联,这也违反了自监督深度估计中的光照一致性假设。因此,我们需要设计某种机制来滤除这些区域去训练的影响。经研究发现,SIE 可以预测一个光照图 x t x_t xt ,以确定每个像素的颜色的增强比。如图3所示,欠曝区域的比值较大,过曝区域的比值较小。如果我们用这个来衡量每个像素在光度损失中的重要性,则可以最大可能减小这两个区域对训练的影响。
注意,我们给不确定区域每个像素点一个置信度,希望它们能参与到训练中,而非直接强硬地全部遮盖掉。
具体来说,我们定义了一个不确定映射 M u c ∈ R H × W M_{uc} \in \mathbb{R}^{H\times W} Muc∈RH×W ,它在欠曝和过曝区域中给出了低置信度,在合理区域中给出了高置信度。 M u c M_{uc} Muc 表示为:
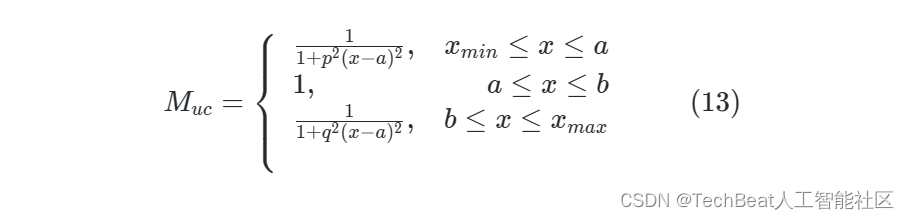
其中 a a a 和 b b b 是基于统计的光照值处于合理区域的上下界, p p p 和 q q q 是衰减系数。如图3所示,直观地看,这个函数看起来像一个桥,它利用光照图生成不确定mask。
这个建模源于我们对两个夜间数据集光度图的统计,它可以遮掩过曝和欠曝区域的像素,又不会过多遮掩过对训练有帮助的像素点。
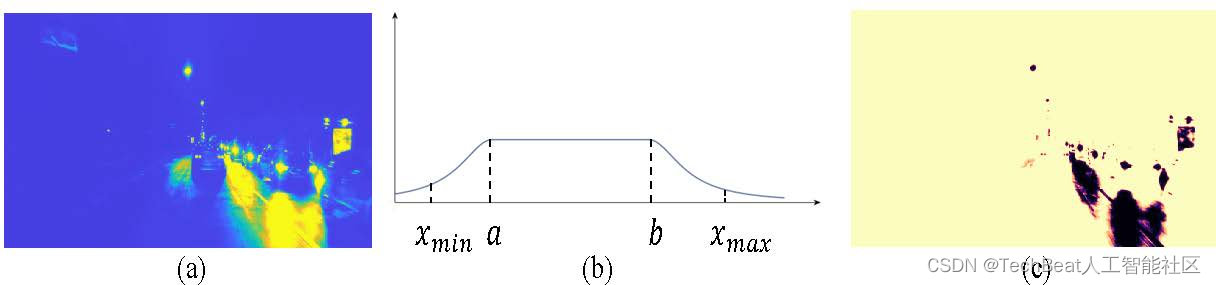
图3 M u c M_{uc} Muc 的原理。 (a)光照图 x t x_t xt 。 (b) M u c M_{uc} Muc 函数,该函数可以柔和地屏蔽过曝和弱曝区域。 © 不确定mask的可视化
三、实验
数据集
我们在nuScence数据集和RobotCar数据集上和其他方法做了比较。此外,针对真实数据集成本高、深度图稀疏以及仿真器数据域与现实数据域差异大的痛点,我们提出了增强到现实风格的仿真数据集CARLA-EPE。
nuScenes-Night
nuScenes是一个大规模的自动驾驶数据集。它包含多种天气环境下复杂的道路场景,十分具有挑战性。
RobotCar-Night
RobotCar数据来源于RobotCar团队一年的时间内在各种天气下频繁地穿越牛津市中心的同一条路线时的驾驶记录,包括车辆上的6个摄像头数据以及激光雷达、GPS和INS数据。
CARLA-EPE
上述两个数据集的真实深度均来自激光雷达,然而,激光雷达数据的采集是昂贵的,并且只能提供稀疏的深度图。为此,我们将目光放在了仿真数据上。RGB图像和相应的密集深度图可以很容易地在仿真器(例如CARLA)中收集,但仿真图像和真实图像之间的分布差异极大地影响了训练模型在真实场景中的应用。因此,我们提出了一个基于CARLA和增强图片真实感的网络EPE的夜间深度估计数据集CARLA-EPE,它可以提供密集的深度真值和迁移到真实风格的图像,如图4所示。

图4 EPE增强后的图像(CRALA-EPE)与增强前(CRALA)的对比。
实验结果
如表1所示,我们在nuScenes数据集和RobotCar数据集上均达到了SOTA,在准确率和误差上均有显著的提升。在更具挑战性的nuScenes数据集上,我们的a1相较于baseline提升了16.2%,abs_rel相较于baseline降低了10.4%。
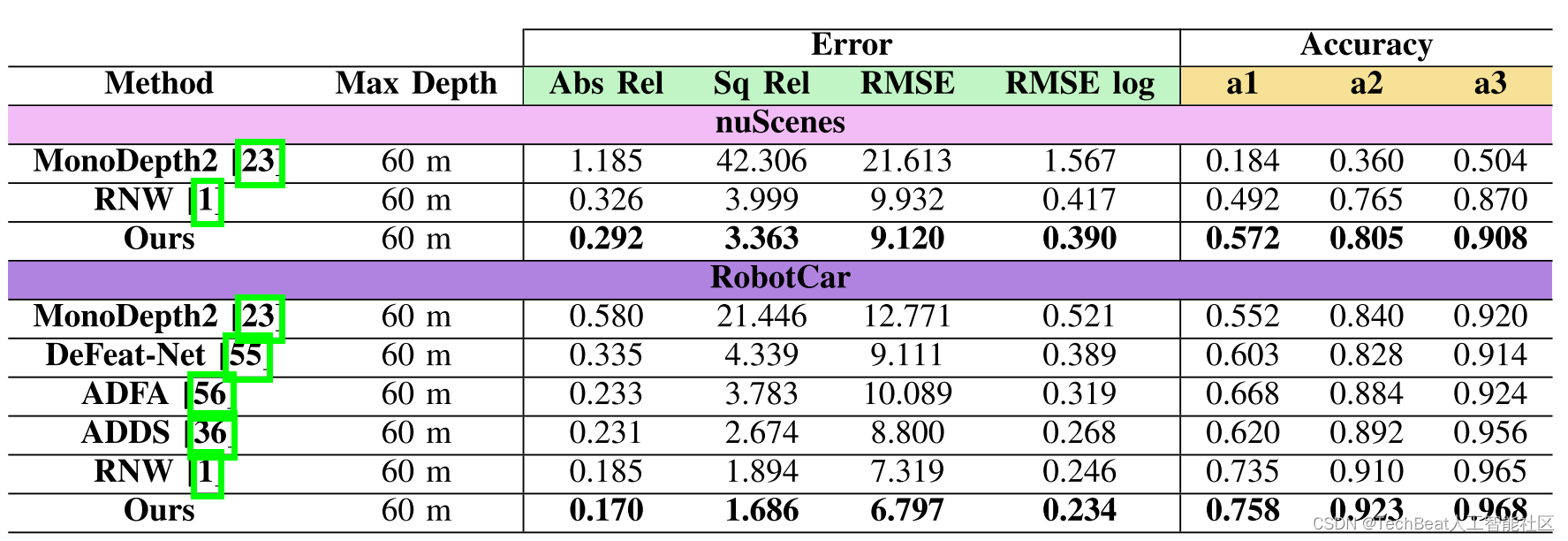
表1 nuScenes数据集和Oxford数据集的定量结果。
可视化结果
如图5所示,蓝色方框展示了基线方法受到过曝的影响,预测了错误的深度。 红色方框还表明基线方法在欠曝区域错误地估计物体深度。由于我们的方法提出了新的框架和自适应掩膜的策略,因此可以使模型在这两种区域中预测出更合理的深度。

图5 可视化结果。
四、总结与展望
我们提出了STEPS,第一个自监督框架来联合学习图像增强和夜间深度估计的方法。它可以同时训练图像增强网络和深度估计网络,并利用了图像增强的中间量生成了一个像素级mask来抑制过曝和欠曝区域。通过大量的实验研究表明,我们的方法在这两种区域取得了更好的效果。此外,我们提出了一个增强到显示风格的仿真数据集CRALA-EPE,它以低成本、稠密的ground truth为室外场景的深度估计任务提供了更多的可能。
参考文献
[1] nuscenes: A multimodal dataset for autonomous driving: https://www.nuscenes.org
[2] Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark: https://arxiv.org/abs/2108.03830
[3] Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark: https://arxiv.org/abs/2108.03830
[4] The retinex theory of color vision.: https://lambentresearch.com/color/docs/LandRetinex.pdf
[5] Toward Fast, Flexible, and Robust Low-Light Image Enhancement: https://openaccess.thecvf.com/content/CVPR2022/html/Ma_Toward_Fast_Flexible_and_Robust_Low-Light_Image_Enhancement_CVPR_2022_paper.html
[6] Unsupervised Learning of Depth and Ego-Motion from Video: https://arxiv.org/abs/1704.07813
[7] Spatial transformer networks: https://arxiv.org/abs/1506.02025
[8] Digging Into Self-Supervised Monocular Depth Estimation: https://arxiv.org/abs/1806.01260
[9] Image-to-Image Translation with Conditional Adversarial Networks: https://arxiv.org/abs/1611.07004
[10] Enhancing photorealism enhancement: http://vladlen.info/papers/EPE.pdf
Illustration by nanoagency from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
[email protected]