根据已有的数据分类知识,建立一个判别准则,使其错判率最低,进而基于这个判别准则实现对未知样本所属类别进行判断。
一般判别分析
DISCRIM过程
格式:
proc discrim data=数据集名;
class 变量; *此语句必需的,指定判别分析用的分类变量名;
var 变量列表;*指定判别分析中使用的变量;
run;
注:
1.proc过程选项:
I.list:显示已知分类的数据集重分类的结果;
ii.testlist:在结果窗口中显示对检验未知样本的所有分类结果;
iii.testdata=待分析数据集名;
例
根据下面第一张表对经济发达水平的判别,对第二张表进行经济发达水平的判别分析。


代码:
data test1; /*创建判别分析数据*/
input area$ x1-x7 type;
cards;
西城区 1.96 18.85 19.34 198.49 89.11 59.88 2.34 2
崇文区 0.94 6.49 10.98 61.95 32.9 39.3 1.1 1
宣武区 0.33 12.04 58.8 586.48 458.73 167.29 6.78 2
石景山区 1.01 16.14 74.26 483.57 209.81 250.16 3.91 2
海淀区 201.26 69.5 125.01 640.38 373.06 448.59 36.5 3
门头沟区 0.97 4.32 8.67 44.31 27.02 18.91 0.59 2
房山区 4.17 1.42 43.88 293.31 163.33 305.44 0.03 2
通州区 5.46 10.71 14.99 86.64 54.18 48.65 1.06 2
顺义区 10.33 135.15 42.91 231.81 131.43 229.14 14.25 3
昌平区 9.1 10.37 17.45 103.33 61.94 52.28 2.39 2
大兴区 14.15 94.62 56.59 199.47 102.55 140.28 13.64 3
平谷县 6.99 8.17 9.58 49.42 37.22 30.96 1.6 1
怀柔县 10.59 17.84 21.48 80.42 47.75 75.95 4.25 1
密云县 2.92 17.52 14.32 42.99 24.89 37.44 1.79 1
;
run;
data test2; /*创建待判别分析数据*/
input area$ x1-x7;
cards;
东城区 2.46 42.33 24.6 178.96 77.67 87.86 6.39
朝阳区 52.08 313.41 124.83 836.01 473.35 581.38 30.3
丰台区 14.33 32.01 30.38 202.38 125.29 116.2 3.83
延庆县 0.44 0.58 1.24 7.64 5.66 5.05 - 0.09
;
run;
proc discrim data=test1 testdata=test2 list testlist;
class type;
var x1-x7;
run;
结果:
一些基本信息:
 以下是对已知分类的数据重分类后的结果:
以下是对已知分类的数据重分类后的结果:

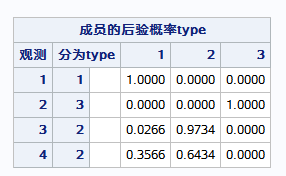
以下是对未知分类数据进行分类的结果:
典型判别分析
即通常的Fisher判别分析。
CANDISC过程
类似于主成分分析,通过数据降维,找一些变量,其为已存在变量的线性组合,使得依据这些变量可以很好地对数据进行分类判别。若要获得完整的判别分析结果,还需要将CANDISC过程的输出结果作为DISCRIM过程的输入,进行一般判别分析。
格式:
proc candisc data=数据集名 outstat=数据集名;
class 变量;
var 变量;
run;
注:
1.proc过程的选项:
a.outstat指定一个数据集,包含典型判别分析各种统计量;
逐步判别分析
思想类似于逐步回归分析
STEPDISC过程
用于在判别分析之前筛选出对数据的判别具有显著影响的变量,凭借这些结果(var var1 ... varm)再使用Discrim过程进行一般判别分析。
格式:
proc stepdisc data=数据集名;
class 分类变量;
var 指标变量; *逐步分析判别中使用的变量;
注:
1.proc stepdisc选项:
a.method:指定筛选变量的方法,包括forward、backward、stepwise;
例
根据下面第一张表对评价等级的判别,对第二张表进行经济发达水平的判别分析。


代码:
data test; /*创建判别分析数据*/
input x1-x5 type;
cards;
195 119 1815 43 28 3
386 12 1908 202 32 1
225 131 1516 115 36 2
369 228 1537 150 21 2
212 240 1851 174 38 2
211 276 2088 248 38 2
208 254 1483 205 32 2
191 116 1552 299 25 3
406 190 1773 288 37 1
12 222 1735 27 30 4
140 66 1931 114 34 3
31 272 1664 69 28 4
314 175 2009 85 39 2
296 193 1636 183 21 2
442 77 1241 24 31 2
;
run;
data test2; /*创建待判别分析的数据集*/
input x1-x5;
cards;
253 169 1910 175 25
186 280 2277 213 37
97 107 2048 89 26
285 200 1914 227 33
332 223 1630 224 21
;
proc stepdisc data=test stepwise;
class type;
var x1-x5;
run;
proc discrim data=test testdata=test2 list testlist;
class type;
var x1 x2 x4;
run;
结果:
先进行stepdisc过程,结果显示x1、x2、x4选入的逐步回归模型:
 以下是根据判别变量x1、x2、x4对未知数据进行分类的结果:
以下是根据判别变量x1、x2、x4对未知数据进行分类的结果:
