缓存处理流程
- 前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
redis雪崩
-
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
-
目前电商首页以及热点数据都会做缓存,一般缓存都会定时任务去刷新,或者是查不到之后去更新的,定时任务刷新就是一个问题。
- 举例 如果所有首页的失效时间都是12小时,中午12点刷新的,凌晨零点有一个秒杀活动,假设当时每秒6000个请求,本来缓存每秒可以抗住5000个请求,但是缓存当时所有key都已实效,此时每秒6000个请求全部落入mysql,数据库必然抗不住,它会报一下警,实际上可能DBA(数据库管理员)都没反应过来就挂了。此时,如果没用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。感觉再吊都不允许这么大的QPS(高并发)直接打DB去,不过设慢SQL加上分库,大表分表可能还算可以顶住,但是跟用来redis差距还是很大的。
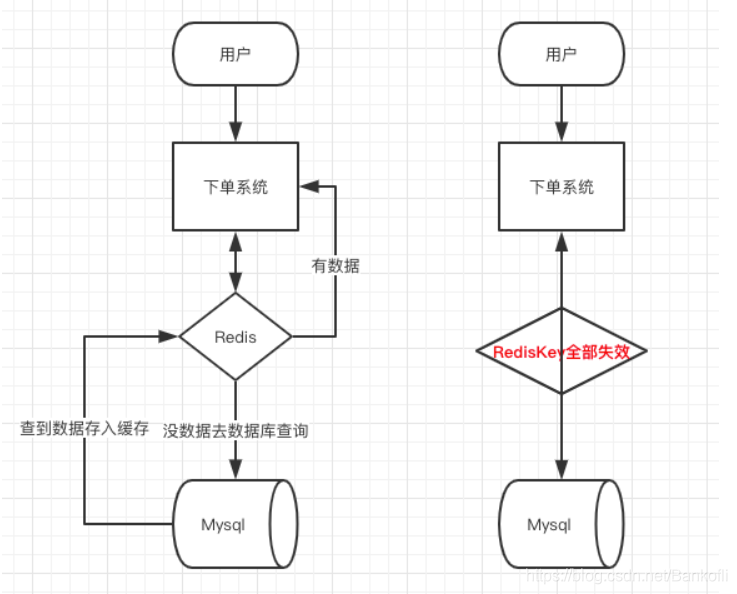
同一时间大面积失效,那一瞬间Redis跟没有一样,那这个数量级别的请求直接打到数据库几乎是灾难性的,你想想如果打挂的是一个用户服务的库,那其他依赖他的库所有的接口几乎都会报错,如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂,等你能重启的时候,用户早就睡觉去了,并且对你的产品失去了信心,什么垃圾产品。
- 举例 如果所有首页的失效时间都是12小时,中午12点刷新的,凌晨零点有一个秒杀活动,假设当时每秒6000个请求,本来缓存每秒可以抗住5000个请求,但是缓存当时所有key都已实效,此时每秒6000个请求全部落入mysql,数据库必然抗不住,它会报一下警,实际上可能DBA(数据库管理员)都没反应过来就挂了。此时,如果没用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。感觉再吊都不允许这么大的QPS(高并发)直接打DB去,不过设慢SQL加上分库,大表分表可能还算可以顶住,但是跟用来redis差距还是很大的。
-
解决方法:批量往存数据的时候,把每个Key的失效时间都加个随机值,这样可以保证数据不会在同一时间大面积失效,我相信,Redis这点流量还是顶得住的。
-
也可以用redis集群部署,缓解单个压力。
-
设置热点数据永远不过期,有更新操作就更新缓存就好了。
缓存穿透
- 缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
- 像这种你如果不对参数做校验,数据库id都是大于0的,我一直用小于0的参数去请求你,每次都能绕开Redis直接打到数据库,数据库也查不到,每次都这样,并发高点就容易崩掉了。
- 解决方法:接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截。
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
缓存击穿
- 缓存击穿,这个跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
- 解决方法:这样可以防止攻击用户反复用同一个id暴力攻击,但是我们要知道正常用户是不会在单秒内发起这么多次请求的,那网关层Nginx记得有配置项,可以让运维大大对单个IP每秒访问次数超出阈值的IP都拉黑。
扩展:
这里我想提的一点就是,我们在开发程序的时候都要有一颗“不信任”的心,就是不要相信任何调用方,比如你提供了API接口出去,你有这几个参数,那我觉得作为被调用方,任何可能的参数情况都应该被考虑到,做校验,因为你不相信调用你的人,你不知道他会传什么参数给你。
举个简单的例子,你这个接口是分页查询的,但是你没对分页参数的大小做限制,调用的人万一一口气查 Integer.MAX_VALUE 一次请求就要你几秒,多几个并发你不就挂了么?是公司同事调用还好大不了发现了改掉,但是如果是黑客或者竞争对手呢?在你双十一当天就调你这个接口会发生什么,就不用我说了吧。这是之前的Leader跟我说的,我觉得大家也都应该了解下。
