深度文本匹配总结
1、目录
2、前言
有幸参加“拍拍贷”举办的“第三届魔镜杯大赛”,此次比赛是基于其职能客服聊天机器人的数据,计算“提出问题”和“知识库问题”的相似度,进而定位问题给出答案,因此本次比赛需要关注“文本匹配”的技术。由于比赛所用数据全部脱敏无法使用外部词典,很多trick无法使用,加上需要匹配的文本很短,本次主要采用深度学习模型进行尝试。
深度文本匹配模型主要分为“基于单语义文档表达的深度学习模型”和“基于多语义文档表达的深度学习模型”两种。
3、基于单语义文档表达的深度学习模型
该类模型的特点是将两份待匹配的文档分别映射成两个向量,再将两个向量通过神经网络,最终输出一个结果,得出是否匹配的结论。典型的结构如下图所示:
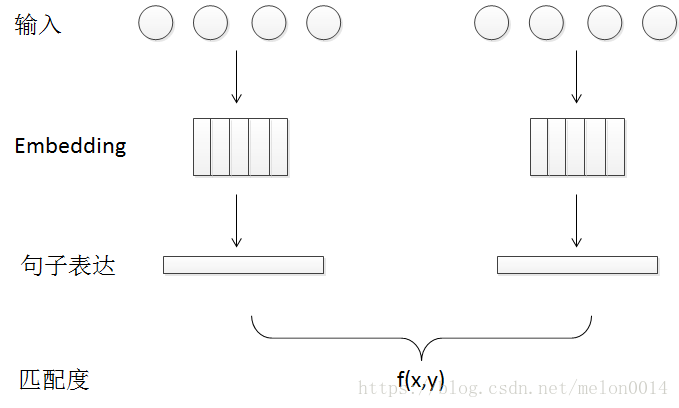
该类别中经典的模型有:DSSM、CDSSM、ARC-I。
3.1 经典模型
3.1.1 基础神经网络
首先介绍使用基础神经网络搭建的文本匹配模型。下图是keras中该模型的网络图,我们可以看到,网络分别为:
1)Embedding将句子变成300X25尺寸的张量(其中300是词向量维度)
2)通过激活函数是RELU的TimeDistributed(Dense)层过滤掉负数
3)Lamda层是Maxpooling的作用
4)将两个句子的向量拼接
5、6)带dropout的全连接层
7)BN层
8)全连接层

3.1.2 ARC-I
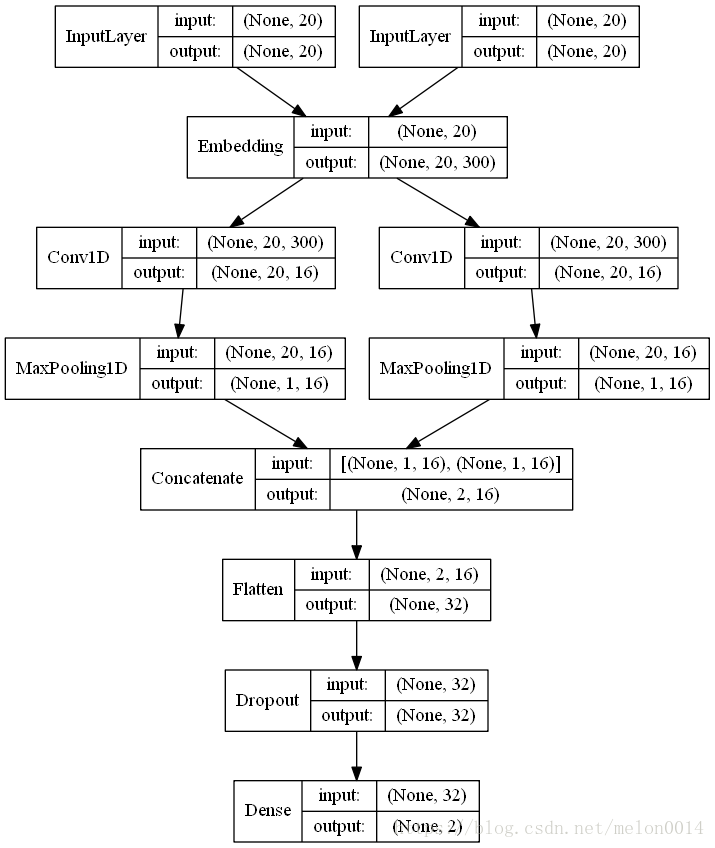
ARC-I的特点是在基础神经网络上将句子向量化的方法改为卷积操作。下图是keras中该模型的网络图,我们可以看到,网络分别为:
1)Embedding将句子变成300X20尺寸的张量(其中300是词向量维度)
2)一维卷积层
3)Maxpooling
4、5)拼接向量
6、7)带Dropout的全连接层
4、基于多语义文档表达的深度学习模型
该类模型的特点是将两份待匹配的文档通过神经网络以词、短语、句子等不同粒度表达,并交叉等到相似度矩阵,再将矩阵输入神经网络,得到是否匹配的结论。这一类模型使句子表示更丰富,可以描述更加抽象的内容,在复述问题等任务上效果很好。
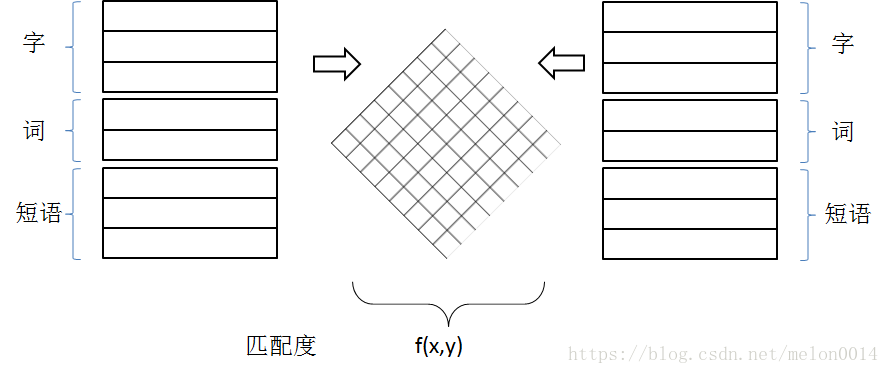
上图很好地描述了多语义模型的特点,区别于单语义模型,该类模型会在两个带匹配向量组合之前先进行交叉融合,产生更大的信息量。
4.1 经典模型
4.1.1 MV-LSTM
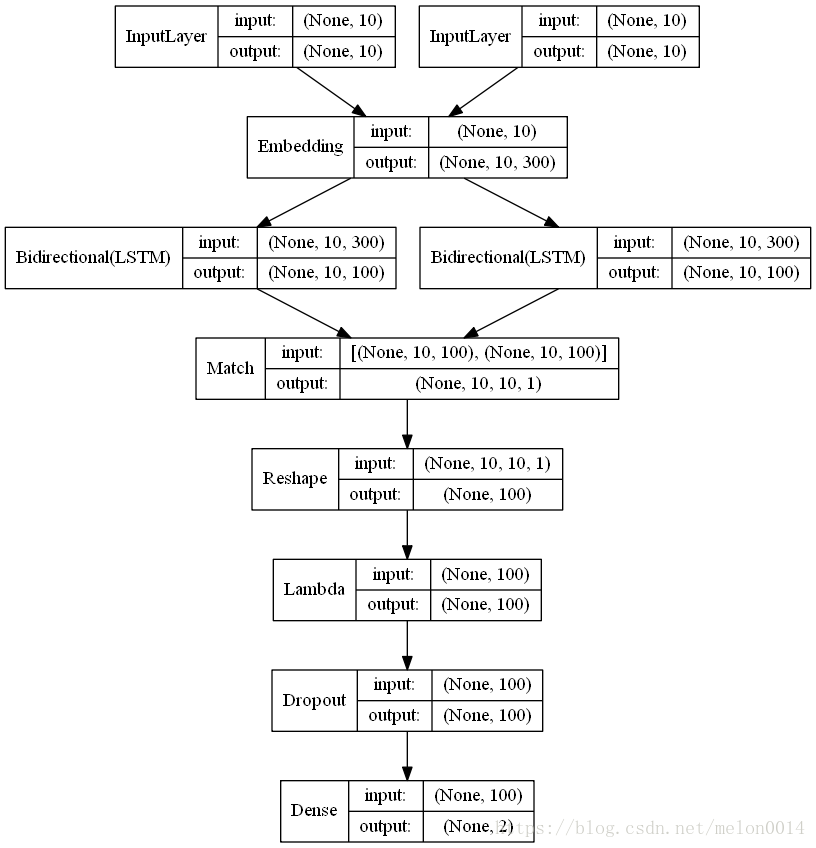
该类别中经典的框架有:MV-LSTM,如下图所示。首先将两句话分别使用双向LSTM拼接起来,然后组成矩阵,矩阵的每个元素都是两句话中各自的词的LSTM向量运算结果(如乘积),将矩阵kmaxpooling之后再经过神经网络得到匹配结论。
通过下图keras生成的网络结果我们可以更直观的看到MV-LSTM的网络中每一步tensor的尺寸。
5、参考文献
https://wenku.baidu.com/view/74e308c65122aaea998fcc22bcd126fff7055d3c.html?from=search
6、附件
6.1 神经网络代码
# coding=utf-8
from keras.layers import Input, TimeDistributed, Dense, Lambda, concatenate, Dropout, BatchNormalization
from keras.layers.embeddings import Embedding
from keras.regularizers import l2
from keras.callbacks import Callback, ModelCheckpoint
from keras.utils.data_utils import get_file
from keras import backend as K
from keras.utils.vis_utils import plot_model
from keras.models import Model
MAX_NB_WORDS = 1000
EMBEDDING_DIM = 300
class BASELINE():
def __init__(self, config, nb_words, word_embedding_matrix):
self.text1_maxlen = config['inputs']['share']['text1_maxlen']
self.text2_maxlen = config['inputs']['share']['text2_maxlen']
self.DROPOUT = config['model']['setting']['dropout_rate']
self.nb_words = nb_words
self.word_embedding_matrix = word_embedding_matrix
self.loss = config['losses'][0]['object_name']
self.optimizer = config['global']['optimizer']
def build(self):
# Define the model
question1 = Input(shape=(self.text1_maxlen,))
question2 = Input(shape=(self.text2_maxlen,))
q1 = Embedding(self.nb_words + 1,
EMBEDDING_DIM,
weights=[self.word_embedding_matrix],
input_length=self.text1_maxlen,
trainable=False)(question1)
q1 = TimeDistributed(Dense(EMBEDDING_DIM, activation='relu'))(q1)
q1 = Lambda(lambda x: K.max(x, axis=1), output_shape=(EMBEDDING_DIM, ))(q1)
q2 = Embedding(self.nb_words + 1,
EMBEDDING_DIM,
weights=[self.word_embedding_matrix],
input_length=self.text2_maxlen,
trainable=False)(question2)
q2 = TimeDistributed(Dense(EMBEDDING_DIM, activation='relu'))(q2)
q2 = Lambda(lambda x: K.max(x, axis=1), output_shape=(EMBEDDING_DIM, ))(q2)
merged = concatenate([q1,q2])
merged = Dense(200, activation='relu')(merged)
merged = Dropout(self.DROPOUT)(merged)
merged = BatchNormalization()(merged)
is_duplicate = Dense(1, activation='sigmoid')(merged)
model = Model(inputs=[question1,question2], outputs=is_duplicate)
model.compile(loss=self.loss, optimizer=self.optimizer, metrics=['binary_crossentropy'])
plot_model(model, to_file=r'model_graph.png', show_shapes=True, show_layer_names=False)
return model
6.2 ARC-I代码
#coding:utf-8
'''
1.arcii_0703_v1_2.py
'''
import sys
import argparse
import time
import pandas as pd
import numpy as np
# 文本处理
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import Input, TimeDistributed, Dense, Lambda, concatenate, Dropout, BatchNormalization
from keras.layers.embeddings import Embedding
from keras.layers import *
from keras.regularizers import l2
from keras.callbacks import Callback, ModelCheckpoint
from keras.utils.data_utils import get_file
from keras import backend as K
from keras.utils.vis_utils import plot_model
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
###################################
# 在上一版本0703_v1_1的基础上,1、微调参数。2、train_data也改了
# 3、把1D卷积,两个改成一个
###################################
MAX_NB_WORDS = 2000
MAX_SEQUENCE_LENGTH = 10
train_data = 'data/train_random_exchange.csv'
# 设置超参数
dropout_rate = 0.25
kernel_1d_count = 32 # 在原基础上修改
kernel_1d_size = 4
num_conv2d_layers = 2
kernel_2d_counts = [32, 32] # 在原基础上修改
kernel_2d_sizes = [[4,4],[4,4]]
mpool_2d_sizes = [[2,2],[2,2]]
train_rounds = 30
train_history_log = r'./log/1.arcii_0703_v1_2.log'
train_history_figure = './log/1.arcii_0703_v1_2.png'
save_weights_dir = './weights/1.arcii_0703_v1_2_'
test_model_epoch = 20
submit_file = 'submit_1.arcii_0703_v1_2.csv'
###################################
class Match(Layer):
"""Layer that computes a matching matrix between samples in two tensors.
# Arguments
normalize: Whether to L2-normalize samples along the
dot product axis before taking the dot product.
If set to True, then the output of the dot product
is the cosine proximity between the two samples.
**kwargs: Standard layer keyword arguments.
"""
def __init__(self, normalize=False, match_type='dot', **kwargs):
super(Match, self).__init__(**kwargs)
self.normalize = normalize
self.match_type = match_type
self.supports_masking = True
if match_type not in ['dot', 'mul', 'plus', 'minus', 'concat']:
raise ValueError('In `Match` layer, '
'param match_type=%s is unknown.' % match_type)
def build(self, input_shape):
# Used purely for shape validation.
if not isinstance(input_shape, list) or len(input_shape) != 2:
raise ValueError('A `Match` layer should be called '
'on a list of 2 inputs.')
self.shape1 = input_shape[0]
self.shape2 = input_shape[1]
if self.shape1[0] != self.shape2[0]:
raise ValueError(
'Dimension incompatibility '
'%s != %s. ' % (self.shape1[0], self.shape2[0]) +
'Layer shapes: %s, %s' % (self.shape1, self.shape2))
if self.shape1[2] != self.shape2[2]:
raise ValueError(
'Dimension incompatibility '
'%s != %s. ' % (self.shape1[2], self.shape2[2]) +
'Layer shapes: %s, %s' % (self.shape1, self.shape2))
def call(self, inputs):
x1 = inputs[0]
x2 = inputs[1]
if self.match_type in ['dot']:
if self.normalize:
x1 = K.l2_normalize(x1, axis=2)
x2 = K.l2_normalize(x2, axis=2)
output = K.tf.einsum('abd,acd->abc', x1, x2)
output = K.tf.expand_dims(output, 3)
elif self.match_type in ['mul', 'plus', 'minus']:
x1_exp = K.tf.stack([x1] * self.shape2[1], 2)
x2_exp = K.tf.stack([x2] * self.shape1[1], 1)
if self.match_type == 'mul':
output = x1_exp * x2_exp
elif self.match_type == 'plus':
output = x1_exp + x2_exp
elif self.match_type == 'minus':
output = x1_exp - x2_exp
elif self.match_type in ['concat']:
x1_exp = K.tf.stack([x1] * self.shape2[1], axis=2)
x2_exp = K.tf.stack([x2] * self.shape1[1], axis=1)
output = K.tf.concat([x1_exp, x2_exp], axis=3)
return output
def compute_output_shape(self, input_shape):
if not isinstance(input_shape, list) or len(input_shape) != 2:
raise ValueError('A `Match` layer should be called '
'on a list of 2 inputs.')
shape1 = list(input_shape[0])
shape2 = list(input_shape[1])
if len(shape1) != 3 or len(shape2) != 3:
raise ValueError('A `Match` layer should be called '
'on 2 inputs with 3 dimensions.')
if shape1[0] != shape2[0] or shape1[2] != shape2[2]:
raise ValueError('A `Match` layer should be called '
'on 2 inputs with same 0,2 dimensions.')
if self.match_type in ['dot']:
output_shape = [shape1[0], shape1[1], shape2[1], 1]
elif self.match_type in ['mul', 'plus', 'minus']:
output_shape = [shape1[0], shape1[1], shape2[1], shape1[2]]
elif self.match_type in ['concat']:
output_shape = [shape1[0], shape1[1], shape2[1], shape1[2]+shape2[2]]
return tuple(output_shape)
def compute_mask(self, inputs, mask=None):
return None
def get_config(self):
config = {
'normalize': self.normalize,
'match_type': self.match_type,
}
base_config = super(Match, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def match(inputs, axes, normalize=False, match_type='dot', **kwargs):
"""Functional interface to the `Match` layer.
# Arguments
inputs: A list of input tensors (with exact 2 tensors).
normalize: Whether to L2-normalize samples along the
dot product axis before taking the dot product.
If set to True, then the output of the dot product
is the cosine proximity between the two samples.
**kwargs: Standard layer keyword arguments.
# Returns
A tensor, the dot product matching matrix of the samples
from the inputs.
"""
return Match(normalize=normalize, match_type=match_type, **kwargs)(inputs)
def my_train_test_split(X, y, test_size=0.25, random_state=42):
length = len(X)
train_test_length = round(length*(1-test_size))
X_train = X[:train_test_length, :, :]
y_train = y[:train_test_length]
X_test = X[train_test_length:, :, :]
y_test = y[train_test_length:]
return X_train, X_test, y_train, y_test
# word level
question = pd.read_csv('data/question.csv')
question = question[['qid','words']]
train = pd.read_csv(train_data)
test = pd.read_csv('data/test.csv')
train = pd.merge(train,question,left_on=['q1'],right_on=['qid'],how='left')
train = pd.merge(train,question,left_on=['q2'],right_on=['qid'],how='left')
train = train[['label','words_x','words_y']]
train.columns = ['label','q1','q2']
test = pd.merge(test,question,left_on=['q1'],right_on=['qid'],how='left')
test = pd.merge(test,question,left_on=['q2'],right_on=['qid'],how='left')
test = test[['words_x','words_y']]
test.columns = ['q1','q2']
all = pd.concat([train,test])
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(question['words'])
q1_word_seq = tokenizer.texts_to_sequences(all['q1'])
q2_word_seq = tokenizer.texts_to_sequences(all['q2'])
word_index = tokenizer.word_index
embeddings_index = {}
with open('data/word_embed_norm.txt','r') as f:
for i in f:
values = i.split(' ')
word = str(values[0])
embedding = np.asarray(values[1:],dtype='float')
embeddings_index[word] = embedding
print('word embedding',len(embeddings_index))
EMBEDDING_DIM = 300
nb_words = min(MAX_NB_WORDS,len(word_index))
word_embedding_matrix = np.zeros((nb_words + 1, EMBEDDING_DIM))
for word, i in word_index.items():
if i > MAX_NB_WORDS:
continue
embedding_vector = embeddings_index.get(str(word).upper())
if embedding_vector is not None:
word_embedding_matrix[i] = embedding_vector
q1_data = pad_sequences(q1_word_seq,maxlen=MAX_SEQUENCE_LENGTH)
q2_data = pad_sequences(q2_word_seq,maxlen=MAX_SEQUENCE_LENGTH)
train_q1_data = q1_data[:train.shape[0]]
train_q2_data = q2_data[:train.shape[0]]
test_q1_data = q1_data[train.shape[0]:]
test_q2_data = q2_data[train.shape[0]:]
labels = train['label']
print('Shape of question1 train data tensor:', train_q1_data.shape)
print('Shape of question2 train data tensor:', train_q2_data.shape)
print('Shape of question1 test data tensor:', test_q1_data.shape)
print('Shape of question1 test data tensor:', test_q2_data.shape)
print('Shape of label tensor:', labels.shape)
X = np.stack((train_q1_data, train_q2_data), axis=1)
y = labels
X_train, X_test, y_train, y_test = my_train_test_split(X, y, test_size=0.1, random_state=42)
Q1_train = X_train[:,0]
Q2_train = X_train[:,1]
Q1_test = X_test[:,0]
Q2_test = X_test[:,1]
# y_train_set = keras.utils.to_categorical(y_train_set)
query = Input(name='query', shape=(MAX_SEQUENCE_LENGTH,))
doc = Input(name='doc', shape=(MAX_SEQUENCE_LENGTH,))
embedding = Embedding(nb_words + 1,
EMBEDDING_DIM,
weights=[word_embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
q_embed = embedding(query)
d_embed = embedding(doc)
# q_conv1 = Conv1D(kernel_1d_count, kernel_1d_size, padding='same') (q_embed)
# d_conv1 = Conv1D(kernel_1d_count, kernel_1d_size, padding='same') (d_embed)
conv1d = Conv1D(kernel_1d_count, kernel_1d_size, padding='same')
q_conv1 = conv1d(q_embed)
d_conv1 = conv1d(d_embed)
cross = Match(match_type='dot')([q_conv1, d_conv1])
z = Reshape((MAX_SEQUENCE_LENGTH, MAX_SEQUENCE_LENGTH, -1))(cross)
for i in range(num_conv2d_layers):
z = Conv2D(filters=kernel_2d_counts[i], kernel_size=kernel_2d_sizes[i], padding='same', activation='relu')(z)
z = MaxPooling2D(pool_size=(mpool_2d_sizes[i][0], mpool_2d_sizes[i][1]))(z)
#dpool = DynamicMaxPooling(self.config['dpool_size'][0], self.config['dpool_size'][1])([conv2d, dpool_index])
pool1_flat = Flatten()(z)
pool1_flat_drop = Dropout(rate=dropout_rate)(pool1_flat)
out_ = Dense(1, activation='sigmoid')(pool1_flat_drop)
model = Model(inputs=[query, doc], outputs=out_)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['binary_crossentropy'])
# plot_model(model, to_file=r'C:\Users\hyguo\Downloads\model_graph_my_mvlstm.png', show_shapes=True, show_layer_names=False)
def train():
# 训练模型
save_weights_iters=5
train_loss=[]
val_loss=[]
with open(train_history_log, 'w') as fw:
for round in range(train_rounds):
print('round: ',round)
model_checkpoint = ModelCheckpoint(save_weights_dir + str(round), save_best_only=False,
save_weights_only=False)
if round%save_weights_iters==0:
history = model.fit([Q1_train, Q2_train],
y_train,
epochs=1,
validation_data=[[Q1_test, Q2_test], y_test],
verbose=1,
batch_size=1024,
callbacks=[model_checkpoint]
)
else:
history = model.fit([Q1_train, Q2_train],
y_train,
epochs=1,
validation_data=[[Q1_test, Q2_test], y_test],
verbose=1,
batch_size=1024,
)
for k in history.history['loss']:
train_loss.append(k)
for j in history.history['val_loss']:
val_loss.append(j)
fw.write('[%s]\t[Round %d]\t train_loss: %f val_loss: %f\n' %(time.strftime('%m-%d-%Y %H:%M:%S', time.localtime(time.time())), round, train_loss[-1], val_loss[-1]) )
fig = plt.figure()
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
fig.savefig(train_history_figure)
print(history.history.keys())
def predict():
# 预测结果
test_model_dir = save_weights_dir + str(test_model_epoch)
model.load_weights(test_model_dir)
print('load model: '+ test_model_dir+' ...')
result = model.predict([test_q1_data,test_q2_data],batch_size=1024)
print('predict finished!')
# 提交结果
submit = pd.DataFrame()
submit['y_pre'] = list(result[:,0])
submit.to_csv(submit_file,index=False)
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument('--phase', default='train', help='Phase: Can be train or predict, the default value is train.')
args = parser.parse_args()
phase = args.phase
if args.phase == 'train':
train()
elif args.phase == 'predict':
predict()
else:
print('Phase Error.', end='\n')
return
if __name__=='__main__':
main(sys.argv)
6.3 MV-LSTM代码
#coding:utf-8
'''
1.mvlstm_0703_v1_2.py
'''
import sys
import argparse
import time
import pandas as pd
import numpy as np
# 文本处理
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import Input, TimeDistributed, Dense, Lambda, concatenate, Dropout, BatchNormalization
from keras.layers.embeddings import Embedding
from keras.layers import *
from keras.regularizers import l2
from keras.callbacks import Callback, ModelCheckpoint, EarlyStopping
from keras.utils.data_utils import get_file
from keras import backend as K
# from sklearn.model_selection import train_test_split
from keras.utils.vis_utils import plot_model
from keras.models import load_model as load_weights
import matplotlib.pyplot as plt
import warnings
from matplotlib.ticker import MultipleLocator, FormatStrFormatter
warnings.filterwarnings('ignore')
###################################
# 0703_v1_1在0703_v1_1基础上将dropout改了。
###################################
train_data = 'data/train_random_exchangesplit.csv' # 0702_v1_1修改
train_history_log = r'./log/1.mvlstm_0703_v1_2.log'
train_history_figure = './log/1.mvlstm_0703_v1_2.png'
save_weights_dir = './weights/1.mvlstm_0703_v1_2_'
# 设置超参数
MAX_NB_WORDS = 2000 # 0702_v1_0修改
MAX_SEQUENCE_LENGTH = 10
hidden_size = 50
topk = 50
dropout_rate = 0.25
train_rounds = 60
test_rounds = 25
submit_file = 'submit_1.mvlstm_0703_v1_2_'+str(test_rounds)+'.csv'
###################################
class Match(Layer):
"""Layer that computes a matching matrix between samples in two tensors.
# Arguments
normalize: Whether to L2-normalize samples along the
dot product axis before taking the dot product.
If set to True, then the output of the dot product
is the cosine proximity between the two samples.
**kwargs: Standard layer keyword arguments.
"""
def __init__(self, normalize=False, match_type='dot', **kwargs):
super(Match, self).__init__(**kwargs)
self.normalize = normalize
self.match_type = match_type
self.supports_masking = True
if match_type not in ['dot', 'mul', 'plus', 'minus', 'concat']:
raise ValueError('In `Match` layer, '
'param match_type=%s is unknown.' % match_type)
def build(self, input_shape):
# Used purely for shape validation.
if not isinstance(input_shape, list) or len(input_shape) != 2:
raise ValueError('A `Match` layer should be called '
'on a list of 2 inputs.')
self.shape1 = input_shape[0]
self.shape2 = input_shape[1]
if self.shape1[0] != self.shape2[0]:
raise ValueError(
'Dimension incompatibility '
'%s != %s. ' % (self.shape1[0], self.shape2[0]) +
'Layer shapes: %s, %s' % (self.shape1, self.shape2))
if self.shape1[2] != self.shape2[2]:
raise ValueError(
'Dimension incompatibility '
'%s != %s. ' % (self.shape1[2], self.shape2[2]) +
'Layer shapes: %s, %s' % (self.shape1, self.shape2))
def call(self, inputs):
x1 = inputs[0]
x2 = inputs[1]
if self.match_type in ['dot']:
if self.normalize:
x1 = K.l2_normalize(x1, axis=2)
x2 = K.l2_normalize(x2, axis=2)
output = K.tf.einsum('abd,acd->abc', x1, x2)
output = K.tf.expand_dims(output, 3)
elif self.match_type in ['mul', 'plus', 'minus']:
x1_exp = K.tf.stack([x1] * self.shape2[1], 2)
x2_exp = K.tf.stack([x2] * self.shape1[1], 1)
if self.match_type == 'mul':
output = x1_exp * x2_exp
elif self.match_type == 'plus':
output = x1_exp + x2_exp
elif self.match_type == 'minus':
output = x1_exp - x2_exp
elif self.match_type in ['concat']:
x1_exp = K.tf.stack([x1] * self.shape2[1], axis=2)
x2_exp = K.tf.stack([x2] * self.shape1[1], axis=1)
output = K.tf.concat([x1_exp, x2_exp], axis=3)
return output
def compute_output_shape(self, input_shape):
if not isinstance(input_shape, list) or len(input_shape) != 2:
raise ValueError('A `Match` layer should be called '
'on a list of 2 inputs.')
shape1 = list(input_shape[0])
shape2 = list(input_shape[1])
if len(shape1) != 3 or len(shape2) != 3:
raise ValueError('A `Match` layer should be called '
'on 2 inputs with 3 dimensions.')
if shape1[0] != shape2[0] or shape1[2] != shape2[2]:
raise ValueError('A `Match` layer should be called '
'on 2 inputs with same 0,2 dimensions.')
if self.match_type in ['dot']:
output_shape = [shape1[0], shape1[1], shape2[1], 1]
elif self.match_type in ['mul', 'plus', 'minus']:
output_shape = [shape1[0], shape1[1], shape2[1], shape1[2]]
elif self.match_type in ['concat']:
output_shape = [shape1[0], shape1[1], shape2[1], shape1[2]+shape2[2]]
return tuple(output_shape)
def compute_mask(self, inputs, mask=None):
return None
def get_config(self):
config = {
'normalize': self.normalize,
'match_type': self.match_type,
}
base_config = super(Match, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def match(inputs, axes, normalize=False, match_type='dot', **kwargs):
"""Functional interface to the `Match` layer.
# Arguments
inputs: A list of input tensors (with exact 2 tensors).
normalize: Whether to L2-normalize samples along the
dot product axis before taking the dot product.
If set to True, then the output of the dot product
is the cosine proximity between the two samples.
**kwargs: Standard layer keyword arguments.
# Returns
A tensor, the dot product matching matrix of the samples
from the inputs.
"""
return Match(normalize=normalize, match_type=match_type, **kwargs)(inputs)
def my_train_test_split(X, y, test_size=0.25, random_state=42):
length = len(X)
train_test_length = round(length*(1-test_size)) # 最好是457896
print("Test_size: ", test_size)
X_train = X[:train_test_length, :, :]
y_train = y[:train_test_length]
X_test = X[train_test_length:, :, :]
y_test = y[train_test_length:]
return X_train, X_test, y_train, y_test
# word level
question = pd.read_csv('data/question.csv')
question = question[['qid','words']]
train = pd.read_csv(train_data)
test = pd.read_csv('data/test.csv')
train = pd.merge(train,question,left_on=['q1'],right_on=['qid'],how='left')
train = pd.merge(train,question,left_on=['q2'],right_on=['qid'],how='left')
train = train[['label','words_x','words_y']]
train.columns = ['label','q1','q2']
test = pd.merge(test,question,left_on=['q1'],right_on=['qid'],how='left')
test = pd.merge(test,question,left_on=['q2'],right_on=['qid'],how='left')
test = test[['words_x','words_y']]
test.columns = ['q1','q2']
all = pd.concat([train,test])
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(question['words'])
q1_word_seq = tokenizer.texts_to_sequences(all['q1'])
q2_word_seq = tokenizer.texts_to_sequences(all['q2'])
word_index = tokenizer.word_index
embeddings_index = {}
with open('data/word_embed_norm.txt','r') as f:
for i in f:
values = i.split(' ')
word = str(values[0])
embedding = np.asarray(values[1:],dtype='float')
embeddings_index[word] = embedding
print('word embedding',len(embeddings_index))
EMBEDDING_DIM = 300
nb_words = min(MAX_NB_WORDS,len(word_index))
word_embedding_matrix = np.zeros((nb_words + 1, EMBEDDING_DIM))
for word, i in word_index.items():
if i > MAX_NB_WORDS:
continue
embedding_vector = embeddings_index.get(str(word).upper())
if embedding_vector is not None:
word_embedding_matrix[i] = embedding_vector
q1_data = pad_sequences(q1_word_seq,maxlen=MAX_SEQUENCE_LENGTH)
q2_data = pad_sequences(q2_word_seq,maxlen=MAX_SEQUENCE_LENGTH)
train_q1_data = q1_data[:train.shape[0]]
train_q2_data = q2_data[:train.shape[0]]
test_q1_data = q1_data[train.shape[0]:]
test_q2_data = q2_data[train.shape[0]:]
labels = train['label']
print('Shape of question1 train data tensor:', train_q1_data.shape)
print('Shape of question2 train data tensor:', train_q2_data.shape)
print('Shape of question1 test data tensor:', test_q1_data.shape)
print('Shape of question1 test data tensor:', test_q2_data.shape)
print('Shape of label tensor:', labels.shape)
X = np.stack((train_q1_data, train_q2_data), axis=1)
y = labels
# from sklearn.model_selection import StratifiedShuffleSplit
X_train, X_test, y_train, y_test = my_train_test_split(X, y, test_size=0.1, random_state=42)
Q1_train = X_train[:,0]
Q2_train = X_train[:,1]
Q1_test = X_test[:,0]
Q2_test = X_test[:,1]
# y_train_set = keras.utils.to_categorical(y_train_set)
DROPOUT = 0.25
# Define the model
query = Input(name='query', shape=(MAX_SEQUENCE_LENGTH,))
doc = Input(name='doc', shape=(MAX_SEQUENCE_LENGTH,))
embedding = Embedding(nb_words + 1,
EMBEDDING_DIM,
weights=[word_embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
q_embed = embedding(query)
d_embed = embedding(doc)
# q_rep = Bidirectional(LSTM(hidden_size, return_sequences=True, dropout=dropout_rate))(q_embed)
# d_rep = Bidirectional(LSTM(hidden_size, return_sequences=True, dropout=dropout_rate))(d_embed)
lstm = Bidirectional(LSTM(hidden_size, return_sequences=True, dropout=dropout_rate))
q_rep = lstm(q_embed)
d_rep = lstm(d_embed)
cross = Match(match_type='dot')([q_rep, d_rep])
#cross = Dot(axes=[2, 2])([q_embed, d_embed])
cross_reshape = Reshape((-1, ))(cross)
mm_k = Lambda(lambda x: K.tf.nn.top_k(x, k=topk, sorted=True)[0])(cross_reshape)
pool1_flat_drop = Dropout(rate=dropout_rate)(mm_k)
out_ = Dense(1, activation='sigmoid')(pool1_flat_drop)
#model = Model(inputs=[query, doc, dpool_index], outputs=out_)
model = Model(inputs=[query, doc], outputs=out_)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['binary_crossentropy'])
# plot_model(model, to_file=r'C:\Users\hyguo\Downloads\model_graph_my_mvlstm.png', show_shapes=True, show_layer_names=False)
# 训练模型
def train():
save_weights_iters=5
train_loss=[]
val_loss=[]
fw = open(train_history_log, 'w')
for round in range(train_rounds):
print('round: ',round)
model_checkpoint = ModelCheckpoint(save_weights_dir + str(round), save_best_only=False,
save_weights_only=True)
early_stopping = EarlyStopping(monitor='val_loss', patience=5)
if round%save_weights_iters==0:
history = model.fit([Q1_train, Q2_train],
y_train,
epochs=1,
validation_data=[[Q1_test, Q2_test], y_test],
verbose=1,
batch_size=1024,
callbacks=[model_checkpoint, early_stopping]
)
else:
history = model.fit([Q1_train, Q2_train],
y_train,
epochs=1,
validation_data=[[Q1_test, Q2_test], y_test],
verbose=1,
batch_size=1024,
callbacks=[early_stopping]
)
for k in history.history['loss']:
train_loss.append(k)
for j in history.history['val_loss']:
val_loss.append(j)
if round!=0:
fw = open(train_history_log, 'a')
fw.write('[%s]\t[Round %d]\t train_loss: %f val_loss: %f\n' %(time.strftime('%m-%d-%Y %H:%M:%S', time.localtime(time.time())), round, train_loss[-1], val_loss[-1]) )
fw.close()
fig = plt.figure()
xmajorLocator = MultipleLocator(2) # 将x主刻度标签设置为20的倍数
xmajorFormatter = FormatStrFormatter('%d') # 设置x轴标签文本的格式
xminorLocator = MultipleLocator(0.5) # 将x轴次刻度标签设置为5的倍数
ymajorLocator = MultipleLocator(0.01) # 将y轴主刻度标签设置为0.5的倍数
yminorLocator = MultipleLocator(0.005) # 将此y轴次刻度标签设置为0.1的倍数
ax = plt.subplot(111)
plt.plot(train_loss)
plt.plot(val_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
# 设置主刻度标签的位置,标签文本的格式
ax.xaxis.set_major_locator(xmajorLocator)
ax.xaxis.set_major_formatter(xmajorFormatter)
ax.yaxis.set_major_locator(ymajorLocator)
# 显示次刻度标签的位置,没有标签文本
ax.xaxis.set_minor_locator(xminorLocator)
ax.yaxis.set_minor_locator(yminorLocator)
ax.xaxis.grid(True, which='major') # x坐标轴的网格使用主刻度
ax.yaxis.grid(True, which='minor') # y坐标轴的网格使用次刻度
fig.savefig(train_history_figure)
print(history.history.keys())
# 预测结果
def predict():
# 载入model
model_dir = save_weights_dir + str(test_rounds)
model.load_weights(model_dir)
print('load model: '+ model_dir+' ...')
result = model.predict([test_q1_data,test_q2_data],batch_size=1024)
print('predict finished!')
# 提交结果
submit = pd.DataFrame()
submit['y_pre'] = list(result[:,0])
submit.to_csv(submit_file,index=False)
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument('--phase', default='train', help='Phase: Can be train or predict, the default value is train.')
args = parser.parse_args()
phase = args.phase
if args.phase == 'train':
train()
elif args.phase == 'predict':
predict()
else:
print('Phase Error.', end='\n')
return
if __name__=='__main__':
main(sys.argv)