聚类与判别
方差分析使用类别自变量和连续数因变量,而判别分析连续自变量和类别因变量(即类标签)
启发式方法:K-mean和k-medoid算法
k-means:每个群集由群集的中心表示
K-medoid或PAM(围绕medoid的分区):每个集群由集群中的一个对象表示
============================================
K-Mean
就是在已知要分为4类之后,将K=4,随便找到4个点,计算每个原始点的到这四个点中心的距离,选择距离最近的点归类,这就有4类点,再在这些点内部计算每一点的质心,这就有了新的4个点,再对所有点计算到这四个点的距离,然后比较,以此类推。

处理数值数据

========================================================
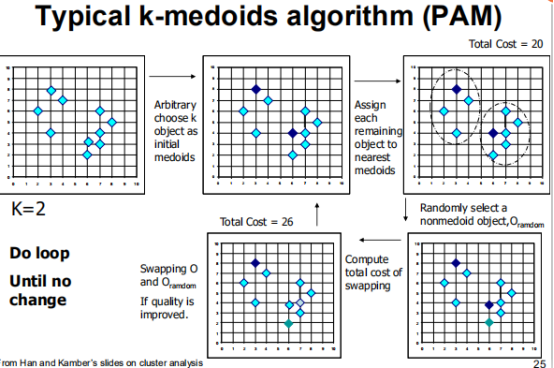
L-medoid聚类方法
即若K=2,则选择原始数据中的某两个点作为原始medoids,计算每个点到该点的距离,形成两个簇,再选择一个非之前的点作为medoid,如果花费得到改善则将medoid值替换为改点,如果没有得到改善则不变。
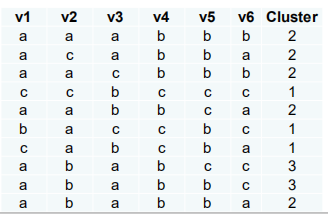
处理分类数据
对PAM的评论
在存在噪声和异常值的情况下,pam比k均值更健壮,因为Medoid受异常值或其他极值的影响小于k-means。因为medoid是基于数据排序,PAM有效地适用于小型数据集,但对于大型数据集,PAM不能很好地扩展,因为迭代次数较多,每个迭代的O(k(n-k)2)。
=====================================================
分类数据和数值数据的混合:K-prototype
================================================
CLARA集群大型应用程序
它绘制数据集的多个样本,对每个样本应用PAM,并给出最佳的聚类作为输出。
优点:处理比PAM更大的数据集。
劣势:效率取决于样本量。
-如果样本被偏置,则基于样本的良好聚类不一定代表整个数据集的良好聚类
即将原来的所有样本划分为更小单元,即单个样本来进行PAM
==================================================
分层群聚
使用距离矩阵作为聚类准则。此方法不需要将群集k的数目作为输入,而是需要一个终止条件。
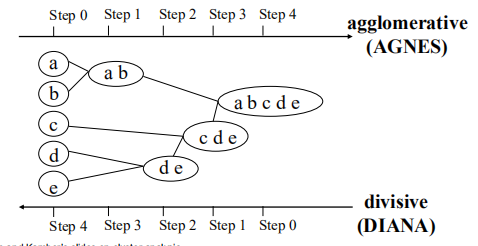
给定一组待聚类的项目和NxN距离(或相似度)矩阵,基本过程分层聚类是这样的:
- 首先,将每个项分配给它自己的集群,这样如果您有N个项,那么您现在就有N个集群,每个集群只包含一个项。
- 找到最接近(最相似)的集群,并将它们合并到一个集群中,这样现在就少了一个集群。
- 计算新集群和每个旧集群之间的距离(相似之处)。
- 重复步骤2和步骤3,直到所有项目聚集成一个大小为N的集群。
就像哈弗曼树得到的过程一样。
=====================================================
DA用于通过距离度量来标识对象组之间的边界。
在方差分析中,自变量是分类变量,因变量是连续变量。
在判别分析中,自变量是连续变量,因变量是分类变量。
DA分析的前提:
- 样本量一定要比变量数大
- 正态分布,违反正态假设并不是“致命的”
- 方差/协方差的同质性,判别分析对方差协方差矩阵的异质性非常敏感。
离群值的影响:判别分析对离群点的包含非常敏感,因为这会加大方差,凡是加
大方差的操作对于DA分析都是致命打击。
非线性:如果其中一个自变量与另一个独立变量高度相关,或者一个是其他独立变量的函数(例如和),那么矩阵就没有唯一的判别解。即没有鉴别函数能解决这个问题。
========================================
判别分析与聚类
判别分析:
已知的类数量
基于训练集
用于对未来的观测进行分类
分类是监督学习的一种形式:Y =X1 + X2 + X3,即有target
聚类:
未知类数
无先验知识
用于理解(探索)数据
聚类是一种无监督学习形式:X1 + X2 + X3,即没有target