20180606毕设更新:在2号终于有惊无险地完成了毕业答辩之后,终于有空,总结一下毕设内容,并且补上一些修改及最终代码。再加上一些吐槽的内容~
1、系统补充及修改
在这里详细地介绍一下整个系统的流程吧。
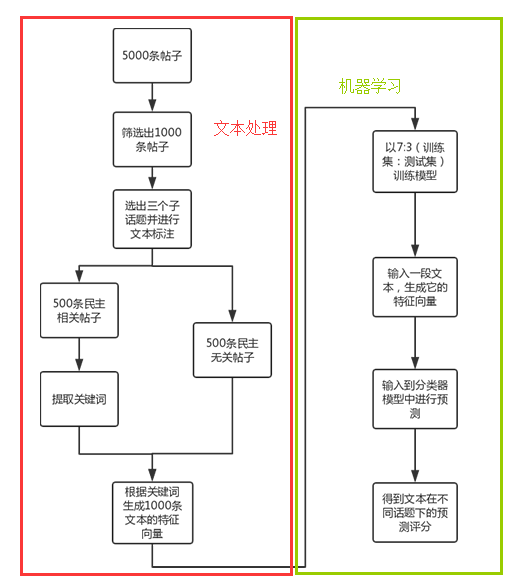
1.1 文本处理部分
1.1.1 文本标注
(1)挑选关键词
在此给定三个民主子话题——“民主制度”、“民主自由”和“民主监督”
(2)评分
给出相关度评分,1~5分,其中1为基本无关,5为非常相关。
| 基本无关 | 有点相关 | 基本相关 | 比较相关 | 非常相关 |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
(3)标注
在这里我主要标注了505条,标注格式为:
| 文本 | 民主制度 | 民主自由 | 民主监督 |
|---|---|---|---|
| '首先这两个目标是我们追求的理念,并不意味着马上能实现或一定能完全达到;其次人人平等和共同富裕都是相对的,表明每个人都有自己的尊严、生存发展和被他人尊重的权利,共同富裕则强调社会贫富差距相对很小,社会整体处于富足的状态。最后人人平等是普遍认可的普世价值,共同富裕是社会稳定的重要基础,理应成为每个政府施政追求的目标。 | 1 | 3 | 1 |
1.1.2 提取关键词
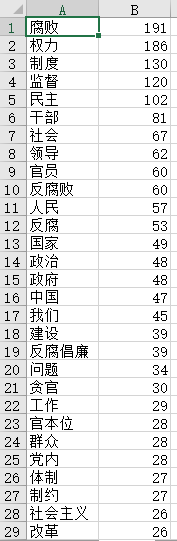
在这里,利用exckeyWords.py进行关键词抽取。
1.抽取存储、2.对抽取的关键词进行词频统计、3.对抽取结果进行处理前面写的这三篇博客对代码有比较细致的讲解。
该文件需要输入"biao2.xls",该表格存储了民主相关文本的标注信息,中间产生t1.xls中间表格(为了去掉空格和空值)。
关键词抽取后得到若干关键词,并保存在sta.xls中。如图:
1.1.3 生成文本特征向量
(1)自动标注
我又从语料库中挑选出1000+条文本,删掉一些与民主特别相关的文本之后,所有文本直接标注1,1,1即与所有民主子话题无关。具体参考
非民主相关帖子处理代码未改动。
将与民主相关的标注文本与上述自动生成的标注文本合并在一起,便得到了1000+条的标注文本。
(2)获取误差测试集,机器学习数据集
挑选300条用来测试误差,其余的当作机器学习的输入数据集。由于一共有1090条文本,所以随机生成0~1089之间的数字,生成300个,但有可能多出来,所以需要将多的删掉,如果是少的话,就不处理。由于每次结果不太一样,所以尽量选择多选的情况。
Lr=[]
for i in range(350):
Lr.append(random.randint(0, 1090))
Lr=list(set(Lr))
Lr.sort()
Lrlen=len(Lr)
delta=abs(300-Lrlen)
#delta为误差测试集数量超过300时的差值
for i in range(delta):
j=-i
Lr.pop(j)
print(len(Lr))
Ll=list(range(0,1090))
#Ll中有的并且不在Lr中的数字放入di中,即需要机器学习的数据集
di=[v for v in Ll if v not in Lr]
print(len(di))(3)向量生成
向量生成的详细过程参考
向量生成,代码是"MLdata.py".其中输入文件sta.xls为关键词集合;输入文件FMbeifen.xls是标注文本;输出文件t2.xls是将向量以Excel表格存储;输出文件test.txt是存放全部向量的txt文本;输出文件test2.txt和test3.txt分别是存放误差测试集和数据集的向量.
1.2 机器学习部分
之前的三篇写得很清楚了
1、机器学习分类实例(sklearn)——SVM,
2、机器学习分类实例(sklearn)——SVM(修改)/Decision Tree/Naive Bayes,
3、机器学习分类实例——数据测试
主要代码为:
svm.py; nby.py; dt.py
svmPre.py; nbyPre.py; dtPre.py
另外为了方便演示,我整合了一些代码为Bless.py,是希望答辩演示的时候能不崩溃。主要功能便是输入一段文本,自动地解析为特征向量,并根据对应算法,进行预测分类。