缓存穿透
问题:
指的是客户端请求的数据在缓存中找不到,数据库中也没有存储,客户端还不断的发起请求。这样每次都无法在数据库查询到,缓存中永远没有这个数据。
这样的话,客户端一直去访问,会给后端数据库带来很大压力。
解决方案:
方案一:将空值存储到redis中
在查询数据库后,将该用户存储到redis中,值存储一个null值,这样下一次这个用户再来访问直接从redis中返回即可。但是为了不让这些没意义的数据一直存在占用内存,将有效时间设置短点。
- 优点:实现简单,维护方便
- 缺点:
- 会占用更多的内存消耗
- 造成短期的不一致
if ("数据" == null) { // 如果数据库中不存在 返回错误信息 存储到redis中 value设置为null,有效时间设置短点 防止出现缓存穿透两分钟 String key = "用户id"; stringRedisTemplate.opsForValue().set(key,"",2L,TimeUnit.MINUTES); }// 判断缓存是否为"" 直接返回 if ("".equals("数据")) { return "数据错误"; }
方案二:使用布隆过滤器
客户端每次发送请求,先去布隆过滤器中查询是否有没有这个数据,如果有直接返回,没有则去redis中查找。依次类推。
这个布隆过滤器复制了mysql中类似于字节的数据,所以可能出现过滤误判的情况,导致缓存穿透
- 优点:内存占用少,没有多余的key
- 缺点:
- 实现起来比较复杂
- 存在误判操作
其他方案:
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验

缓存雪崩
问题:
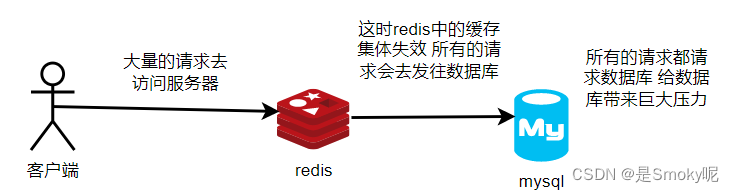
指的是大量缓存集中在一个时间段失效或者redis服务宕机,从而大量请求去访问数据库,带来巨大压力。
缓存集体失效:
缓存服务器宕机:
这种情况比较严重
解决方案:
在每个缓存的失效时间上增加一个随机值,这样缓存的失效时间的重复率就会降低,很难再次引起缓存集体失效的事件。【不能解决缓存服务器宕机】
其他方案:
- 搭建redis集群,提高服务的可用性
- 一台宕机后,其他机器继续提供服务
- 给缓存业务添加降级限流策略
- 限制请求的并发数量
- 给业务添加多级缓存
- 添加多个缓存,减少访问数据库的频率

缓存击穿
问题:
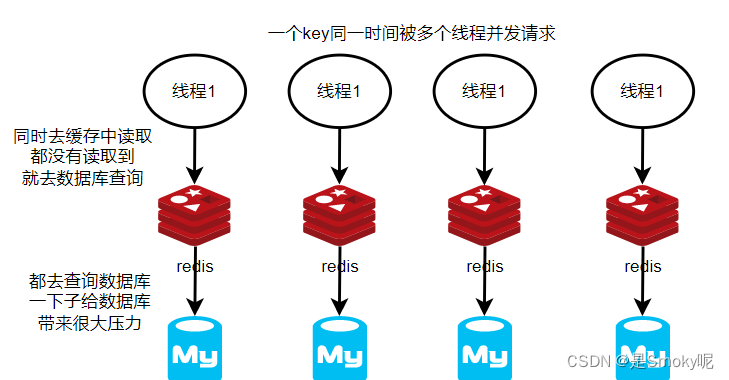
对于缓存击穿也可以理解为热点key问题,就是一个被高并发访问而且缓存重建业务比较复杂的key突然失效(缓存中没有 数据库中有的数据),这时会有无数的请求访问数据库,造成数据库巨大压力。
解决方案:
方案一:互斥锁【加锁机制】
多个线程并发访问时,先拿到的锁先去查询数据库,别的线程需要等待【定时发起重试】,为了保证最后因为某种原因释放锁失败,所以在重建抢夺锁的时候,给锁设置一个有效期,做兜底方案。
- 优点:
- 没有额外的内存消耗
- 保证了数据的一致性
- 实现起来简单
- 缺点:
- 没有抢到锁的线程需要等待,性能受影响
- 可能发生死锁
锁逻辑:
// 获取锁 private boolean tryLock(String key){ Boolean isLock = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10L, TimeUnit.SECONDS); return BooleanUtil.isTrue(isLock); } // 释放锁 private void unLock(String key){ stringRedisTemplate.delete(key); }业务逻辑:
// 尝试获取到互斥锁 String lockKey = "lock:"+id; boolean tryLock = tryLock(lockKey); // 判断是否获取到锁 try { if (!tryLock) { // 没有拿到锁 Thread.sleep(50); return queryShopWithBreakdown(id); } // 拿到锁 // 再次判断缓存中是否有数据,防止别的线程中途重建 String key = stringRedisTemplate.opsForValue().get(key); if (StrUtil.isNotBlank(key)){ // 如果有数据直接返回 不需要重建 return JSONUtil.toBean(key,User.class); } // 不存在查询数据库 user = getById(id); // 防止后面线程抢先 Thread.sleep(500); if (user == null) { return null; } // 将返回结果存入redis中 设置有效期30分钟 stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(user),30L,TimeUnit.MINUTES); } catch (InterruptedException e) { throw new RuntimeException(e); }finally { // 释放锁,中途发生异常也需要释放 unLock(lockKey); } // 返回数据 return user;

方案二:逻辑失效【热点数据】
使用逻辑失效时间,并不是TTL,是当前时间和过期时间相加得来。如果当前时间大于过期时间,就证明数据已过期,需要去更新缓存。同样需要抢夺互斥锁,但是抢夺不到的直接返回之前的数据,不会等待。抢夺到的开启一个新的线程负责更新缓存并重置过期时间,最后释放锁。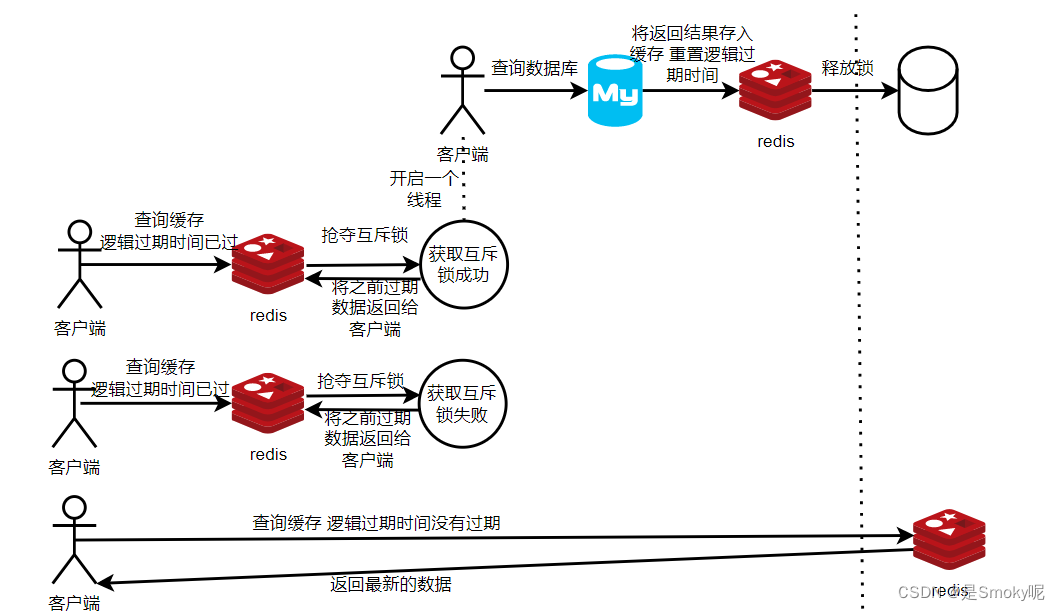
- 优点:线程无需等待,性能较好
- 缺点:
- 数据短时间不能保证一致
- 有额外的内存消耗
- 实现起来比较复杂
重建方法:
public void saveRedis(Long id,Long expire){
// 从数据库查询
User user = getById(id);
RedisData redisData = new RedisData();
redisData.setData(user);
// 当前时间和过期时间相加
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expire));
// 添加到缓存
stringRedisTemplate.opsForValue().set(key+id,JSONUtil.toJsonStr(redisData));
}业务逻辑:
// 判断缓存是否过期
RedisData redisdata = JSONUtil.toBean(userJson, RedisData.class);
JSONObject data = (JSONObject)redisdata.getData();
user = JSONUtil.toBean(data, User.class);
LocalDateTime expireTime = redisdata.getExpireTime();
// 过期时间是否在当前时间后面
if (expireTime.isAfter(LocalDateTime.now())){
// 没过期
return shop;
}
// 过期
// 尝试获取锁
String lockKey = "lock:"+id;
boolean isLock = tryLock(lockKey);
if (!isLock){
// 没有拿到锁 直接将之前过期数据返回
return shop;
}
try {
// 拿到锁 开启一个线程
new Thread(new Runnable() {
@Override
public void run() {
// 重建缓存
saveShop2Redis(id,20L);
}
}).start();
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
unLock(lockKey);
}
// 返回数据
return shop;