| 摘要】基于BERT的模型已被广泛应用于文档匹配,但它们通常在长文档的匹配上表现不佳,因为序列长度限制可能导致文档中的信息丢失。此外,长文档的噪声增加会使关键匹配信号的捕获更加复杂。为了解决这些现有问题,我们提出了一种新的长文档匹配模型,EA-BERT。这个模型首先从一对文档中提取一组主题。对于每个主题,我们从两个文档中收集相关句子以形成一个“bag of sentences”,然后由BERT将其编码为包含主题级信息的向量。然后将所有主题向量传递给transformer encoder,以将主题级信息聚合到文档对的文档级匹配结果中。通过这种方式,我们的方法克服了BERT-based模型的序列长度限制,过滤掉了长文档增加的噪声,并整合来自多个主题的匹配信号。实验表明,所提出的方法在中文和英文文档级数据集上均优于当前的长文档匹配模型。 |
1、前言
文本匹配是自然语言应用中的一项重要任务,例如社区问答、信息检索和推荐系统。在短文本匹配问题上已经做了大量工作,主要包括term-based匹配方法和semantic representation-based匹配方法。传统的term-based匹配方法,如TF-IDF和LDA忽略了顺序依赖性和上下文信息。Semantic representation-based匹配方法通过递归/卷积神经网络,或self-attention模块表示整个句子来克服这一限制。
虽然这些提出的匹配方法已经在各个领域有良好表现,但由于以下四个原因,它们不能很好地应用于长文档的匹配。首先,短文本匹配依赖于两个句子之间semantic terms的正确对齐,这对长文档匹配来说是一个挑战,因为较长的文档有更多的组织semantic terms的方式。因此,长文档匹配应该更多地关注全局语义表示而不是单词级别的term alignment。此外,长文档通常包含更多噪音,因为可能包含整句的与其核心主题无关的内容。短文本匹配模型显然无法滤除这种句子级噪声,因为它们只考虑了单词级噪声。第三,使用现有的semantic representation-based匹配模型来处理文本明显较长的长文档需要大量计算,因为它们必须对每个单词和每次交互进行编码和转换。最后,来自基于Transformer的预训练模型的语义表示限制了输入序列的最大长度,例如BERT的512限制,这不可避免地导致长文档中丰富信息的丢失,因为任何超过这个长度的内容都会被截断。虽然bi-encoder结构可以将输入长度加倍,但对于长文档来说仍然不够。最近,像BigBird这样的sparse attention模型可以处理长度高达4096的序列,但同时对模型性能提出了挑战。因此,长文档匹配仍然是一个很大程度上未被探索的领域。
长文档匹配的任务是识别给定的两个文档是否与同一事物相关或描述同一事物。两个文档D1和D2定义为:

其中token表示文档D中的第i个词,n1和n2分别表示两个文档的长度。该问题可以被看作分类任务,其中(D1,D2)被馈送到模型f,并且f(D1,D2)={0,1}被返回,表明它们是否相关。
在这项研究中,我们提出了一种hierarchical transformer-based模型,在计算长文档匹配信号时,以主题相关句子为基本单位。我们首先使用TextRank从文档对中获取一组主题。然后对于每个主题,从两个文档中提取相关句子以形成“bag of sentences”。之后,来自所有主题的所有bag of sentences通过层次模型将主题级别的信息聚合为文档级别的匹配结果。具体来说,每个bag of sentences都由一个通用的BERT encoder进行编码,以获得包含其语义信息的向量。然后将这些特定于主题的向量传递给另一个transformer encoder以捕获主题之间的依赖关系和交互,从而将主题级别的信息聚合为文档级别的信息以进行匹配分类。我们在中文和英文长文本匹配数据集上的实验表明,与目前广泛使用的长文档匹配模型相比,EA-BERT在匹配长文档方面取得了显著改进。我们的工作通过解决序列长度限制问题和有效滤除长文档中的大量噪声做出了贡献。
2、相关工作
在本节中,我们将讨论过去的文本匹配方法,然后讨论一些最近致力于长文本匹配的工作,以更好地理解我们方法的相关性。
2.1 Term-based模型
早期的文档匹配尝试采用term-based的方法。这些方法使用TF-IDF、LDA和BM25等无监督指标来测量一对文本之间的语义距离。尽管这些传统方法可以完成一些基本的单词独立传达信息的匹配任务,但它们不可避免地无法捕获上下文信息。
2.2 深度神经网络模型
因此,将深度神经网络引入文本匹配以更好地编码这些语义依赖性。包括ARC-II、MatchPyramid、CNTN和Match-SRNN在内的方法可有效地通过循环或卷积神经网络表示两段文本的语义匹配模式。然而,尽管这些方法在句子或段落匹配方面取得了成功,但在长文档方面仍然存在不足。
2.3 预训练模型
对长文档的理解应该更多地依赖全局语义表示,同时忽略不相关的句子。因此,文本匹配模型从嘈杂的长文档中过滤和收集有用信息是一个至关重要的挑战。像SMASH模型这样的先驱研究引入了一种带有RNN的分层架构,以将信息从单词级别提取到文档级别。后续工作如SMITH模型集成了BERT预训练模型,进一步增强了其从较长文档中捕获语义信息的能力。其他模型,如TransformerXL、Longformer和BigBird将vanilla Transformer结构扩展为稀疏注意力,以便它们可以直接对超过传统序列长度限制的长文档进行建模。
2.4 Graph-based模型
最近的工作已经开发出更多的方式来表示长文档的核心内容。Concept Interaction Graph使用图结构来提取一对文档的关键概念及其交互,然后将其输入GCN进行文档匹配。另一个工作是Match-Ignition,将PageRank与Transformer相结合,以更好地滤除长文档中的噪音。
以往的工作分别展示了层次结构、主题提取和Transformer模型在长文档匹配中的优势,但没有尝试将它们的优势结合起来。因此,我们有理由相信,使用Transformer聚合主题级信息的层次模型在长文档匹配中具有竞争力。
3、方法
我们提出的模型可以分为三个核心模块:主题提取、主题编码和主题聚合。我们模型的概述如图1所示。

3.1 主题提取
首先,需要从两个文档中提取出关键词。提取方法有多种,本文直接使用TextRank进行关键词提取,采用前c个TextRank结果作为整篇文档的主题。获得一组主题后,两篇文档以句子为单位进行拆分。对于每个主题,我们检查两个文档中的所有句子,并且将收集包含该主题的每个句子以形成该特定主题的“bag of sentences”。对于每个主题��,我们都会有一袋句子��,定义为:

其中S表示文档��中包含关键字��的句子��,如图1左侧所示。
3.2 主题编码
为了从bag of sentences中捕获主题的语义信息,我们利用BERT对其进行编码。给定之前定义的一袋句子K,我们将文档1中的句子和文档2中的句子连接起来,形成两个单词序列。然后我们将这两个单词序列与开头的[CLS]标记、中间的[SEP]标记和末尾的[SEP]标记连接起来作为encoder输入:

其中���������� ��表示Bag of sentences中的第��个token,并且��是Bag of sentences的总序列长度。然后对于每个主题,将上述序列馈送到具有共享参数的共享BERT模块,并返回一系列上下文表示:

其中����表示相应的����������嵌入。我们检索����=��[������]作为主题����的主题级表示。以这种方式处理所有主题后,我们有[��1,��2,...,����]被馈送到聚合步骤.
3.3 主题聚合
编码后,我们得到一组主题级别的上下文信息。但是,由于主题是由模型单独分别处理的,因此不足以得出整个文档的匹配结果。为了捕获文档级匹配信息,使用了一个额外的Transformer encoder来学习主题之间的交互。借助Transformer中的注意力机制,所有主题都会关注其他主题。因此,我们将主题级表示提供给具有6个自注意层的Transformer。原始输入是主题级表示的序列。在任何layer��,我们通过以下方式将主题project到query、key和value:

其中����、����和����是可训练的参数。然后我们执行多头自注意力以获得下一层的输入:

主题����+1的聚合表示被返回并馈送到下一层以进一步聚合。
在训练过程中,注意机制允许每个主题了解所有主题如何为整个文档的匹配做出贡献。从另一个角度来看,如果我们把每个topic看成一个图的节点,这里的transformer encoder就起到了全连接有向图的作用。
3.4 训练目标
在我们的方法中,只有主题编码和主题聚合需要训练。对于用于主题编码的BERT模型,加载预训练模型以通过文档匹配任务进一步微调。我们对用于主题聚合的Transformer Encoder采用随机初始化。通过主题提取、主题编码和主题聚合将输入前馈后,我们使用平均池化和密集层来获得最终的匹配分数。这里采用binary cross-entropy loss作为此文本匹配任务的目标函数:

其中���� hat表示文档对��的匹配分数,����表示对应的ground truth。
4、实验
在本节中,我们将详细介绍数据集、基线模型,并简要说明模型的实现和评估指标。然后我们将分析实验结果,其中包括消融实验。
4.1 数据集
我们对中文和英文数据集进行了实验。详细统计见表1。

4.1.1 中文文档匹配数据集
对于中文文档匹配,我们使用由Liu等人创建的中文新闻相同事件数据集(CNSE)和中文新闻相同故事数据集(CNSS)。这两个数据集是基于来自中国互联网的新闻文章构建的,包括来自各个领域的各种主题。CNSE数据集要求模型识别两篇新闻文章是否报道相同的新闻,而CNSS数据集要求模型识别它们是否属于同一新闻故事。
4.1.2 英文文档匹配数据集
对于英文文档匹配,我们使用引文推荐数据集AAN-Body。AAN-Body基于AAN数据集,其中包含2001年至2014年在ACL上发表的论文。在该数据集中,需要确定一篇研究论文的内容是否与候选引文论文相匹配。
4.2 基线模型
以下三类方法作为基准进行比较:
4.2.1 Term-based模型
我们采用BM25、LDA和SimNet作为三个term-based基线模型。BM25是一种传统的词袋排序函数,广泛应用于信息检索。LDA(Latent Dirichlet Allocation)是一种生成统计模型,用于从一对文档中获取主题建模向量。SimNet首先计算几个文本对相似度,然后使用多层神经网络对匹配结果进行分类。
4.2.2 深度神经网络模型
我们将我们的模型与深度神经网络模型进行比较,包括C-DSSM、ARC-II、MatchPyramid、DUET、RE2和微调的BERT模型。
4.2.3 层次匹配模型
上述基线模型仅专门用于短文档匹配任务,因此我们还包括为长文档匹配任务设计的层次模型。分层模型采用自下而上的逻辑,其中文档表示为子组件(即句子和单词)的集合。传统的层次模型通常用GRU或RNN表示文本,例如HAN和SMASH。在大规模预训练语言模型(PLM)出现后,研究人员转而使用PLM对分层模型中的文本进行编码,例如MatchBERT、CIG和Match-Ignition。
4.3 实施细节
我们使用PyTorch实现了所有模型,并使用了来自HuggingFace的预训练BERT_base checkpoint。对于所有实验,我们使用具有1e-4权重衰减和2000步warm up的AdamW optimizer。学习率设置为1e-6,batch size为16。对于主题级bag of sentences编码,我们使用了HuggingFace中发布的原始中文BERT模型,并将最大序列长度设置为200。对于文档级主题聚合部分,我们堆叠了6块6-head self-attention作为transformer encoder。我们所有的实验都是在32GBTeslaV100GPU上进行的。
4.4评价指标
准确性(Acc)和F1分数在我们的文档匹配任务中用作评价指标。F1分数计算为精度和召回率之间的harmonic mean。它是用于比较分类器性能的主要评估指标,因为它对不平衡数据集具有鲁棒性。
4.5实验结果
实验结果如表2和表3所示。与SOTA模型(即Match-Ignition)相比,我们的模型实现了与之相当的性能,同时在中文和英文数据集上都优于大多数以前的模型。我们的模型将一对文档输入重组为独立的主题,从而减少了序列长度并以非常低的信息损失过滤了噪声。此外,我们的模型以cross-encoder的方式对文档对进行编码,从而能够学习丰富的语义信息,并通过transformer encoder聚合它们,将主题级信息合成文档级信息。因此,它解决了以前在处理长文本时很常见的分而治之技巧中发现的一些问题。
BERT模型的简单微调无法提供令人满意的结果,这可能是由于序列长度的截断导致大量信息丢失,以及长文档中的大量噪声影响模型性能。因此,我们的模型从长文档中提取主题,以在滤除噪声的同时有效地减少序列长度。我们的模型也优于graph-based模型,即CIG。CIG使用手动选择的特征,如TF-IDF相似性和常用词,这导致缺乏学习的语义信息。尽管CIG将BERT合并到最终匹配向量中以向模型添加语义信息,但它对性能的提升有限,因为来自BERT的语义信息不会在顶点之间流动。
与Match-Ignition相比,我们展示了可比较的结果,Match-Ignition类似于我们的方法,在建模文档时采用了分层分而治之的哲学。但是,Match-Ignition添加了来自文档标题的额外信息,这可能会限制其在文档标题不可用的极端情况下的鲁棒性。

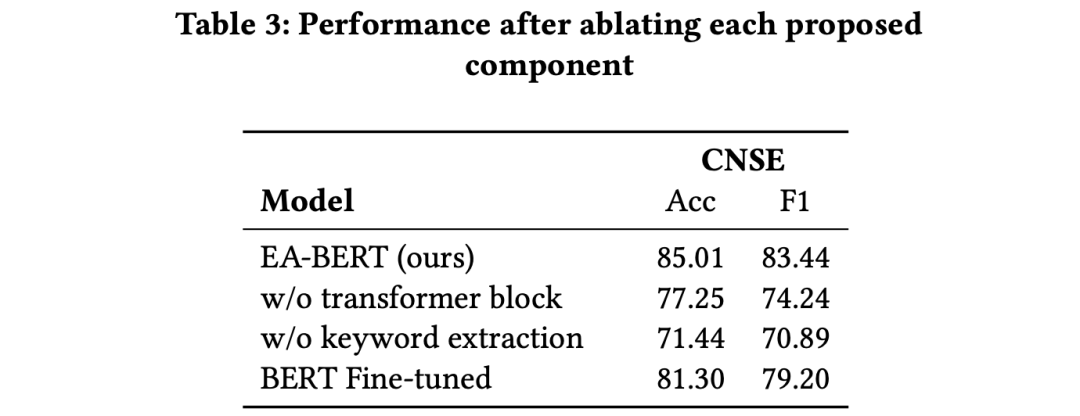
4.6 消融实验
我们对CNSE数据集进行消融实验。结果如表3所示。我们首先删除主题提取部分:现在单个句子成为主题。主题级别的匹配信息就丢失后,准确率和F1score从85.01%/83.44%下降到71.44%/69.89%。然后,我们用mean-pooling替换模型文档级部分中的self-attention。结果,匹配性能显示出大约8%的巨大下降。因此,删除任何一部分都会导致性能显着下降,这再次反映了在长文档匹配任务中对主题进行聚类信息并捕获它们之间的交互的重要性。
5、结论
在本文中,我们提出了EA-BERT通过学习文档的主题级表示并将它们聚合以获得文档级信息来解决长文档匹配问题。我们提出的方法在中文和英文数据集上明显优于以前广泛使用的文本匹配方法。消融实验展示了我们模型的主题提取和聚合的必要性。在未来的工作中,我们计划深入研究更细粒度的主题提取方法,甚至实现与匹配过程一起学习的主题提取算法。
关于华院计算
华院计算技术(上海)股份有限公司(简称“华院计算”),成立于2002年,以算法研究和创新应用为核心、专注于认知智能技术的研究、应用和开发。公司基于数学应用与计算技术发展,聚焦认知智能技术、创新自研底层算法;基于认知智能引擎平台的场景应用,为数字治理、智能制造、数字文旅、零售金融 等行业提供AI+行业解决方案、实现全面赋能,从而推动行业智能化的转型和升级,让世界更智慧。
作者:蔡华、胡景熙,马任,陆逸骁,徐清
翻译:陆逸骁
参考文献:
[1] Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The LongDocument Transformer. arXiv: Computation and Language (2020).
[2] David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2001. Latent Dirichlet Allocation. Journal of Machine Learning Research (2001).
[3] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. 2019. TransformerXL: Attentive Language Models beyond a FixedLength Context. ACL (2019), 2978–2988.
[4] Baotian Hu, Zhengdong Lu, Hang Li, and Qingcai Chen. 2014. Convolutional Neural Network Architectures for Matching Natural Language Sentences. neural information processing systems (2014).
[5] PoSen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. CIKM (2013).
[6] JyunYu Jiang, Mingyang Zhang, Cheng Li, Michael Bendersky, Nadav Golbandi, and Marc Najork. 2019. Semantic Text Matching for LongForm Documents. The world wide web conference (2019), 795–806.
[7] Jacob Devlin MingWei Chang Kenton and Lee Kristina Toutanova. 2019. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding. NAACL (2019), 4171–4186.
[8] Bang Liu, Di Niu, Haojie Wei, Jinghong Lin, Yancheng He, Kunfeng Lai, and Yu Xu. 2018. Matching Article Pairs with Graphical Decomposition and Convolutions. ACL (2018).
[9] Rada Mihalcea and Paul Tarau. 2004. Textrank: Bringing order into text. EMNLP, 404–411.
[10] Bhaskar Mitra, Fernando Diaz, and Nick Craswell. 2017. Learning to match using local and distributed representations of text for web search. In Proceedings of the 26th international conference on world wide web. 1291–1299.
[11] Liang Pang, Yanyan Lan, and Xueqi Cheng. 2021. MatchIgnition: Plugging PageRank into Transformer for Long-form Text Matching. CIKM (2021).
[12] Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Shengxian Wan, and Xueqi Cheng. 2016. Text matching as image recognition. AAAI 30, 1 (2016).
[13] Xipeng Qiu and Xuanjing Huang. 2015. Convolutional neural tensor network architecture for community-based question answering. International conference on artificial intelligence (2015).
[14] Dragomir R Radev, Pradeep Muthukrishnan, Vahed Qazvinian, and Amjad Abu-Jbara. 2013. The ACL anthology network corpus. Language Resources and Evaluation 47, 4 (2013), 919–944.
[15] Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP (2019).
[16] Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval (2009).
[17] Yelong Shen, Xiaodong He, Jianfeng Gao, Li Deng, and Grégoire Mesnil. 2014. A latent semantic model with convolutional-pooling structure for information retrieval. CIKM, 101–110.
[18] Shengxian Wan, Yanyan Lan, Jiafeng Guo, Jun Xu, Liang Pang, and Xueqi Cheng. 2016. A deep architecture for semantic matching with multiple positional sentence representations. AAAI 30, 1.
[19] Zhiguo Wang, Wael Hamza, and Radu Florian. 2017. Bilateral multierspective matching for natural language sentences. (2017), 4144–4150.
[20] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Computational Linguistics, Online, 38–45.
[21] Liu Yang, Mingyang Zhang, Cheng Li, Michael Bendersky, and Marc Najork. 2020. Beyond 512 Tokens: Siamese Multidepth Transformerbased Hierarchical Encoder for Longorm Document Matching. CIKM (2020).
[22] Runqi Yang, Jianhai Zhang, Xing Gao, Feng Ji, and Haiqing Chen. 2019. Simple and Effective Text Matching with Richer Alignment Features. ACL (2019), 4699–4709.
[23] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies. 1480–1489.
[24] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontañón, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for Longer Sequences. NeurIPS (2020).
[25] Xuhui Zhou, Nikolaos Pappas, and Noah A Smith. 2020. Multilevel Text Alignment with Cross-Document Attention. EMNLP (2020), 5012–5025