我们正在见证感知模型的巨大进步,特别是在大规模互联网图像上训练的模型。 然而如何有效地将这些感知模型推广到具身环境的研究还远远不够,这些研究将有助于推进各种相关应用(例如家用机器人)的发展。为了使用尽可能少的标注,有效地收集具身场景中的训练数据成为该任务的主要挑战。
与基于固定数据集的视觉学习不同,具身代理可以在虚拟/真实的3D空间中移动并与环境交互。此外,不像静态感知模型那样将每一个训练样本单独处理,代理在空间中移动时可以从不同的视角对同一个物体进行观测。因此,有效地收集训练样本意味着需要学习一种探索策略,来鼓励代理探索预训练模型表现不佳的区域。
字节跳动的研究者提出了一种新的具身感知中探索信息丰富的轨迹的方法。它通过引入语义分布不一致性和语义分布不确定性奖励来训练探索策略。此外,它通过语义分布不确定性在所学到的轨迹上选择难样本,这可以进一步筛选预训练模型识别良好的样本。实验结果表明,所提出的方法在具有挑战性的Matterport数据集上取得了最好的结果,在真机实验中也证明了该方法的稳健性。


一、算法介绍
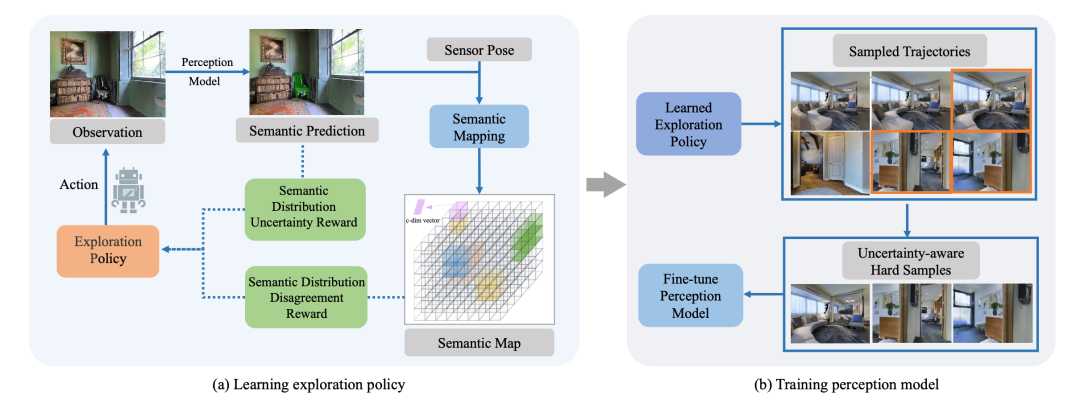
学习的目标是训练拥有在互联网图像上预训练过的感知模型的具身代理去有效地探索信息丰富的轨迹和样本,然后针对收集到的数据微调感知模型,使其可以很好地应用到新环境中。如上图所示,模型主要包括两部分,探索部分旨在利用3D语义分布图,以自监督的方式通过语义分布不一致性和不确定性来学习探索轨迹。此外,对学习到轨迹利用不确定性来收集轨迹上的难样本。对收集到的图像进行语义标注后,在感知学习阶段微调感知模型。
3D语义分布建图
在每个时间步,代理的观测空间包含一个RGB观测图像、一个深度图像和一个三自由度传感器姿态。上图左显示了一个时间步长的语义映射过程,对于观测到的图像,使用预训练过的感知模型(例如:Mask RCNN)来预测其中看到的对象的语义类别。然后使用深度观测去计算点云,点云中的每个点都对应相应的语义预测,然后使用基于传感器位姿的可微几何变换将其转换到3D空间来获得体素表示,随后使用指数移动平均来聚合随着时间变化同一位置的体素表示,从而得到3D语义分布图。
探索信息丰富的轨迹
该工作提出了两种基于分布的奖励方式,语义分布不一致奖励被定义为当前预测与3D语义分布图之间的KL散度,它鼓励机器人不仅探索新对象而且探索跨视角具有不同预测的对象。语义不确定性奖励鼓励代理去探索预测为两个类别的置信度比较接近的对象。
二、实验结果
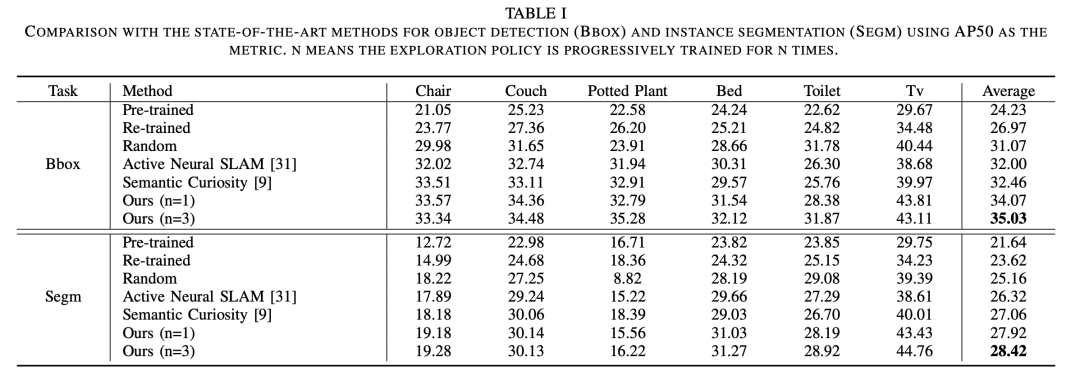
该研究工作在基于Habitat模拟器的Matterport3D数据集上进行了广泛的实验。实验结果表明所提出的模型在具身检测和分割上都优于以前最先进的方法。
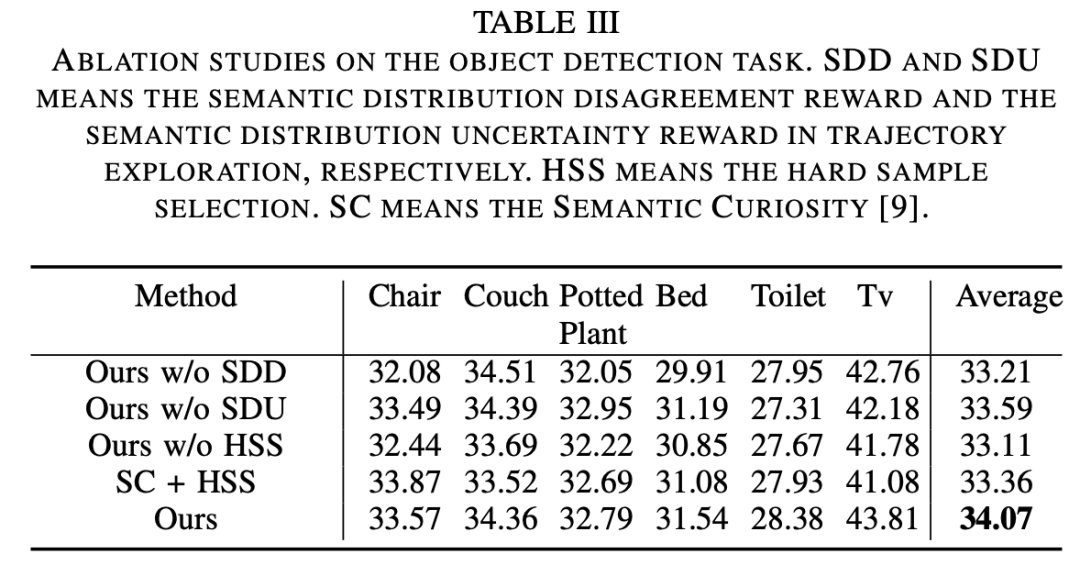
消融实验结果如上表所示,可以发现,跨视角的语义分布不一致性和语义分布不确定性都有助于探索策略的学习;基于语义分布不确定性筛选的难样本可以更有效地微调模型;通过基于最新微调过的感知模型迭代训练探索策略,性能可以进一步提升。

为了验证所提出的探索策略和难样本选择方法是否可以收集到具有不一致或不确定语义分布的观测图像,该工作从 Matterport3D数据集和真实环境中可视化了探索的轨迹和采样的图像。可以发现,第一行中沙发被检测为不同的对象(椅子/沙发),此外机器人从不同视角观测到不同的分布。第二行中,沙发被检测为沙发和椅子的得分几乎接近。通过收集这些预训练感知模型难以识别的观测图像并进行标注,可以更好地微调模型。
参考文献
[1] Chaplot D S, Dalal M, Gupta S, et al. Seal: Self-supervised embodied active learning using exploration and 3d consistency[J]. Advances in neural information processing systems, 2021, 34: 13086-13098.
[2] Chaplot D S, Jiang H, Gupta S, et al. Semantic curiosity for active visual learning[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16. Springer International Publishing, 2020: 309-326.
[3] Chaplot D S, Gandhi D P, Gupta A, et al. Object goal navigation using goal-oriented semantic exploration[J]. Advances in Neural Information Processing Systems, 2020, 33: 4247-4258.
[4] Fang Z, Jain A, Sarch G, et al. Move to see better: Self-improving embodied object detection[J]. arXiv preprint arXiv:2012.00057, 2020.
作者:Ya Jing
Illustration by IconScout Store from IconScout
-TheEnd-