
Title: Lite-Mono: A Lightweight CNN and Transformer Architecture for
Self-Supervised Monocular Depth Estimation
Paper: https://arxiv.org/pdf/2211.13202.pdf
Code: https://github.com/noahzn/Lite-Mono
导读
自监督单目深度估计近年来引起了人们的关注。设计轻量但有效的模型,使它们能够部署在边缘设备上是非常有趣的。许多现有的架构受益于使用heavier的backbones,为了深度性能而牺牲了模型的大小。在本文中,研究者使用一个轻量级的体系结构来实现了具有竞争力的结果。具体来说,论文研究了CNN和Transformer的有效组合,并设计了一个混合结构Lite-Mono。提出了一种连续扩张卷积(CDC)模块和一个局部-全局特征交互(LGFI)模块。前者用于提取丰富的多尺度局部特征,后者利用自注意机制将随机的全局信息编码到局部特征中。实验表明,论文的完整模型在精度上大大优于Monodepth2,模型参数减少了约80%。
动机
- 由于缺乏大规模精确的ground truth深度数据集,从单目视频中寻找监督信号的自监督方法是有利的。
- CNN中的卷积操作有一个局部接受域,不能捕获长期的全局信息,更深的主干或更复杂的架构导致更大的模型规模
- 最近引入的Vision Transformer能够建模全局上下文进行单目深度估计,以获得更好的结果。然而,与CNN模型相比,Transformer中多头自注意力模块的昂贵计算阻碍了轻量级和快速推理模型的设计
贡献
本文提出了一个追求轻量级和高效的混合CNN和Transformer的自监督单目深度估计模型。在该编码器的每个阶段,都采用了一个连续扩张卷积模块来捕获增强的多尺度局部特征。然后,论文使用一个局部-全局特征交互模块来计算多头注意力,并将全局上下文编码到特征中。为了降低计算复杂度,论文还计算了信道维数而不是空间维数上的交叉协方差注意。该方法的贡献可以分为三个方面:
- 论文提出了一种新的轻量级架构,称为Lite-mono,同时利用CNN和Transformer用于自监督单目深度估计。论文证明了它对模型大小和FLOPs的有效性。
- 与更大的模型相比,Lite-mono在KITTI数据集上显示出更高的精度。它以最少的可训练参数达到了最先进的水平。在Make3D数据集上进一步验证了该模型的泛化能力。论文还进行了额外的笑容实验来验证不同设计选择的有效性。
- 在Nvidia Titan XP和Jetson Xavier平台上测试了该方法的推理时间,证明了该方法在模型复杂性和推理速度之间的良好权衡。
方法
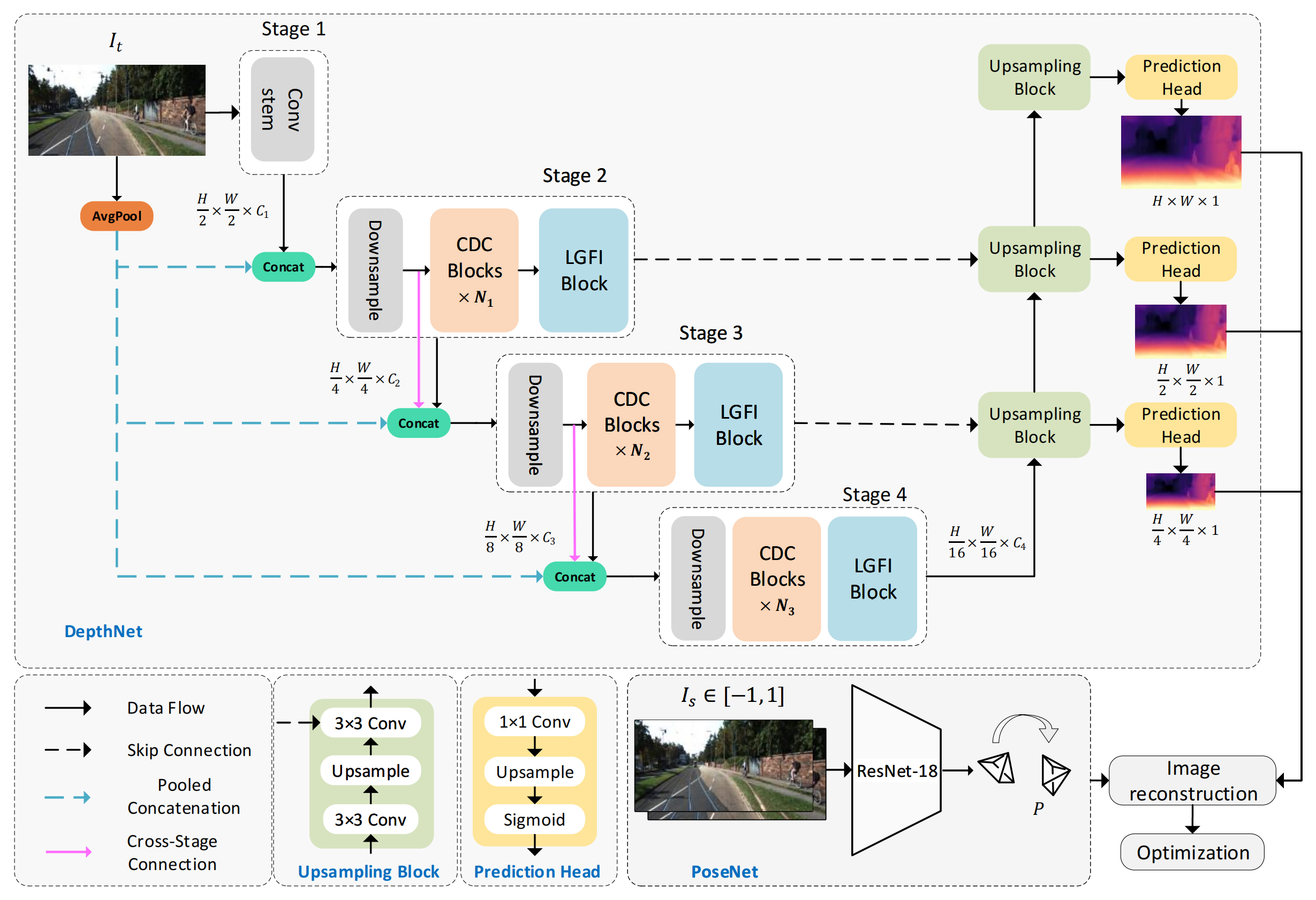
上图显示了Lite-Mono的体系结构。它由一个encoder-decoder DepthNet和一个PoseNet组成。DepthNet估计输入图像的多尺度深度图,而PoseNet估计两个相邻帧之间的摄像机运动。然后,生成一个重建的目标图像,并计算损失以优化模型。
Low-computation global information
DepthNet
Depth encoder
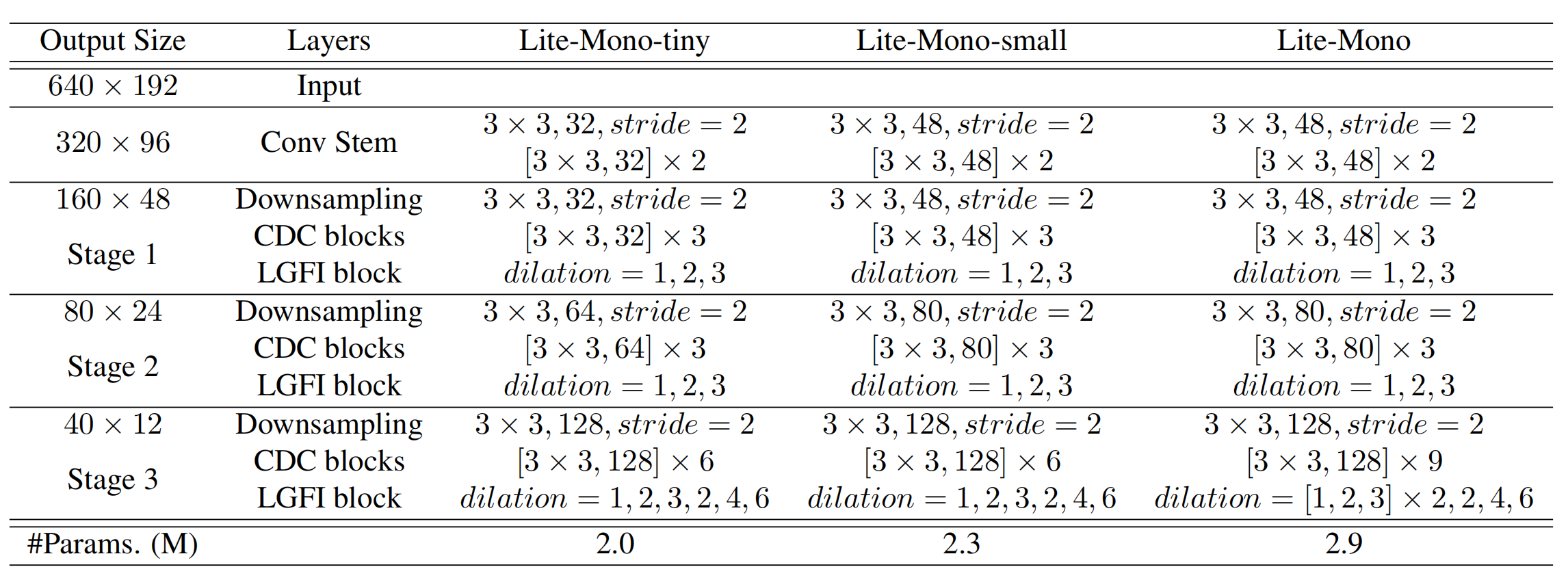
上图显示了本文提出的depth encoder的不同变体,Lite-Mono聚合了四个阶段的多尺度特征, [ 3 × 3 , C ] × N [3×3,C]×N [3×3,C]×N意味着一个CDC块使用3×3内核大小来输出C通道,并重复N次。
Consecutive Dilated Convolutions (CDC)
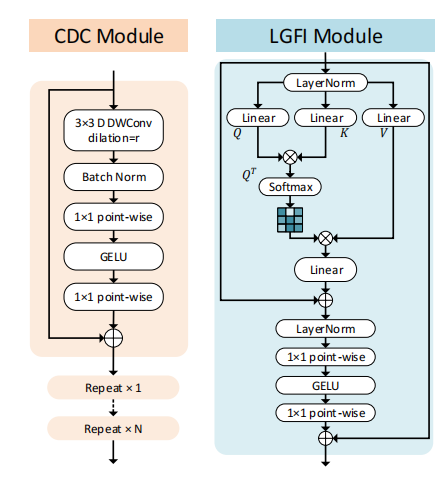
浅层CNN的感受域非常有限,而使用扩张卷积有助于扩大感受域。如上图所示,通过叠加所提出的连续扩张卷积(CDC),网络能够在更大的区域内“观察”输入,而不引入额外的训练参数。
论文所提出的CDC模块利用扩张卷积来提取多尺度的局部特征,在每个阶段插入几个具有不同扩张率的连续扩张卷积,以实现足够的多尺度上下文聚合.
Local-Global Features Interaction (LGFI)
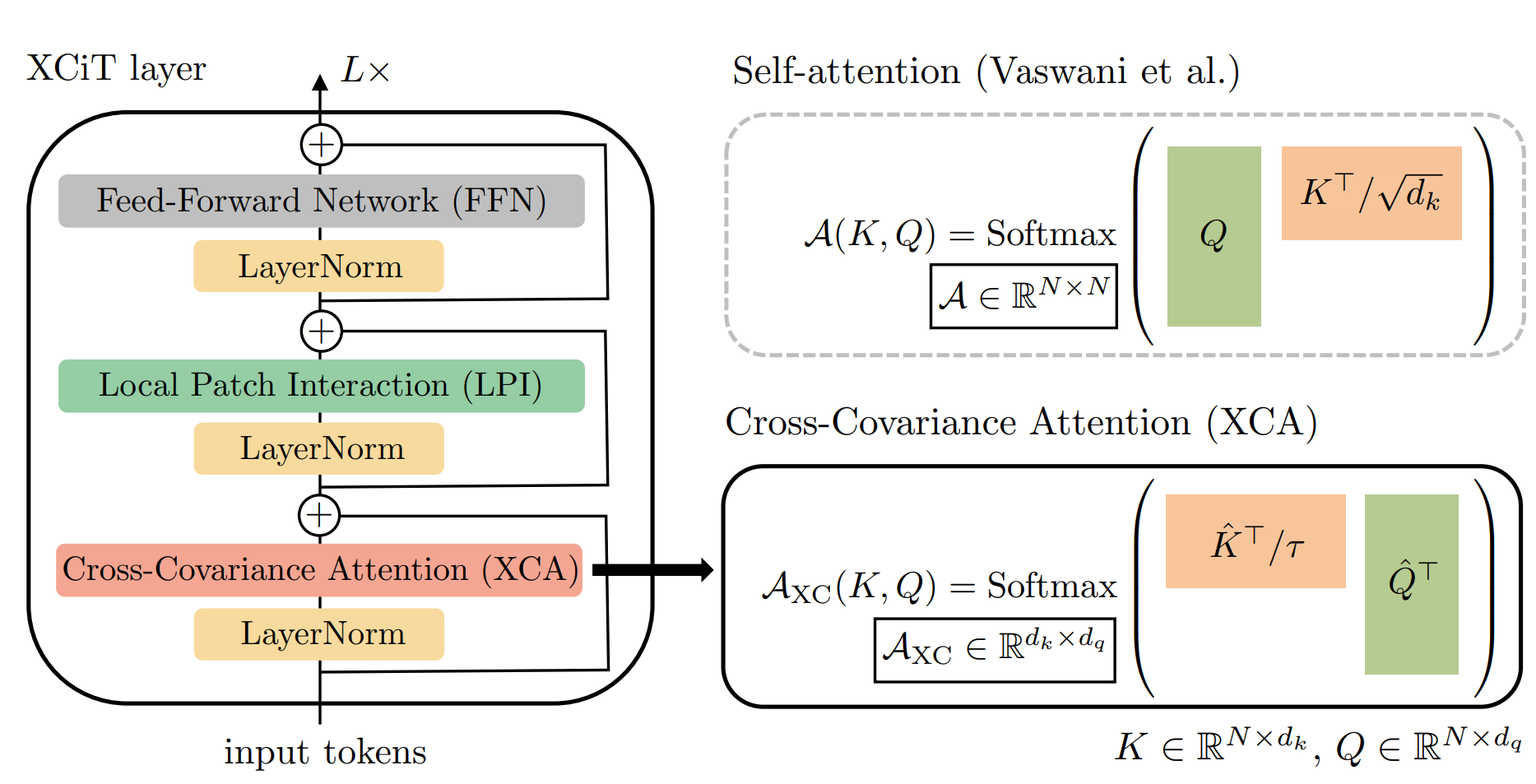
论文选用Transformer进一步增强全局信息。但是原始的Transformer中的Attention是每个特征间做自相关,因此复杂度与特征数量的平方成正比,这样做会对使大图片显存消耗翻倍增加。论文所提出的局部-全局特征交互(LGFI)模块参照XCiT的做法,不计算跨token的注意力,而是计算跨特征通道的注意力,其中交互基于K和Q之间的交叉协方差矩阵,称为互协方差注意力(XCA,cross-covariance attention):


如上面的LGFI示意图所示,与原始的自注意力相比,它将空间复杂度从 O ( h N 2 + N d ) \mathcal{O}\left(h N^2+N d\right) O(hN2+Nd)降低到 O ( d 2 / h + N d ) \mathcal{O}\left(d^2/h+N d\right) O(d2/h+Nd),时间复杂度从 O ( N 2 d ) \mathcal{O}\left(N^2 d\right) O(N2d)降低到到 O ( N d 2 / h ) \mathcal{O}\left(N d^2/h\right) O(Nd2/h),其中 h h h为注意头数量。
Depth decoder
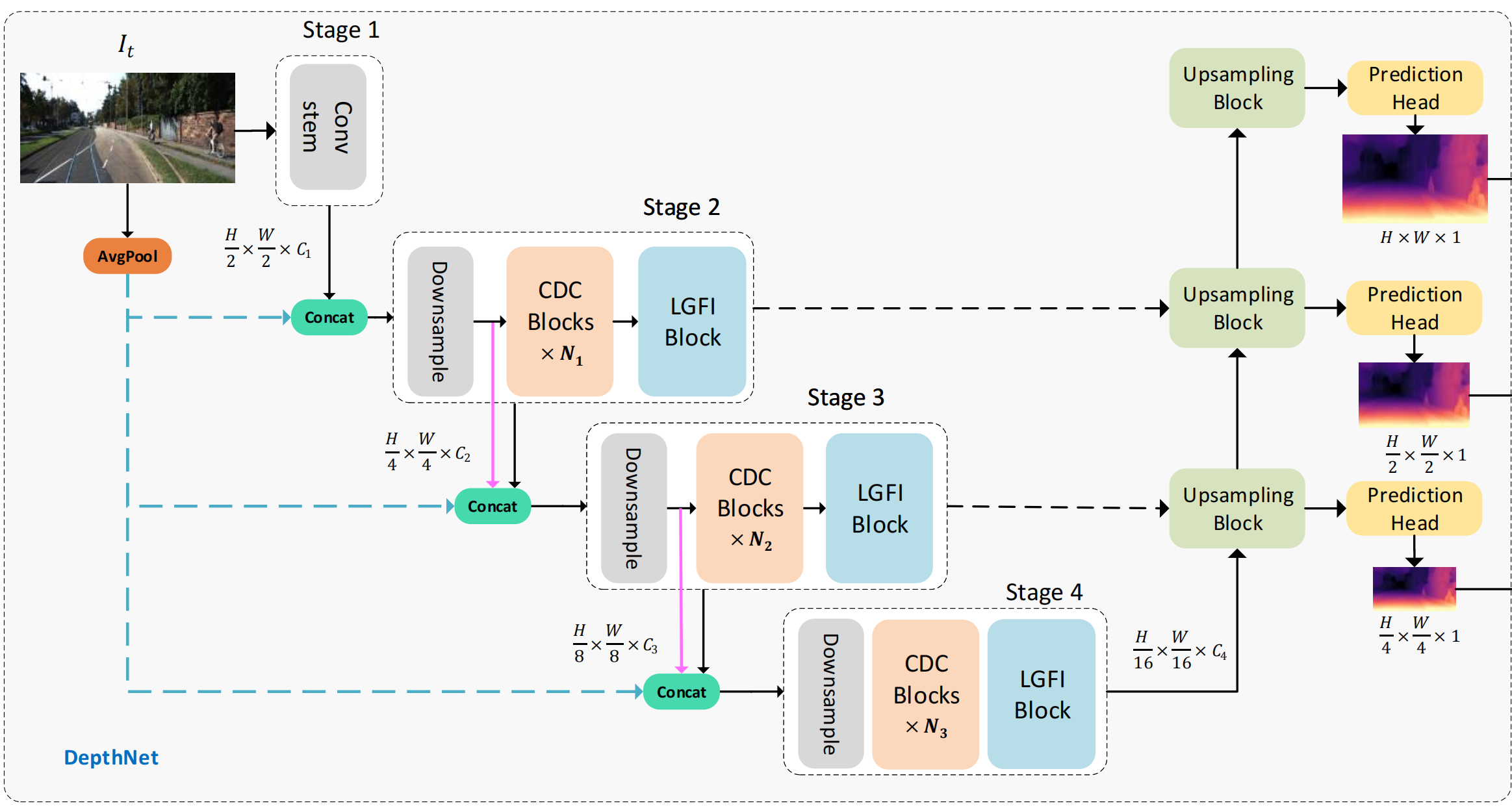
深度解码器部分,论文使用双线性上采样来增加空间维度,并使用卷积层来连接来自编码器的三个阶段的特征。每个上采样块跟着一个预测头,分别以全分辨率、 1 / 2 1/2 1/2 和 1 / 4 1/4 1/4的分辨率输出逆深度图。
PoseNet
论文使用一个预先训练过的ResNet18被用作姿态编码器,并且它接收一对彩色图像作为输入。利用具有四个卷积层的姿态解码器来估计相邻图像之间对应的6自由度相对姿态
Self-supervised learning
论文使用单目深度估计任务中常见的方法:将深度估计任务转换为图像重建的任务,学习目标被建模为最小化目标图像 I t I_t It与重构目标图像 I ^ t \hat{I}_t I^t之间的图像重建损失 L r \mathcal{L}_{r} Lr,以及约束在预测深度图上的边缘感知平滑损失 L s m o o t h \mathcal{L}_{smooth} Lsmooth。
Image reconstruction loss
光度重投影损失的定义为:

上面公式相当于两个相机坐标系下的转换,即源图像 I ^ s \hat{I}_s I^s(一般为前后帧)先用内参的逆转换到它的相机坐标系,再用旋转平移矩阵转到目标图像相机坐标系,再用内参转到目标图像的图像坐标系得到重构的目标图像,计算目标图像和重构目标图像之间的损失:

Edge-aware smoothness loss
为了平滑生成的逆深度图,论文计算一个边缘感知的平滑损失:

其中 d t ∗ = d t / d ^ t d_{t}^{*}=d_{t} / \hat{d}_{t} dt∗=dt/d^t表示mean-normalized的逆深度。总损失可表示为:

其中s为深度解码器输出的不同比例输出。
实验
KITTI results
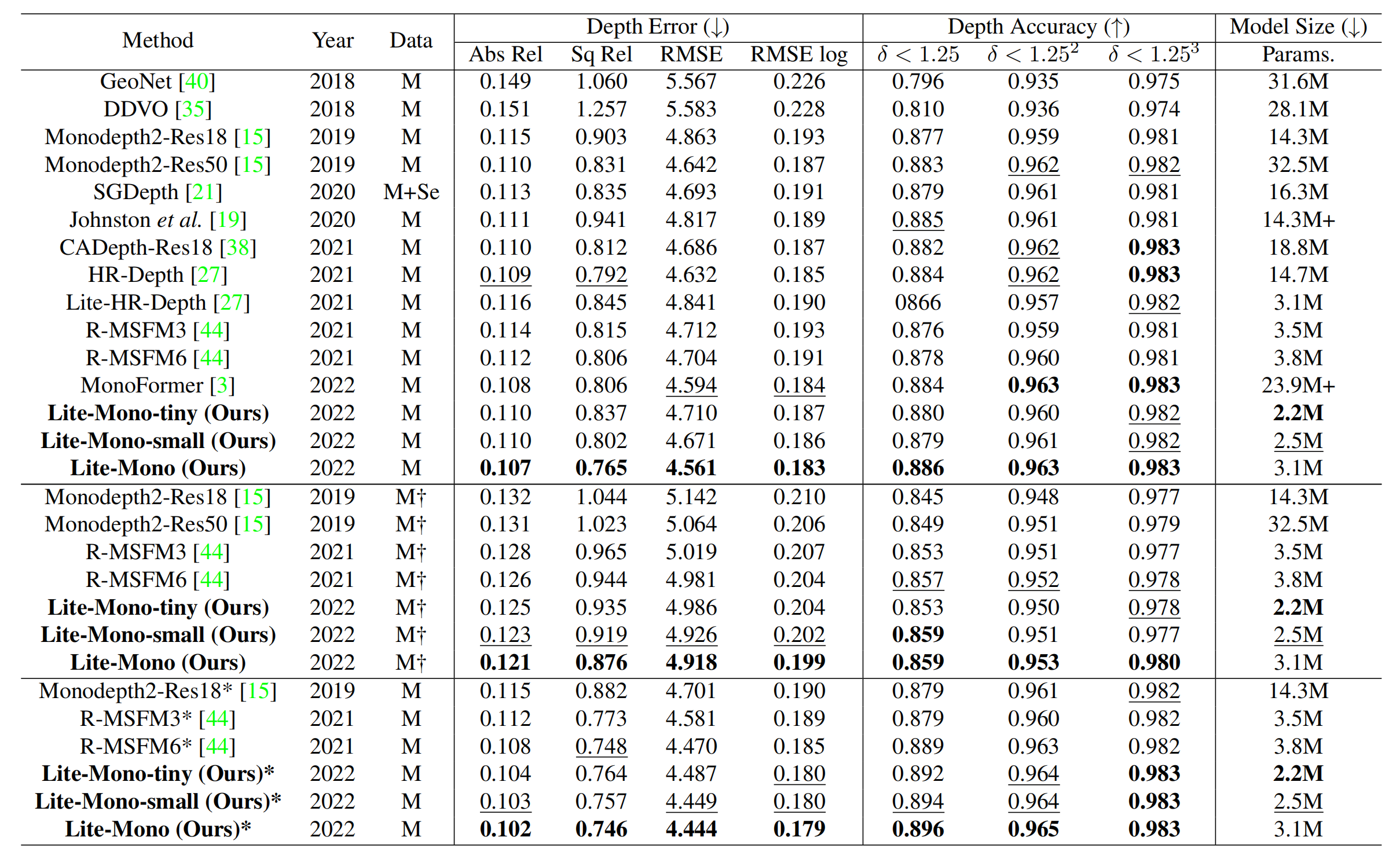
论文将所提出的框架与其他模型尺寸小于35M的代表性方法在KITTI benchmark进行了比较,结果如表2所示。完整模型的Lite-Mono效果最好,论文的其他两个较小的模型也取得了令人满意的结果。
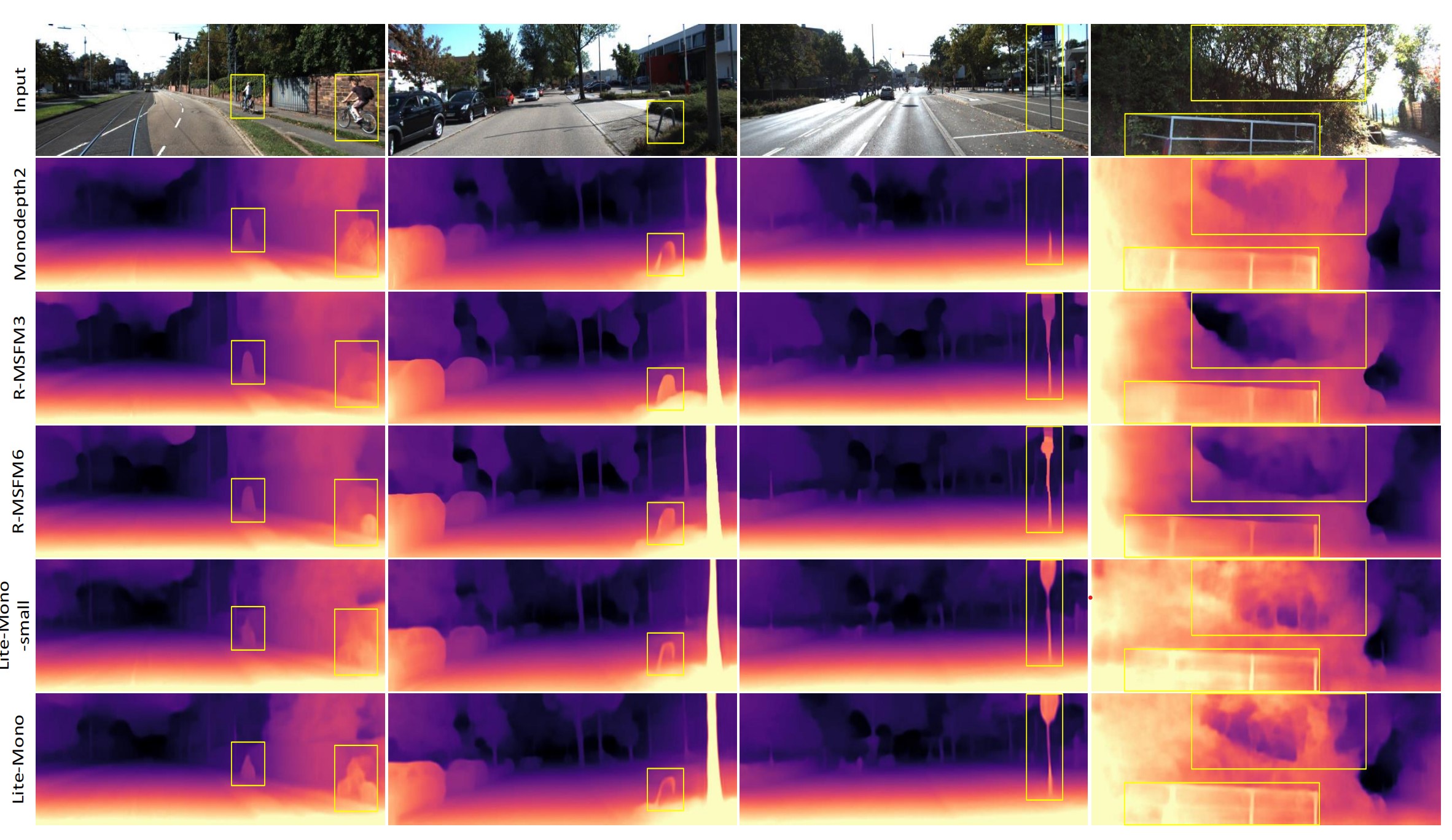
上图显示,所提出的Lite-Mono取得了令人满意的结果,即使是在移动物体靠近相机的具有挑战性的图像上(列1)。
Make3D results
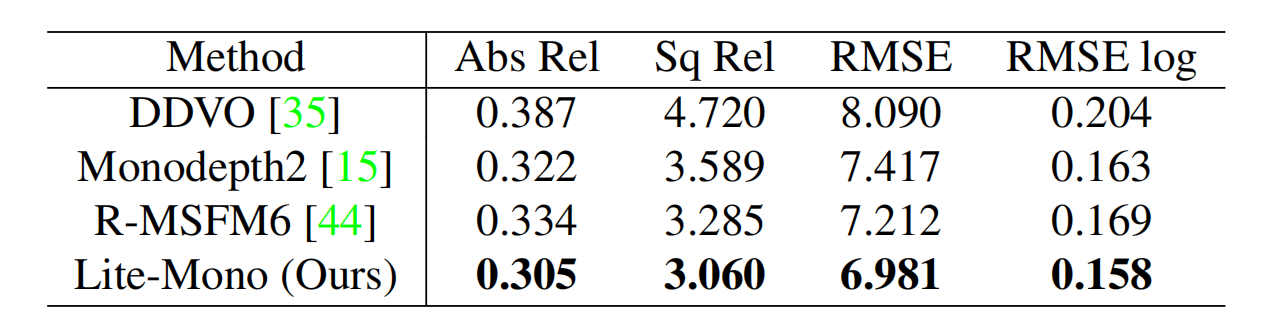
论文还在Make3D数据集上进行了评估,以显示所提方法在不同室外场景中的泛化能力。表3显示了Lite-Mono与其他三种方法的比较,其中Lite-Mono表现最好。

上图显示了一些定性的结果。由于所提出的特征提取模块,Lite-Mono能够建模局部和全局上下文,并感知不同大小的对象。
Complexity and speed evaluation

论文在Nvidia Titan XP和Jetson Xavier上对该模型的参数、FLOPs(浮点运算)和推理时间进行了评估,并与Monodepth2和R-MSFM进行了比较。表4显示,Lite-Mono设计在模型尺寸和速度之间有很好的平衡。虽然R-MSFM是一个轻量级的模型,但它是最慢的。论文的模型还可以在Jetson Xavier快速推理,这使得将它们部署在边缘设备上成为可能。
消融实验

论文删除或调整了网络中的一些模块来进行消融实验,并在KITTI上报告了它们的结果,如表5所示。
总结
本文提出了一种新的轻量级单目自监督单目深度估计方法。设计了一种混合的CNN和Transformer架构来建模多尺度增强的局部特征和全局上下文信息。在8个KITTI数据集上的实验结果证明了该方法的优越性。通过在提出的CDC块中设置优化的扩张率,并插入LGFI模块来获得局部-全局特征相关性,Lite-Mono可以感知不同尺度的物体,甚至是对靠近摄像机的移动物体。论文还验证了该模型在Make3D数据集上的泛化能力。此外,Lite-Mono在模型复杂性和推理速度之间实现了良好的权衡。
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!