前言
在部署大规模深度学习应用的时候,要想满足应用需求或者压榨模型的性能,C++可能是比python更好的选择方案。基于此,特地记录最近的C++的学习经历。其实以终为始来思考为什么学习C++,首先是为了能够很好地提升模型的性能,满足应用场景中的高可用,高并发,低时延等要求。为了提升模型的性能,需要用到一些推理框架,如TensorRT、NCNN或者Openvino(本文中以TensorRT作为案例)。TensorRT在8.0以上的版本都支持Python的API了,但还是有必要学习C++。另外在模型压缩的时候也会考虑用到C++。
确定推理框架后,然后确定这个框架需要什么格式的模型?这里面可能要提到模型集大成者ONNX,因此需要学习ONNX模型。学习如何将Tensorflow、Pytorch或者keras的模型转换成ONNX,它支持什么算子,这些都是需要学习的。
最后总结这个路线是Tensorflow或pytorch模型转换成ONNX,然后ONNX对模型进行优化,转换成TensorRT模型优化以及C++的推理。
- ONNX模型转换和优化
- TensorRT转换和优化
- C++对ONNX模型的推理和TensorRT推理实现。
ONNX
关于ONNX的转换可以参考我的git仓库:onnx模型转换。当中包括Tensorflow和Pytorch的模型转换Demo。同时包括用onnxruntime进行推理的过程。在这一块基本的转换过程已经转换了,后续需要更加深化,了解支持的算子,如何转换复杂模型,甚至如何写算子等都要学会。
C++
C++需要学习基础知识,这些都不在话下了。看下书,学习视频,以下用一个C++调用ONNX模型推理作为例子,具体代码可以参考:ONNX C++。另外发现了一个宝藏博主,可以参考他的系列文章:
- https://blog.csdn.net/qq_34124780/article/details/114666312
- 2021.04.15更新 c++下使用opencv部署yolov5模型 (二)
- 2021.09.02更新说明 c++下使用opencv部署yolov5模型 (三)
- 2021.11.01 c++下 opencv部署yolov5-6.0版本 (四)
- 2022.07.25 C++下使用opencv部署yolov7模型(五)
- 代码
在上面博客中使用的是OpenCV自带的DNN推理框架,有时间比较下各种推理框架的优势与劣势。YOLOX的推理主要完成三个步骤:模型加载、图像预处理以及结果后处理。定义如下的头文件:
ONNX推理头文件:
#include <assert.h>
#include<onnxruntime_cxx_api.h>
#include<ctime>
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/videoio.hpp>
#include <opencv2/highgui.hpp>
class yoloxmodelinference {
public:
yoloxmodelinference(const wchar_t* onnx_model_path);
float* predict_test(std::vector<float>input_tensor_values, int batch_size = 1);
cv::Mat predict(cv::Mat& input_tensor, int batch_size = 1, int index = 0);
std::vector<float> predict(std::vector<float>& input_data, int batch_size = 1, int index = 0);
private:
Ort::Env env;
Ort::Session session;
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*>input_node_names;
std::vector<const char*>output_node_names;
std::vector<int64_t> input_node_dims;
std::vector<int64_t> output_node_dims;
std::size_t num_output_nodes;
std::size_t num_input_nodes;
const int netWidth = 640;
const int netHeight = 640;
const int strideSize = 3;//stride size
float boxThreshold = 0.25;
};
#endif // !yoloxmodel
DNN推理的头文件:
#pragma once
#include<iostream>
#include<opencv2/opencv.hpp>
struct Output {
//类别
int id;
//置信度
float confidence;
//矩形框
cv::Rect box;
};
class YOLO {
public:
YOLO() {
}
~YOLO(){
}
bool initModel(cv::dnn::Net& net, std::string& netPath, bool isCuda);
std::vector<Output>& Detect(cv::Mat& image, cv::dnn::Net& net);
private:
//网络输入的shape
const int netWidth = 640; //ONNX图片输入宽度
const int netHeight = 640; //ONNX图片输入高度
const int strideSize = 3; //stride size
float boxThreshold = 0.25;
float classThreshold = 0.25;
float nmsThreshold = 0.45;
float nmsScoreThreshold = boxThreshold * classThreshold;
};
头文件可以看作是一个“配置文件”,里面声明函数和一些固定的参数。
DNN的读取文件非常简单,如下所示。同时也非常清晰看到DNN是可以使用cuda的。
bool YOLO::initModel(Net& net, string& netPath, bool isCuda)
{
try {
net = readNet(netPath);
}
catch (const exception& e) {
cout << e.what() << std::endl;
return false;
}
//cuda
//if (isCuda) {
// net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
// net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA_FP16);
//}
net.setPreferableBackend(DNN_BACKEND_DEFAULT);
net.setPreferableTarget(DNN_TARGET_CPU);
return true;
}
ONNX会比较麻烦一点,说麻烦一点,其实是没有认真学习当中的API:
yoloxmodelinference::yoloxmodelinference(const wchar_t* onnx_model_path):session(nullptr), env(nullptr) {
//初始化环境,每个进程一个环境,环境保留了线程池和其他状态信息
this->env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "yolox");
//初始化Session选项
Ort::SessionOptions session_options;
session_options.SetInterOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// 创建Session并把模型加载到内存中
this->session = Ort::Session(env, onnx_model_path, session_options);
//输入输出节点数量和名称
this->num_input_nodes = session.GetInputCount();
this->num_output_nodes = session.GetOutputCount();
for (int i = 0; i < this->num_input_nodes; i++)
{
auto input_node_name = session.GetInputName(i, allocator);
this->input_node_names.push_back(input_node_name);
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
this->input_node_dims = tensor_info.GetShape();
}
for (int i = 0; i < this->num_output_nodes; i++)
{
auto output_node_name = session.GetOutputName(i, allocator);
this->output_node_names.push_back(output_node_name);
}
}
接着是图像的预处理,当前参考的是上面博主的代码,存在一个问题是博主用的ONNX模型是torch格式的yolo模型转换得到的,而我的yolo模型是tensorflow格式的。两者的不同点在于前者是[batchsize, channel, width, height],而后者tensortflow是[batchsize, width, height, channel]。因此这是当前需要解决的问题之一。通过搜索一些资料,如change-blobfromimage-dimensions-order,发现原来OpenCV的推理框架对Tensorflow支持不太友好,因此为了解决这个问题,到github上下载官方提供的通过pytorch转换的ONNX模型。
TensorRT
TensorRT支持三种网络的结构和参数:
- TF-TRT,要求的是Tensorflow模型。该API集成在Tensorflow框架当中,开发成本是最小的
- ONNX模型格式,该方法开发周期相对比较短,对用户挺友好
- 使用TensorRT API手动把模型搭建,这是骨灰大神级别的任务操作。
综上第二点是比较经济实惠的,使用ONNX的模型的时候是尚未被优化的,因此需要用TensorRT优化特定的参数,得到TensorRT Engine模型,最后使用该模型进行推理。
(1)使用trtexec.exe
trtexec 是 TensorRT sample 里的一个例子,把 TensorRT 许多方法包装成了一个可执行文件。它可以把模型优化成 TensorRT Engine ,并且填入随机数跑 inference 进行速度测试。命令./trtexec --onnx=model.onnx把 onnx 模型优化成 Engine ,然后多次 inference 后统计并报时。也可以将ONNX模型转换成trt格式的TensorRT模型: /trtexec --onnx=model.onnx --saveEngine=xxx.trt。trtexec作用是看模型最快能跑多快,它是不管精度的,如果真想实际部署上又快又好的模型还是要自己调 TensorRT 的 API。
一般而言,大家写的模型内都是float32的运算,TensorRT 会默认开启 TF32 数据格式,它是截短版本的 FP32,只有 19 bit,保持了 fp16 的精度和 fp32 的指数范围。另外,TensorRT 可以额外指定精度,把模型内的计算转换成 float16 或者 int8 的类型,可以只开一个也可以两个都开,trtexec会倾向于速度最快的方式(有些网络模块不支持 int8)。--best参数,这个参数相当于 --int8 --fp16同时开。
要注意一点的是int8 优化涉及模型量化,需要校准(calibrate)提升精度。TensorRT 有两种量化方法:训练后量化和训练中量化。二者的校准方法不同,精度也不同,后者更高一些。具体参考NVIDIA Deep Learning TensorRT Documentation。
(2)量化校准
这里用的还是训练后校准。逻辑是:搞一些真实输入数据(不需要输出),告诉 TensorRT,它会根据真实输入数据的分布来调整量化的缩放幅度,以最大程度保证精度合适。理论上校准数据越多,精度越高,但实际上不需要太多数据,TensorRT 官方说 500 张图像就足以校准 ImageNet 分类网络。
在这里我觉得要做到这一步校准,首先你得保证你得ONNX模型也是准确的,换言之用训练框架保存的模型转换成ONNX模型应先进行校准。下面就介绍实践教程|实现 PyTorch-ONNX 精度对齐工具。
在把深度学习框架模型转换成中间表示模型后,部署工程师们要做的第一件事就是精度对齐,确保模型的计算结果与之前相当。精度对齐时最常用的方法,就是使用测试集评估一遍中间表示模型,看看模型的评估指标(如准确度、相似度)是否下降。
为了把 PyTorch 和 ONNX 模块对应起来,我们可以使用一种储存了调试信息的自定义算子,如下图所示:
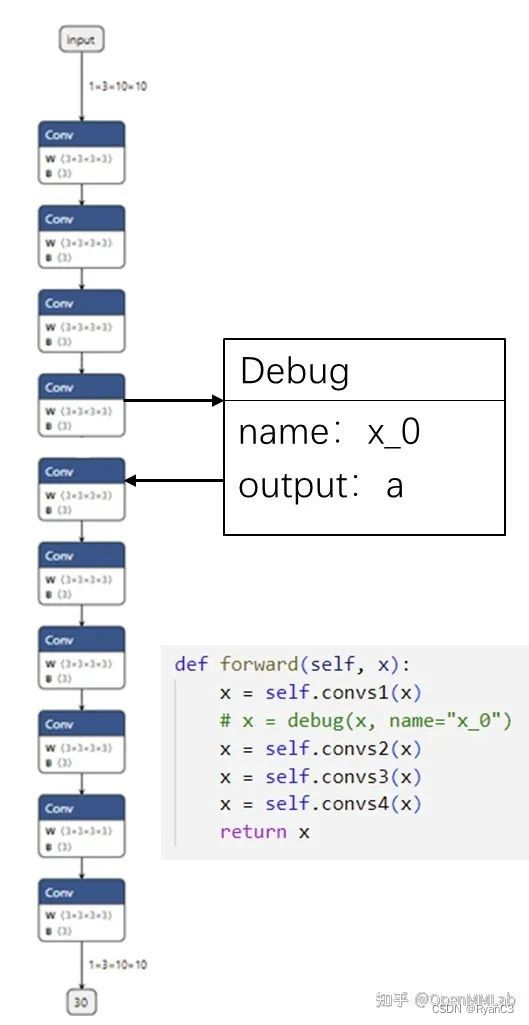
可以定义一个叫做Debug的ONNX算子,它有一个属性调试名name。而由于每一个ONNX算子节点又自带了输出张量的名称,这样一来,ONNX节点的输出名和调试名绑定在了一起。可以顺着PyTorch里的调试名,找到对应ONNX里的输出,完成PyTorch和ONNX的对应。详情可参考原文,原文大致思路是与在Linux上调试一样,写一些print,cout的语句来一个个对比输出结果的差异。同时也可以从尾部出发,一步步向前调试进行优化,查看两者精度的差异。如果发现有差异的算子,就要具体了解到哪一步出现问题,重新编写ONNX模型了。