DOM
DOM(document object model)即文档对象模型 , 是W3C制定的标准接口规范 。HTML文档被解析后, 转化为DOM树, 树的每个结点是一个对象。DOM模型不仅描述了文档的结构, 还定义了结点对象的行为, 利用对象的方法和属性, 可以方便地访问、修改、添加和删除DOM树的结点和内容。
STU
STU(SemanticTextualUnit)即语义文本单元,每个STU对应一个块,STU嵌套构成STU树。STU树模型扩展了STU模型,具有强大的语义描述能力。由于STU树模型具有与源HTML网页相对应的树状结构,利用HTML与DOM树的映射关系,可以将STU树与DOM树结合:向DOM树的某些结点添加描述语义的属性,生成的DOM树称为STU-DOM树,树中具有语义属性的结点称为STU结点。这样,STU-DOM树兼有DOM树和STU树的结构和语义,避免了使用额外的存储空间,简化了处理流程,而且使提取后的网页具有与源网页一致的结构和内容,可靠性和可扩展性较高。
HTML解析器
解析器(HTMLparser)将HTML文档转化为DOM树。过滤器(filter)从DOM树中删除无关结点。分块器(partitioner)向STU结点添加语义属性,将DOM树转化为STU-DOM树,语义属性值由语义分析器(semanticanalyser)计算。剪枝器(pruner)从STU-DOM树中删除无关链接列表和没有内容的块,最后输出只含有主题信息的HTML文档。
过滤和分块
过滤和分块是将DOM树转化为STU-DOM树的过程。过滤器从DOM树的根结点开始,递归地遍历DOM树,删除所有无关结点,遇到分块结点时调用分块器,向该结点添加语义属性,使该结点成为STU结点,当STU结点的语义属性值满足剪枝条件时,调用剪枝器处理该结点。
无关结点通常是图片(IMG)、脚本(SCRIPT)等,无关结点的标签列表是系统配置的一部分。分块结点决定了分块的粒度,分块粒度过粗或过细都将导致抽取结果不完整或保留多余信息。经多次实验分析,用TABLE和TD标签结点作为分块结点,其语义属性是contentlength和linkcount,属性值由语义分析器计算。
语义分析算法
本文算法采用的语义信息是块中非链接文字总数(字符数)和链接总数,在STU-DOM中对应子树中的非链接文字总数和链接总数,分别用contentlength和linkcount属性表示。非链接文字指不在链接上的文字,一个块的非链接文字总数可以代表它的内容。STU-DOM树中,标记了STU结点的语义属性值,W表示非链接文字总数,L表示链接总数。
该策略基于对HTML网页的抽样分析结果,经分析发现与主题无关的块总是含有大量无关链接和极少非链接文字,特殊情况是正文中的链接列表块,但这样的块总是位于另一个内容丰富的块中。这一规律运用到STU-DOM树模型中很有指导意义。我们利用这一特征计算主题相关度。
一个STU-DOM结点的主题相关度表示该结点与HTML文档主题的关联程度。主题相关度含两部分:局部相关度(localcorrelativity)和上下文相关度(contextualcorrelativity)。
局部相关度由块内链接和内容决定,其计算公式可以表达为

其中,STUCij表示STUi的第j个子树,LinkCount(STUi)是STUi的linkcount属性值,用其所有子树中的链接数之和计算,ContentLength(STUi)是STUi的contentlength属性值,用其所有子树中的非链接文字的字符数之和计算。
上下文相关度由块内链接和父块内容决定,其计算公式可以表达为
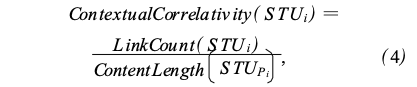
其中,STUPi表示STUi的父STU结点,在STU-DOM树中是具有语义属性的最近祖先结点。
语义分析器用上述算法对STU结点进行上下文语义分析,计算contentlength和linkcount属性值。
剪枝算法
局部相关度阙值为LCm,如果LocalCorrelativity(STUi)≥LCm,称为STUi局部相关。上下文相关度阙值为CCm,如果ContextualCorrelativity(STUi)≥CCm,称为STUi上下文相关。如果STUi既不局部相关又不上下文相关,即LocalCorrelativity(STUi)<LCmANDContextualCorrelativity(STUi)<CCm,则称STUi主题无关。
规定STU结点的非链接文字至少为Cm个字符,即contentlength≥Cm;如果contentlength<Cm,称STU为空或没有内容。剪枝器判断STU结点是否主题无关,是则删除其所有子树中的链接,并修改它的语义属性值contentlength和linkcount。如果一个STU为空,即contentlength<Cm,则删除该结点。根据这一算法,可以删除无关链接列表和没有内容的块。
