缓存雪崩
什么是缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。 由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都去查询数据库了,而对数据 库CPU和内存造成巨大压力,严重的会造成数据库宕机你有什么解决方案来防止缓存雪崩?
加锁排队
key: whiltList value:1000w个uid 指定setNx whiltList value nullValue mutex互斥锁解 决,Redis的SETNX去set一个mutex key, 当操作返回成功时,再进行load db的操作并回设缓存; 否则,就重试整个get缓存的方法数据预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在 用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的 缓存数据!可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触 发加载缓存不同的key双层缓存策略(很少使用)
C1为原始缓存,C2为拷贝缓存,C1失效时,可以访问C2,C1缓存失效时间设置为短期,C2设置为长期。 定时更新缓存策略失效性要求不高的缓存,容器启动初始化加载,采用定时任务更新或移除缓存 设置不同的过期时间,让缓存失效的时间点尽量均匀
缓存穿透(击穿)
什么是缓存穿透?
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到对应key的value,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次 无用 的查询)。这样请求就绕过缓存直接查数据库你有什么解决方案来防止缓存穿透?
采用布隆过滤器BloomFilter
将所有可能存在的数据哈 希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力缓存空值
如果一个查询返回的数据为空(不管是数据不存在,还是系统故障)我们仍然把这个空结果进行 缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存, 这样第二次到缓冲中获取就有值了,而不会继续访问数据库什么是布隆过滤器?
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。布隆过滤器为什么不使用HashMap?
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。 还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。布隆过滤器原理?
布隆过滤器是一个 bit 向量或者说 bit 数组。

当我们要映射一个值到布隆过滤器时,先通过多个不同的哈希函数生成多个哈希值,并把对应哈希值的位置设为1。如下:
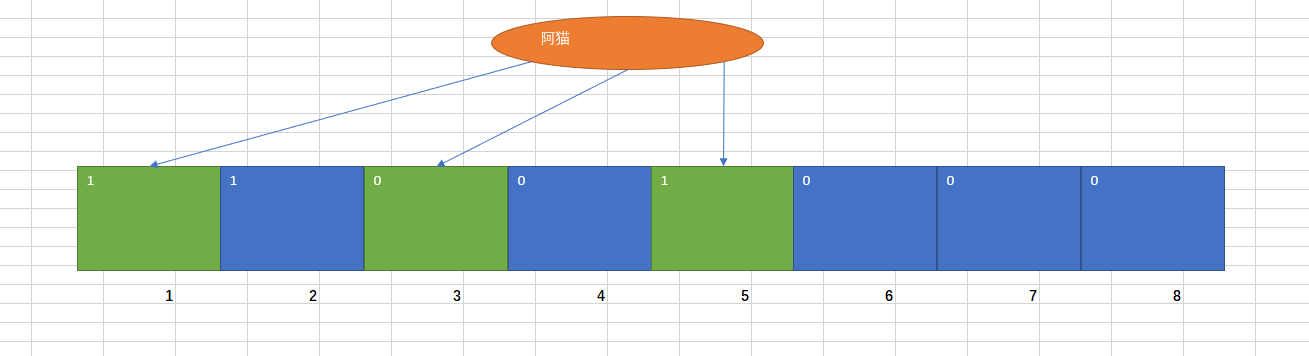
当我们再次映射一个值到布隆过滤器
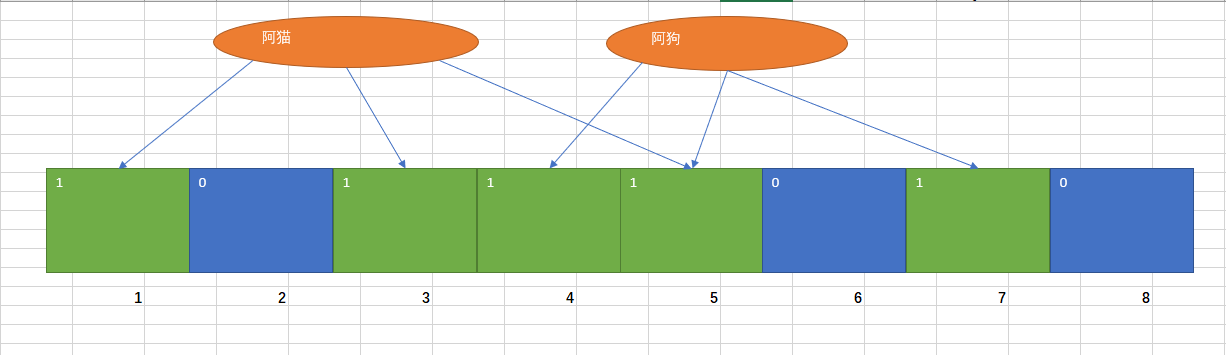
此时5这个位置被映射了两次,此时假设当我们查询“阿猪”这个值是否存在,返回了4、5、6三个值,结果6这个位置没有被映射过,所以可判定“一定不存在”;再假设我们查询“阿鸡”,返回了3、4、5三个值,此时也不可以判断为存在,只能说明“可能存在”。