一.基本概念
进程(process)一个正在被执行的计算机程序的实例
上下文(context):待处理数据的集合,允许处理器暂停,保持处理的执行和恢复处理
并发:上下文切换,主要应用于单核处理器,循环赛
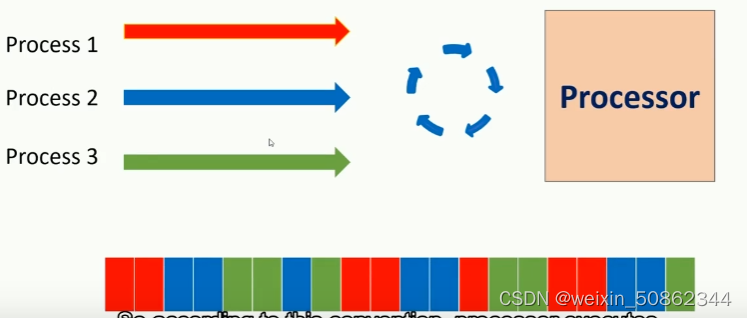
并行:多线程执行
二.第一个cuda
2.1cuda安装
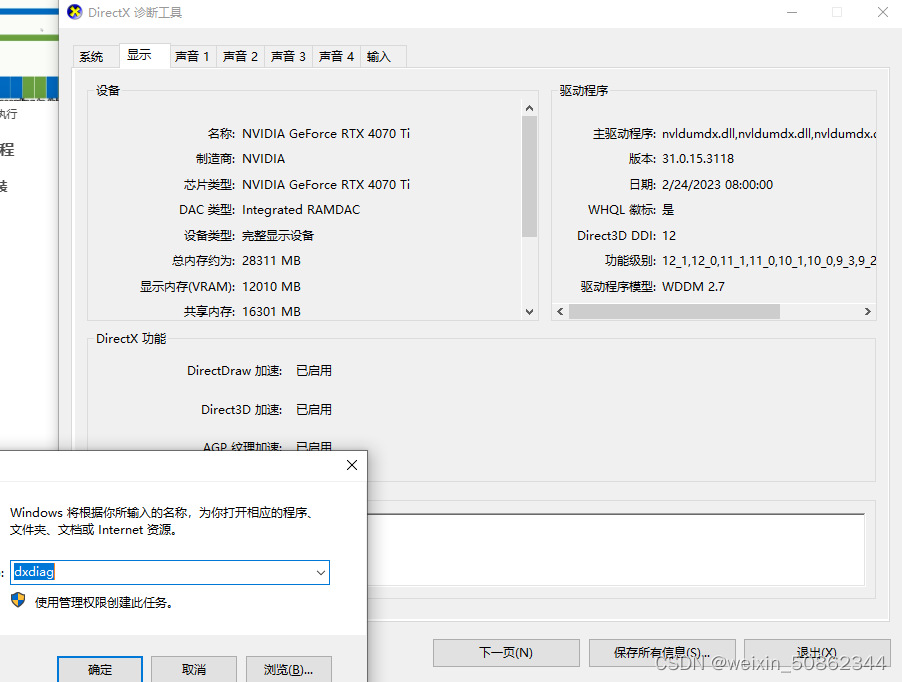
了解自己电脑的微架构和算力,下载对应版本cuda
p.s.这部分网上有大量教程
2.2 第一个cuda
2.2.1 在visual studio 配置cuda 模板
大致可以参考这一博客
但是我是先安装cuda,在安装vs,因此配置完好像也没有成功。我尝试了所有不重装cuda的方式都失败了,重新安装cuda
三.cuda编程的基本步骤
host code :在cpu上运行的代码
device code : 在gpu上运行的代码
3.1 一个简单示范程序
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void hello_Cuda()
{
printf(
"hello CUDA world \n"
);
}
int main()
{
//hello_Cuda << <1, 1 >> > ();
//多个线程执行同一个操作
//hello_Cuda << <20, 20 >> > ();
//hello_Cuda << <1, 20 >> > ();//和下面输出相同
hello_Cuda << <20, 1 >> > ();
//host 不必等待 kenel执行完成
//为了强制等待内核执行完毕,即同步
cudaDeviceSynchronize();
//往往需要将结果复制到主机
//这里使用复位
cudaDeviceReset();
return 0;
}
3.2 关键概念
block 和 grid

内核启动的前两个参数:
- block数量
- 每个block中线程的数量

dim3 block(4);//y,z 默认是1
dim3 grid(8);
hello_Cuda << <grid, block >> > ();
通过这种方式可以动态的设置每个维度的块数
int nx, ny;
nx = 16;
ny = 4;
dim3 block(8, 4);
dim3 grid(nx / block.x, ny / block.y);
hello_Cuda << <grid, block >> > ();
3.3 block 和 grid 的限制
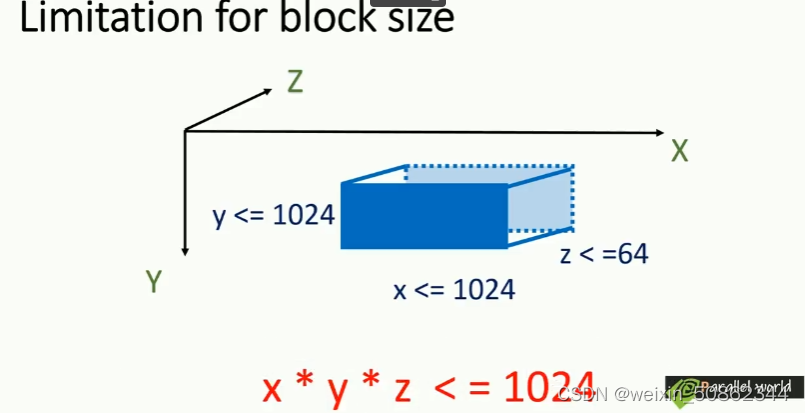
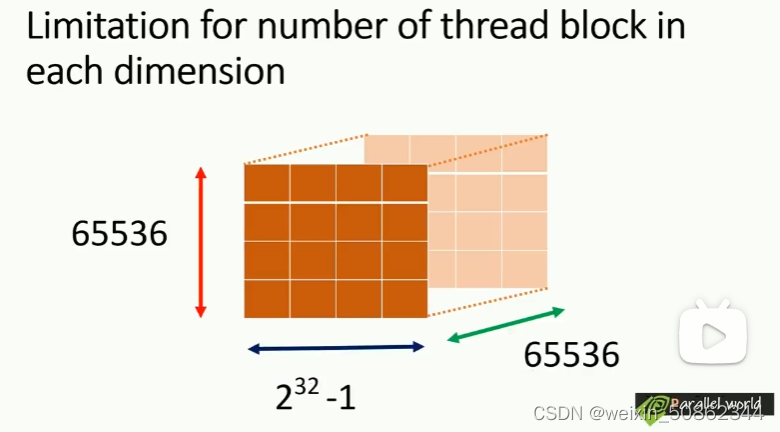
4. 线程序号
threadidx根据位置进行初始化
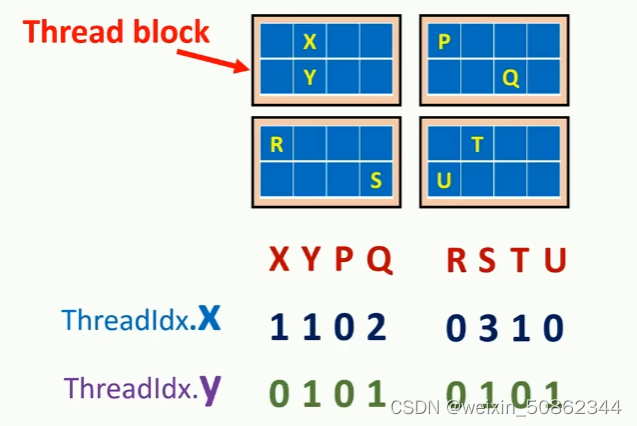
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void print_thread_idx()
{
printf(
"threadIdx.x : %d , threadIdx.y : %d,threadIdx.z : %d \n",
threadIdx.x, threadIdx.y, threadIdx.z
);
}
int main()
{
int nx, ny;
nx = 16;
ny = 16;
dim3 block(8, 8);
dim3 grid(nx / block.x, ny / block.y);
print_thread_idx << <grid, block >> > ();
cudaDeviceSynchronize();
cudaDeviceReset();
return 0;
}