前言
在web应用开发中,redis越来越多的应用于各种需要缓存的场景中,比较经典的使用场景就是,使用redis配合mysql做二级缓存,以应对在流量高峰的时候,减少高并发请求对数据库的压力
但是在这种简单的架构模式下,如果使用不慎,或者对某些问题没有做到提前的预判,在高并发或者某些特殊场景下,可能会出现缓存穿透,缓存击穿或雪崩的现象
缓存穿透
请求查询时,key对应的数据在数据源中不存在,从而每次请求的key从缓存中获取不到,请求都会直接打到数据库,当这种请求的量特别大的时候,可能会压垮数据源
举例来说,用一个不存在的用户id获取用户信息,无论缓存还是数据库都不存在,不法分子利用此漏洞进行数据库攻击可能压垮数据库
缓存穿透过程中表现的现象:
- 系统处于平稳运行过程中
- 应用服务器流量随着时间呈现增量增加
- Redis服务器的缓存命中率随着时间不断降低
- Redis内存平稳,内存无较大压力
- Redis服务器的CPU占用一段时间内激增
- 数据库服务器压力激增
- 数据库崩溃
问题排查
- redis中出现大量的key未命中现象
- 出现较多的非正常URL请求
原因分析
- 获取的数据在数据库中不存在,redis中也未缓存
- Redis获取到数据库中为null的数据未进行持久化,直接返沪
- 以后的请求不断重复上面的过程
- 可能出现大量的非法请求或者出现黑客攻击
常用的解决方案
1、缓存null
- 对查询结果为null的数据进行缓存(长期使用,定期清理),设定较短的期限,比如30~60秒,最高5分钟
- 问题:一定程度上可以解决缓存穿透的问题,但是一旦无效的请求量太大,瞬间对redis服务器的内存消耗太大,可能会撑爆内存,可作为一个临时的解决方案,不是非常有效的方案
2、白名单策略
- 提前预热各种分类数据id对应的bitmaps,比如可以将id作为bitmaps的一个offset,相当于给数据设置了白名单,正常访问的时候,请求通过,加载异常时候对请求进行拦截
- 使用布隆过滤器(可以快速过滤不存在的key,可能存在缓存命中率的问题)
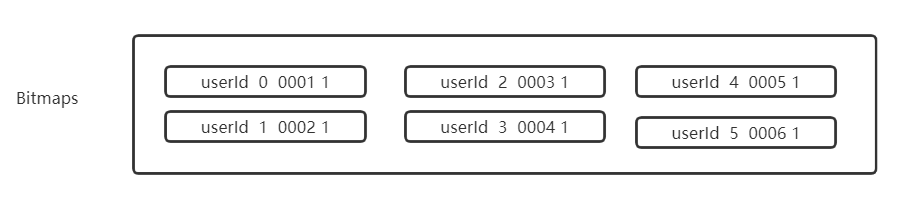
如上图所示,在bitmaps的结构中,提前预热了所有用户ID的信息,当访问的数据经过拦截器时,可以直接从bitmaps中进行加载,根据返回的数据状态(1或0)进行判断是否拦截,但是可能带来效率的问题,毕竟每次的请求都要经过过滤器的处理
3、数据监控
利用工具或借助其他中间件对redis命中率进行监控,与业务正常范围内的命中率标准进行对比
- 非活动时段(业务平稳时间端)波动率,通常检测标准,3~5倍,超过5倍时纳入重点排查对象
- 活动时段(业务活跃时间端)波动率,通常检测标准10~50倍,超过50倍时纳入重点排查对象
- 根据不同时间段的倍数不同,启动不同的排查流程,然后使用黑名单策略进行防控
4、key加密
对请求的key进行业务层传输加密,设定相应的校验程序,对请求过来的key校验,比如每日随机分配一定数量的加密串,随机挑选几个业务key进行加密处理并混淆到原本的页面数据中,再次发现访问的key不符合规则时,驳回访问的请求
缓存击穿
key对应的数据存在,但是在redis中过期,此时若有大量的并发请求过来,这些请求发现缓存过期一般都会从数据库的DB中加载数据并重新设置到缓存中,这些大并发的请求可能瞬间会把数据库压垮
一句话总结就是:查询到了key,但是过期,大量并发打到数据库进行频繁查询
缓存击穿过程中表现的现象:
- 系统平稳处于运行过程中
- 数据库连接量瞬间激增
- Redis服务器无大量key过期(部分或个别key有过期)
- Redis内存平稳,无较大波动
- Redis服务器CPU运行正常
- 数据库崩溃
问题排查:
- Redis中存在某个key过期,而且该key某个时间点访问量巨大
- 多个请求到达redis后,均未命中
- Redis在短时间内发起了大量的对数据库中同一数据的访问
原因分析:
- 单个key为高热数据
- key过期
常用解决方案:
- 高热key预先设定并加大缓存时间
比如在双11抢购期间,提前对某些促销商品,将其缓存过期时间加大,一般来说,这个时间可以根据历年经验,设置超过秒杀时间的5~10倍,以便应对访问峰值之后逐渐降低的趋势
- 根据监控指标临时调整
利用某些指标监控工具,对那些自然流量激增的缓存数据适当延长过期时间或设置为永久key
- 定时任务定时刷新热点key
后台启动定时任务,在高峰期来临之前或之后的某段时间里,刷新缓存数据有效期,确保不丢失
- 设置二级缓存
如果应用中,某个功能中的较多业务链条上的数据都放在缓存中,注意设置不同的key的过期时间不同,确保这些缓存不会同时过期
加锁
具体的业务逻辑想必大家都遇见过,比如先查redis再查库,然后设置到缓存,单机下这样没问题,分布式环境下高并发请求过来时,采用分布式锁,但是加锁一定程度上会带来性能问题,需要取舍
缓存雪崩
当缓存服务器重启,或者大量缓存集中在某一个时间段内失效,在失效的期间,如果大量的请求过来,会给数据库带来较大的压力,甚至压垮数据库
与缓存击穿不同的是,缓存雪崩针对多个key过期
表现现象
- 系统平稳运行过程中,数据库连接量突然激增
- 应用服务器无法及时处理大量的请求,造成大量的408或500
- 客户端反复刷新页面获取数据
- 应用服务器崩溃,数据库崩溃,重启应用服务器无效
- Redis服务器崩溃,Redis集群崩溃
- 重启数据库后,可能再次瞬间被大量的请求放倒
问题排查
- 较短时间范围内,缓存中出现较多的key集中过期
- 在此时间范围内,大量请求访问过期的数据,reids未命中,请求打到后端数据库
- 数据库同时接收到大量的请求而无法及时处理,甚至造成数据库的连接耗尽而宕机
- Redis大量请求被积压,一旦处理不过来,开始出现超时现象
- 数据库崩溃之后,再次重启,面对缓存中无缓存数据可用,重启依然无效
- Redis服务器资源被严重占用,导致整个集群资源也逐渐耗尽而崩掉
- 应用服务器无法及时响应请求,导致挤压的请求数量越来越多,最后将应用服务器也拖垮
总结一句话就是,在较短的时间范围内,大量的缓存key过期
常用解决方案
-
页面静态化处理
页面静态化可以抵挡一部分高峰流量,比如电商业务中的详情页面的某些不经常变化的商品介绍数据即可使用静态化方案,可以作为多级缓存架构中的第一级
-
构建多级缓存架构
Nginx + Ehcache + Redis 三级缓存,三级缓存架构是很多并发量较高的互联网公司的标配方案
-
通过监测工具检测mysql中那些比较耗时的业务并优化处理
慢sql日志分析,超时查询,耗时较高的事务性操作等,检测出来之后及时处理
-
设定灾难预警机制
对Redis服务器性能指标进行监控,可以参考如下指标:
1、CPU使用率,CPU占用 2、内存容量是否比平时拉高 3、单次查询平均耗时是否拉高 4、线程数统计是否拉高 -
采用限流,降级
短时间范围内,为确保整体系统可用性,限制一部分用户请求,降低和缓解服务器压力,待总体业务正常运转之后再逐步放开
-
调整key的过期策略
LRU与LFU切换,我们知道redis默认的缓存过期策略是LRU,假如某个业务链条上的多个数据都放在缓存中,如果都是同一时间段放入缓存的,很可能在业务高峰期时一旦这些缓存失效,就可能出现雪崩的情况,可以根据实际业务修改默认的LRU策略(根据访问频次)
-
key有效期策略调整
根据业务有效期对不同维度的数据进行分类错峰,比如用户类数据设置为7天,优惠券类数据设置为5天,订单类数据设置为1个月等
过期时间可以采用固定时间 + 随机值的形式,避免很多的key集中过期
- 超热的热点key设置为永久过期
对那些高频访问的key可以设置为永不过期
- key的定期维护
后台维护一个定时任务,对某些key的访问量进行分析,通过访问量统计对那些热点key进行自动的过期时间延时
- 加锁处理
这个和缓存击穿在程序处理中有类似的地方,可能带来的问题就是牺牲一部分性能,在高并发场景中需要慎重使用
以上就是本篇的全部内容,本篇总结了Redis穿透,击穿与雪崩中的常见问题分析并给出了一些基于实际处理经验的解决办法,希望对看到同学有用,本篇到此结束,最后感谢观看!